






arXiv 2023. [Paper] [Page] [Github]
Axel Sauer, Katja Schwarz, Andreas Geiger
University of Tübingen and Max Planck Institute for Intelligent Systems
1 Feb 2022

Introduction
Computer graphics has long been interested in generating high-resolution, photorealistic images whose semantic properties can be directly controlled. Until recently, the main paradigm was to create carefully designed 3D models and then render them using photorealistic camera and lighting models. Other studies approach the problem from a data-driven perspective. In particular, the stochastic generative model has shifted the paradigm from asset design to learning procedure and dataset design.
StyleGAN is one such model and exhibits many desirable properties. StyleGAN achieves high image fidelity, fine-grained semantic control and, more recently, alias-free generation enabling photorealistic animation. It also reaches impressive photorealism on carefully curated datasets, especially human faces. However, when training on large, unstructured datasets such as ImageNet, StyleGAN still does not yield satisfactory results. Another problem that usually plagues data-driven methods is that larger models are required, making them prohibitively expensive when scaled up to higher resolutions.
Initially, StyleGAN was proposed to allow for better control and interpolation quality by explicitly separating the variance factors. However, it is more limited than standard generator networks, which are expensive when training complex and diverse datasets such as ImageNet. Previous attempts to extend StyleGAN and StyleGAN2 to ImageNet have led to subpar results, leading us to believe that they may be fundamentally limited for very diverse datasets.
BigGAN is a state-of-the-art GAN model for image synthesis on ImageNet. A major factor in BigGAN’s success is its larger batch and model size. However, BigGAN has not reached a position similar to StyleGAN because its performance varies greatly from training to training and it does not use an intermediate latent space, which is essential for GAN-based image editing. Recently, BigGAN has been replaced by diffusion model in terms of performance. Diffusion model achieves more diverse image synthesis than GAN, but its inference is considerably slower and previous studies on GAN-based editing cannot be directly applied. Therefore, successfully training StyleGAN on ImageNet has several advantages over existing methods.
Previous unsuccessful attempts to extend StyleGAN raise the question of whether architectural constraints fundamentally limit style-based generators, or whether what is missing is the correct learning strategy. In a recent study, we introduced a projected GAN that projects generated and real samples onto a pre-trained fixed feature space. Changing the GAN settings in this way significantly improves training stability, training time, and data efficiency.
Taking advantage of projected GAN training, StyleGAN can be extended to ImageNet. However, the advantages of Projected GANs only partially extend to StyleGANs on unimodal datasets. The authors study this problem and propose architectural changes to address it. Then, a progressive growing strategy suitable for the latest StyleGAN3 is designed. Together with Projected GAN, these changes have outperformed previous attempts to train StyleGANs on ImageNet. To further improve their results, the authors analyzed the pre-trained feature networks used in Projected GANs and found that using CNNs and ViTs together significantly improved performance. Finally, we utilize classifier guidance, a technique originally introduced in diffusion models, to inject additional class information.
Scaling StyleGAN to ImageNet
StyleGAN has several advantages over existing approaches that work well on ImageNet. However, naive learning strategies do not achieve state-of-the-art performance. The authors experimentally confirmed that even the state-of-the-art StyleGAN3 does not scale well. Especially at high resolution, learning becomes unstable. Therefore, the goal of this paper is to successfully train StyleGAN3 generator on ImageNet. The model in this paper is called StyleGAN-XL (refer to the figure below).
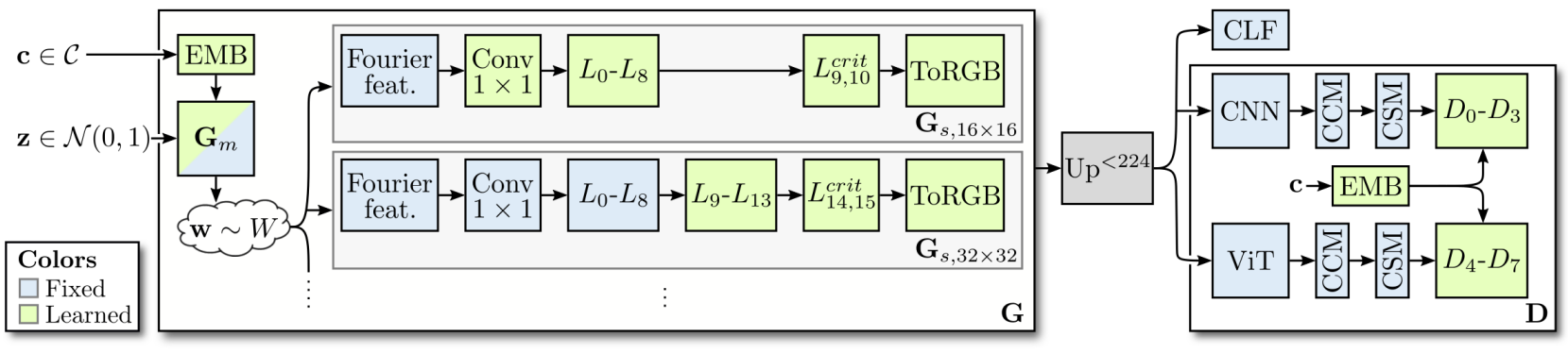
1. Adapting Regularization and Architectures
Training on different class conditional datasets requires introducing some tweaks to the standard StyleGAN construction. A generator architecture is constructed using the StyleGAN3-T layer, a translational-equivariant of StyleGAN3. In initial experiments, the authors found that the rotational-equivariant StyleGAN3-R produced overly symmetrical images in more complex datasets, resulting in kaleidoscope-like patterns.
Regularization
In GAN training, it is common to use regularization on both the generator and discriminator. While regularization improves results on unimodal datasets like FFHQ or LSUN, it can be detrimental on multi-modal datasets. Therefore, we aim to avoid normalization where possible. In the latest StyleGAN3, we found that style mixing is unnecessary. Therefore, StyleGAN-XL also disables style mixing.
Path length regularization can lead to poor results on complex datasets and is disabled in StyleGAN3 by default. However, path length regularization is attractive because it enables high-quality inversion. Also, the authors observed unstable behavior and divergence when using path length regularization in practice. The authors circumvented this problem by applying regularization only after the model had been sufficiently trained, i.e. after 200,000 images.
For Discriminator, Spectral Normalization is used without Gradient Penalty. We also blur all images with a Gaussian filter with $\sigma = 2$ pixels for the first 200,000 images. Discriminator blurring was introduced in StyleGAN3-R, which prevented the discriminator from initially focusing on high frequencies, which was found to be beneficial in all settings investigated by the authors.
Low-Dimensional Latent Space
Projected GAN works better with FastGAN than StyleGAN. One major difference between these generators is latent space. StyleGAN’s latent space is relatively high-dimensional (FastGAN: $\mathbb{R}^{100}$, BigGAN: $\mathbb{R}^{128}$, StyleGAN: $\mathbb{R}^{512} $). Recent work has shown that the eigendimensionality of natural image datasets is relatively low, with ImageNet’s estimate of dimensionality being around 40. Therefore, the latent code of size 512 is highly redundant, making mapping networks more difficult at the beginning of training. As a result, generators are slow to adapt and cannot benefit from the speedup of Projected GANs. Therefore, reducing the dimension of StyleGAN’s latent code $z$ to 64 and combining it with Projected GAN results in stable learning. In order not to limit the model capacity of the mapping network $G_m$, the original dimension of the style code $w \in \mathbb{R}^{512}$ is kept.
Pretrained Class Embeddings
Tuning the model according to the class information is essential to control the sample class and improve the overall performance. A class conditional version of StyleGAN was first proposed in CIFAR10 where one-hot encoding labels are included in a 512-dimensional vector and concatenated with $z$. In the case of a discriminator, class information is projected onto the last discriminator layer. This produces samples of similar high quality for each class. The authors assume that class embedding breaks down when training with Projected GANs. Therefore, to prevent this collapse, we aim to facilitate embedding optimization through pre-learning.
Extract the lowest resolution features of Efficientnet-lite0, spatially pool them, and compute averages per ImageNet class. The network has a small number of channels to keep the embedding dimension small. The embedding is passed through a linear projection to match the size of $z$ to avoid imbalance. Both $G_m$ and $D_i$ are conditioned by embedding. During GAN training, embeddings and linear projections are optimized to enable specialization. With this configuration, the model produces multiple samples per class and recall increases.
2. Reintroducing Progressive Growing
For fast and stable learning, a method of gradually increasing the output resolution of the GAN was introduced. The original formula adds layers to both $G$ and $D$ during training, and the contribution gradually fades away. However, it was discarded in later studies as it may contribute to texture sticking artifacts. According to a recent study, the main cause of these artifacts is aliasing, so each layer of StyleGAN is redesigned to prevent it. This motivated me to re-apply progressive growing with a carefully crafted strategy aimed at suppressing aliasing as much as possible. By first training at very low resolutions, as small as $16^2$ pixels, we can break the difficult training into smaller subtasks on high-resolution ImageNet. This idea is consistent with recent research on the diffusion model. Diffusion models showed significant improvements in FID on ImageNet using a two-step model stacking an independent low-resolution model and an upsampling model to generate the final image.
In general, GANs follow a strict sampling rate progression. That is, at each resolution, there is a fixed amount of layers followed by an upsampling operation using fixed filter parameters. StyleGAN3 does not follow this progression. Instead, the number of layers is set to 14 regardless of the output resolution, and the filter parameters of the up/downsampling operations are carefully designed for antialiasing in a given configuration. The last two layers are critically sampled to create high frequency detail. When adding a layer, it is important to discard the previously significant sampled layer as it will cause aliasing if used as an intermediate layer. It also adjusts the filter parameters of the added layer to comply with the flexible layer specification. In contrast, we don’t add layers to the discriminator. Instead, we upsample both the data and synthetic images to a training resolution of F (224^2 pixels) when training smaller images to fully exploit the pre-trained feature network F.
Start progressive growing at a resolution of $16^2$ using 11 layers. Each time the resolution increases, 2 layers are discarded and 7 new layers are added. Empirically, the smaller the number of layers, the lower the performance. In the final step ($1024^2$), we only add 5 layers because we don’t discard the last two. At the maximum resolution of $1024^2$, it has 39 layers. Instead of a fixed growing schedule, each step is learned until the FID stops decreasing. At higher resolutions, a smaller batch size is sufficient ($64^2 to $256^2: 256, $512^2 to $1024^2: 128). When a new layer is added, the low resolution layer is fixed to prevent mode collapse.
3. Exploiting Multiple Feature Networks
In an ablation study of Projected GANs, we found that most of the pre-trained feature networks F perform similarly in terms of FID when used for Projected GAN training, regardless of the training data, pre-training objective function, and network architecture. However, the advantage of combining multiple $F$ was not addressed in the ablation study.
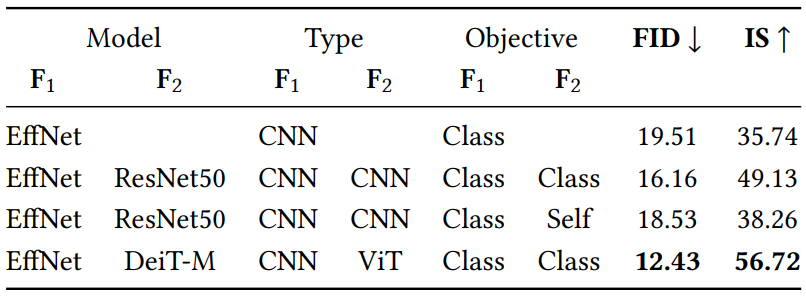
Starting from the standard configuration, EfficientNet-lite0, we add a second $F$ to check the influence of the pretraining objective function (classification or self-supervision), architecture (CNN or Vision Transformer (ViT)). The results in the table above show that adding a CNN slightly lowers the FID. Combining networks with different pretraining objective functions has no advantage over using two classifier networks. However, combining EfficientNet with ViT significantly improves performance. This result is identical to the result of a recent study that showed that although supervised and self-supervised expressions are similar, ViT and CNN learn different expressions. Combining the two architectures appears to have complementary effects on Projected GANs. Adding more networks doesn’t improve much.
4. Classifier Guidance for GANs
The paper Diffusion Models Beat GANs on Image Synthesis introduced classifier guidance to inject class information into the diffusion model. Classifier guidance modifies each diffusion step in timestep $t$ by adding the gradient \(\nabla_{x_t} \log p_\phi (c \vert x_t, t)\) of the pretrained classifier. Applying guidance to the class conditional model and adjusting the clasifier gradient with a constant $\lambda > 1 gives the best results. This indicates that the model in this paper can benefit from classifier guidance even if it already receives class information through embedding.
First, the class label $c_i$ is predicted by passing the image $x$ generated through the pretrained classifier CLF. Then we add the cross-entropy loss as an additional term to the generator loss and scale this term by the constant $\lambda$.
\[\begin{equation} \mathcal{L}_{CE} = -\sum_{i=0}^C c_i \log \textrm{CLF}(x_i) \end{equation}\]For the classifier, we use DeiT-small, which shows strong classification performance without adding much overhead to learning. $\lambda = 8$ is said to work well empirically. Classifier guidance only works well at high resolutions ($> 32^2$). Otherwise, it leads to mode collapse.
5. Ablation Study
The following is the result of the ablation study on ImageNet $128^2$ for the elements described above.

Results
1. Image Synthesis
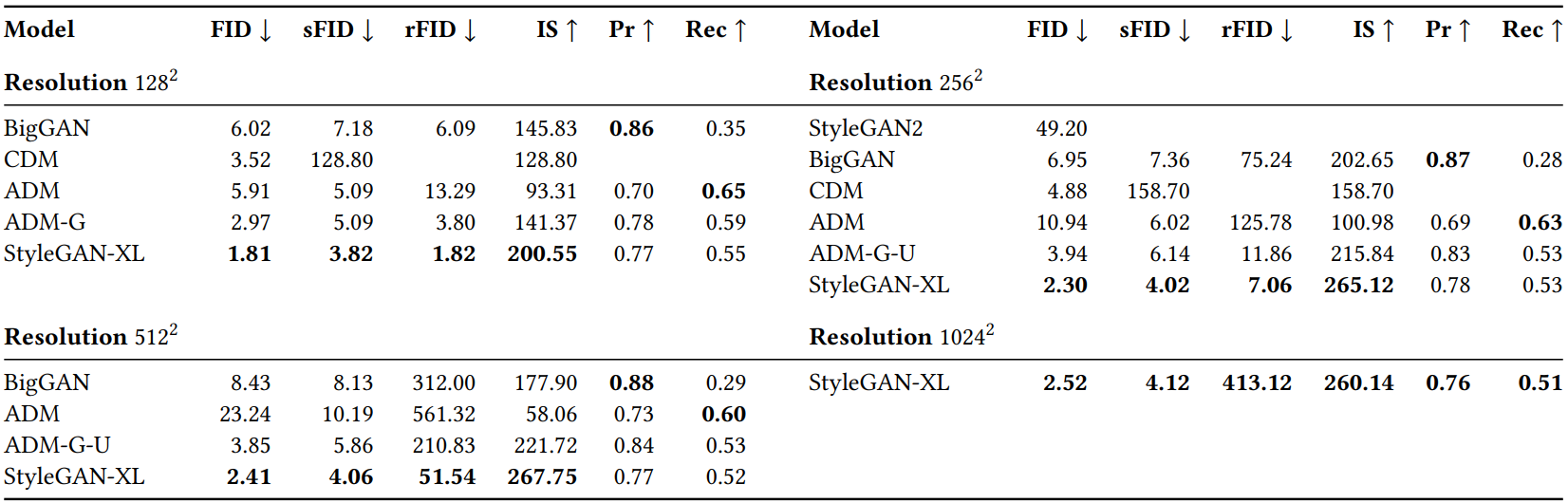
The following table compares image synthesis performance in ImageNet.
Below are samples at various resolutions for the same $w$.

2. Inversion and Manipulation
The GAN-editing method first inverts the given image into latent space. That is, when $G_s$ is passed, the style code $w$ that reconstructs the image as faithfully as possible is found. Then you can do semantic editing by manipulating $w$.
Inversion
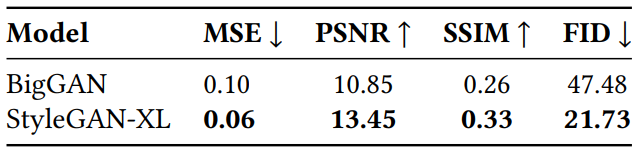
The following table shows the inversion results. It was measured between inversion and reconstruction objects obtained from the model.
The following is an example of interpolation.

Image Manipulation
The following is an example of image editing (left) and style mixing (right).

The following is an example of manipulating an image along the semantic direction in the latent space found by StyleMC when a random sample is given. From the top, the latent space was manipulated in the directions of “smile”, “no stripes”, and “big eyes”.

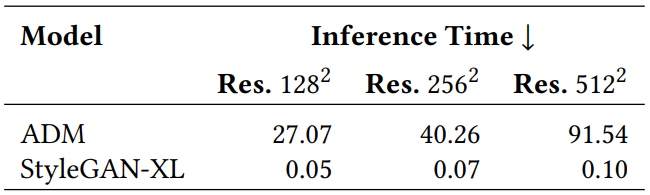
3. Inference Speed
The following table compares the inference time of ADM and StyleGAN-XL.
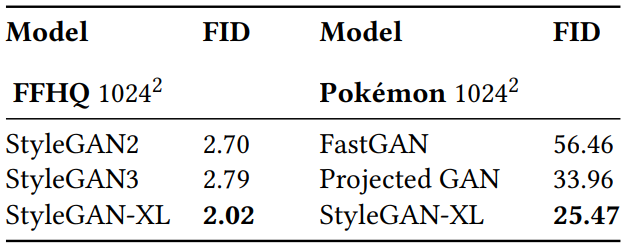
4. Results on Unimodal Datasets
The following table compares the performance of the unimodal dataset FFHQ $1024^2$ and Pokémon $1024^2$.
Limitations
- StyleGAN-XL is three times larger than StyleGAN3, so it requires a higher computational overhead when used as a starting point for fine-tuning.
- StyleGAN3 and StyleGAN-XL are more difficult to edit. (Ex. High-quality editing via $\mathcal{W}$ is much easier with StyleGAN2.)
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)