






Contrastive Representation Learning: A Framework and Review [Paper]
Phuc H. Le-Khac, Graham Healy, Alan F. Smeaton ML-Labs, Dublin City University 10 Oct 2020
Interview를 보았는데 Contrastive learning에 대한 질문을 받았다. SimCLR로 간접적으로 설명하긴 했는데 내가 생각해도 형편없는 답변을 했다. 대학원 시절 랩실에서 가장 먼저 읽어서 랩세미나 시간에 발표하기도 했는데 너무 당연하다고 생각해오고 모델을 가져다가 쓰기만 하다보니 정작 말로 설명을 못하는 느낌이 들어 이번 주는 Contrastive learning 분야를 파면서 대표 논문 review를 진행하려고 한다. Facenet에서 triplet loss를 접하고 흥미 있는 분야로 생각했는데 self-supervised learning 분야에서 많이 발전을 이룬 것 같다.
Introduction
Contrastive Learning(CRL)이란 입력 샘플 간의 비교를 통해 학습을 하는 것이다. CRL의 경우에는 self-supervised learning에 사용되는 접근법 중 하나(물론 supervised learning의 맥락에서 CRL이 수행되기도 한다)로 사전에 정답 데이터를 구축하지 않는 판별 모델이라고 할 수 있다.
따라서, 데이터 구축 비용이 들지 않음과 동시에 학습 과정에 있어서 보다 용이한 장점을 갖는다. 이러한 데이터 구축 비용 이외에도 label이 없기 때문에 보다 일반적인 feature representation과 새로운 class가 들어와도 대응이 가능 하다는 장점이 추가적으로 존재한다.
이후 classification 등 다양한 downstream task에 대해서 네트워크를 fine-tuning 시키는 방향으로 활용하곤 한다.
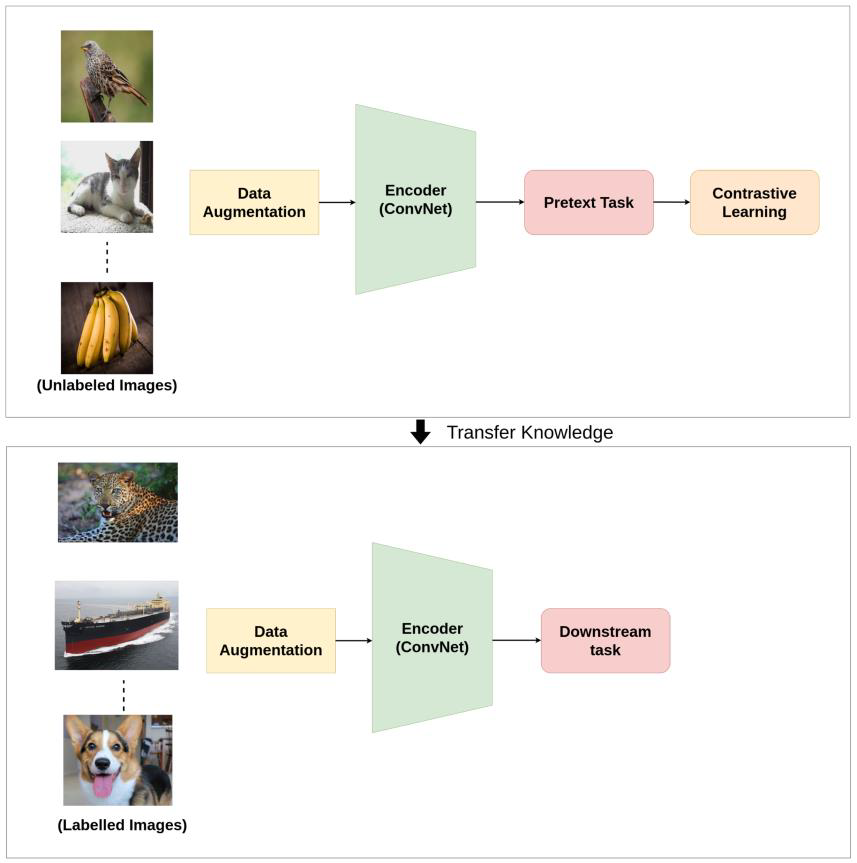
Contrastive Representation Learning
Representation Learning은 크게 2가지 접근법이 존재한다. 하나는 생성모델의 측면 나머지는 판별모델의 측면이다. 생성모델로 데이터의 표현을 학습하는 경우, 비지도 학습이기 때문에 데이터 구축 비용이 낮다는 장점이 있다. 또한 저차원 표현을 학습하는 데 있어 목적함수가 보다 일반적이라는 장점이 있다.
판별모델의 경우에는 계산 비용이 적고, 학습이 용이하다는 장점이 있다. 대부분 라벨링된 데이터에 의존하기 때문에 데이터 구축 비용이 크다는 단점이 있습니다. 판별 모델의 경우 데이터가 속한 클래스를 판별하는 목적을 지녔기 때문에, 보다 지엽적인 목적함수라고 할 수 있다. 실제로 판별모델을 학습하는 과정 중에 학습되는 representation은 texture에 보다 집중을 한다는 주장을 하는 논문 또한 발표되었다.
CRL도 representation learning을 수행하기 위한 하나의 방법이다. CRL은 앞서 말했듯이 입력 샘플 간의 비교를 통해 학습한다. 따라서, 목적은 심플하다. 학습된 표현 공간 상에서 비슷한 데이터는 가깝게, 다른 데이터는 멀게 존재하도록 표현 공간을 학습하는 것이다.
여러 입력쌍에 대해서 유사도를 label로 판별 모델을 학습한다. 이때 유사함의 여부는 데이터 자체로부터 정의 될 수 있다. 즉 self-supervised learning이 가능하다.
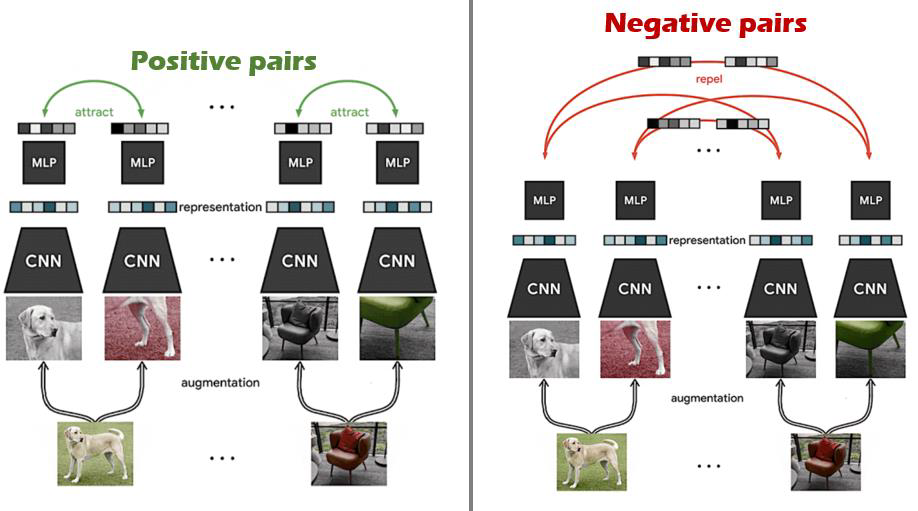
Contrastive 방법의 경우, 다른 task로 fine-tuning을 수행할 때에 모델 구조 수정 없이 이루어 질 수 있다는 점에서 훨씬 간편하다.
CRL architecture의 하나인 Instance Discrimination Task (IDT)에 대해 설명을 하면 Unsupervised Feature Learning via Non-Parametric Instance Discrimination(Zhirong Wu et al., 2018)에서 처음 제안되었다.
IDT의 경우, Fig 3과 같이 네트웨크가 구성되고, 하나의 sample에서 두 가지의 view가 생성됨을 알 수 있다. 이때, 같은 이미지에서 나온(같은 인덱스에 위치한) pair는 무조건 positive pair이고, 그를 제외한 다른 인덱스 내의 view와는 모두 negative이다. pair의 구성은 다음과 같이 이루어진다.
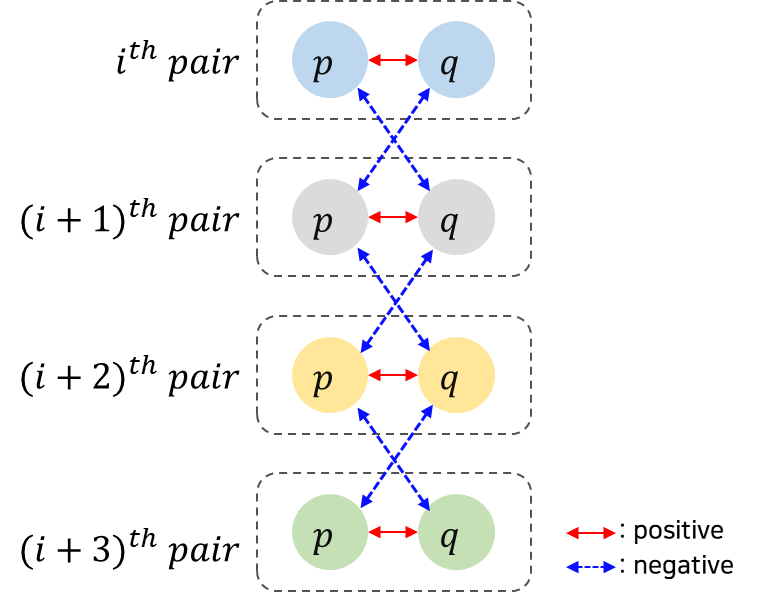
Instance discrimination을 위한 contrastive learning의 architecture는 다음과 같이 구성된다.
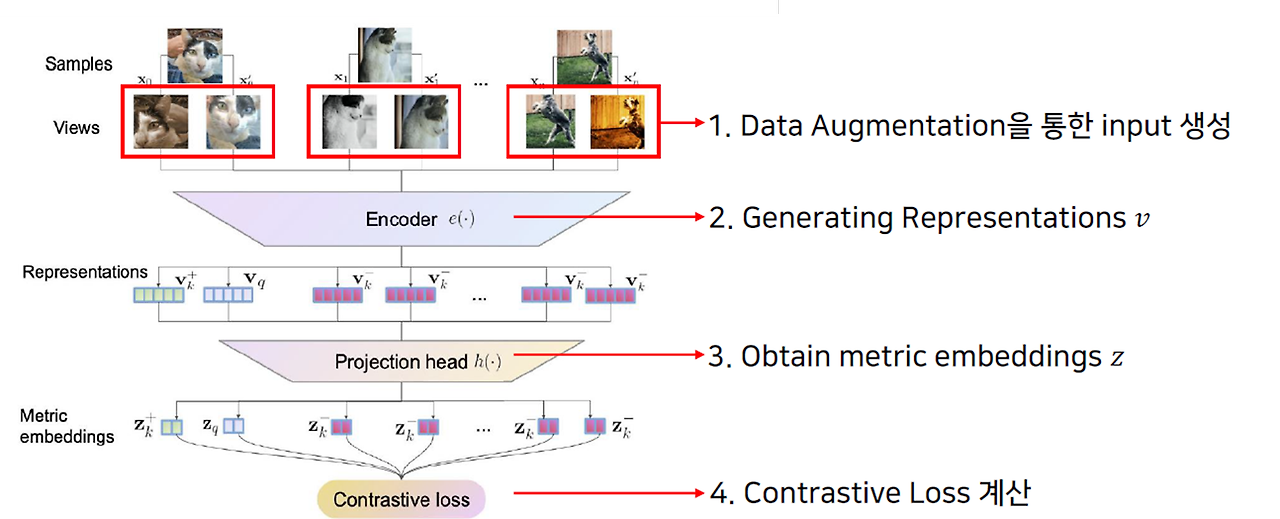
1. Data Augmentation을 통한 input pair 생성
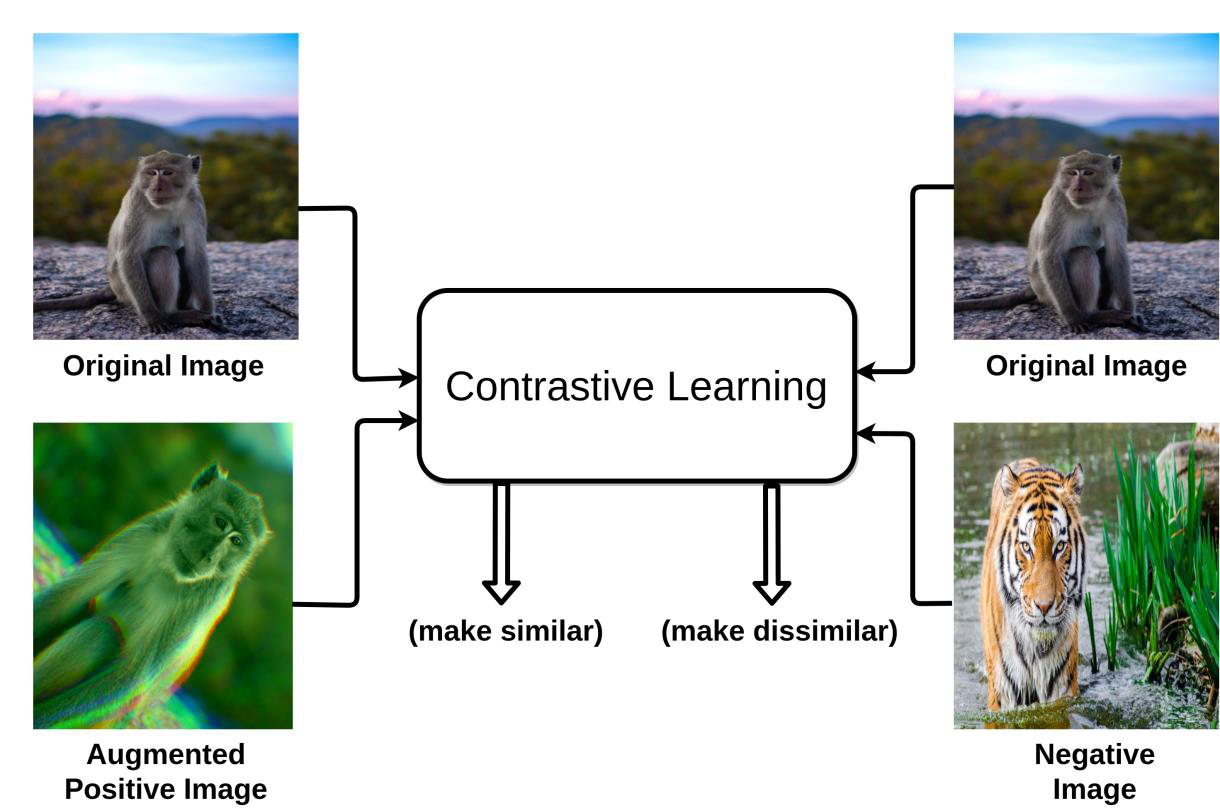
같은 이미지에서 생성되었다면 positive pair이고, pair 내 두 이미지가 다른 이미지로부터 나왔다면 negative pair이다. Positive pair를 구성할 때는 원본 이미지에서 image transformation을 적용한 augmented image를 구성하여 pair를 구성하게 된다. 이때, augmentation (transformation)은 random crop, resizing, blur, color distortion, perspective distortion 등을 포함한다.

2. Generating Representation (= Feature Extraction)
입력 이미지 쌍을 생성했다면, 해당 이미지 쌍으로 representation을 학습(즉, 특징 추출)해야 한다.
Contrastive learning network 내에서 이와 같은 부분을 feature encoder $e$라고 부르며,
$e$는 아래와 같이 특징 벡터 $v$를 출력하는 함수로 표현할 수 있다.
Encoder의 구조는 특정되지 않으며, 어떤 backbone network든 사용할 수 있습니다. 참고로 InstDisc에서는 ResNet 18을 사용했다.
3. Projection Head
projection head $h(\cdot)$에서는 encoder에서 얻은 특징 벡터 $v$를 더 작은 차원으로 줄이는 작업을 수행한다.
간혹 여러 representation을 결합하는 방식으로 projection을 수행하기도 하는데, 이 경우에는 contextualization head라고도 지칭한다. 그러나 InstDisc에서의 projection head는 2048차원의 특징 벡터 $v$를 128차원의 metric embedding $z$로 projection하여, 즉 차원 축소를 수행하는 용도로 사용된다.
이때, projection head $h$는 다음과 같이 metric embedding $z$를 출력하는 함수로 표현될 수 있습니다.
\[h(\cdot) \rightarrow z = h(v), \quad z \in \mathbb{R}^{'}, \quad d' < d\]Projection head의 경우엔 간단한 MLP 구조를 갖는다. 이후 unit vector로 정규화해준다.
metric embedding
Contrastive loss는 기본적으로 각 pair의 유사도를 측정한다. 이러한 유사도가 거리가 될 수도 있고, pair가 공유하는 entropy로 계산이 될 수도 있다. 즉, 유사도는 metric으로 나타낼 수 있고 이에 loss에 input으로 들어가는 z를 metric embedding이라고 표현하는 것이다. project head 내에서 feature representation space에서 metric representation space로 projection했다고 볼 수 있다.
4. Loss 계산
CRL의 목적(objective)은 positive pair의 embedding은 가깝게, negative pair의 embedding은 멀게하는 것이라고 말했는데 loss는 이러한 objective를 직접적으로 수행한다. 이를 contrastive loss로 부른다. Contrastive loss와 같은 경우에는 infoNCE, NTXent등이 많이 사용되고 있다.
$i$번째 입력쌍에 대한 Loss의 일반항 \(L = -\log \frac{\exp(z_i^T z'_i / \tau)}{\sum_{j=0}^{K} \exp(z_i^T z'_j / \tau)}\)
- $z_i^T z’_i$: 두 벡터 $z, z’$의 내적. 여기서 $z’$는 $z$의 변형(transformation; augmented $z$).
- $\tau$: 하이퍼파라미터로, 두 벡터 간의 내적이 전체 loss에 어느 정도 영향을 미치는지 조절.
- 분모의 합($\sum$): $z_i$에 대해 하나의 positive pair와 $K$개의 negative pair를 포함하여 계산.
5. 학습 완료 후
네트워크가 학습이 완료된 후에는 projection head 이후부터는 버리고 encoder만 transfer learning을 위한 feature extactor로 사용된다. 이후 predictor를 뒤에 결합하여 새로운 task에 적용할 수 있도록 fine-tuning을 거치게 된다. pretext-downstream task 구조를 갖는다. Fig 4. 를 보면 알 수 있듯이 CRL은 어떤 augmentation을 적용하는냐가 모델 성능에 큰 영향을 미치게 된다. 색상, 형태, edge등 low-level의 시각적 단서에서만 네트워크가 의존하여 표현을 학습하지 않도록, 이미지 전체가 담고 있는 추상적인 의미(image semantic)를 잘 파악할 수 있도록 다양한, 그러나 image semantic을 변화시키지 않는 augmentation을 적용하여 입력 이미지 페어를 구성하는 것이 중요하다.
6. 용어 정리
contrastive learning framework에서는 input pair 생성, encoder, projection head, loss 등 여러 모듈이 있음. 여기서 survey paper에서 사용되는 용어나 개념들을 정리해봄.
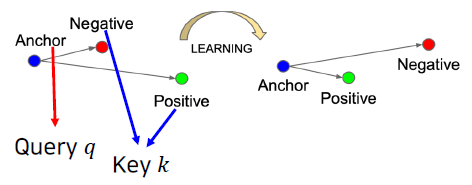
1. Query, Key
기준 벡터와 비교 벡터를 query, key라고 부름. 벡터라는 표현은 이미지, representation, metric embedding을 모두 아우르는 말임.
2. Similarity Distribution
입력 샘플 쌍의 결합 분포를 이렇게 표현함:
\[p^+(q, k^+)\]key를 similarity distribution(query와 비슷한 샘플들의 분포)에서 뽑으면 $k = k^+$, dissimilarity distribution(query와 비슷하지 않은 샘플들의 분포)에서 뽑으면 $k = k^-$가 됨.
실제 학습에서는 distribution을 직접 가정한다기보다는 input pair를 어떻게 구성할지 결정하는 게 더 중요함. 예를 들어, InstDisc에서는 같은 이미지에서 augmented되면 positive, 다른 이미지에서 augmented되면 negative로 정의했음. 어떤 pair를 positive로, 어떤 pair를 negative로 구성할지 정하는 게 핵심임.
3. Model
파라미터(네트워크 가중치 등)가 있는 모든 모듈을 통칭해서 모델이라고 부름. 이렇게 표현할 수 있음:
\[f(x; \theta) : X \rightarrow \mathbb{R}^{|Z|}\]| 여기서, input space $X$에서 metric embedding $ | Z | $ 차원의 실수 공간 $\mathbb{R}^{ | Z | }$로 매핑하는 함수 $f$를 의미함. 보통 encoder랑 transform head로 나눠서 설명함. |
4. Encoder
입력 view를 representation vector로 매핑하는 부분임. encoder가 학습한 representation은 다른 모델의 입력으로 쓰거나(freeze), encoder 위에 layer를 추가해서 fine-tuning 할 때 활용하기도 함.
5. Transform Head
feature embedding $v$를 metric embedding $z$로 변환하는 모듈임. 여러 representation을 결합하거나 contrastive loss에 넣기 전에 차원을 줄이는 데 씀.
6. Contrastive Loss
query, positive key, negative key로 구성된 metric embedding 쌍 ${(z, z^+), (z, z^-)}$에 적용됨.
- embedding 간 유사도를 측정하고, positive pair의 유사도는 높이고, negative pair의 유사도는 낮추는 역할을 함.
- 유사도를 측정하는 scoring function과 loss의 형태(cross entropy, distance-based loss 등)로 나눌 수 있음.
학습된 representation은 positive pairs에서 trivial noise에는 invariant하고, negative pair의 차이를 설명하는 covariant representation을 잘 반영해야 함.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)