






EVCA 2022. [Paper]
Sangheyon Na
Kakao Brain
Introduction
The face-swapping model has two goals.
- You need to create high-quality images.
- ID properties such as face shape should be properly transferred from the source image to the target image.
For high-quality images, pre-trained StyleGAN is used to generate images by GAN inversion method. By designing an encoder called Facial attribute encoder, ID representation is extracted from the source image and ID-unrelated representation is extracted from the target image. These representaton are fed into the pre-trained StyleGAN generator to mix the representaton and generate a high-quality megapixel face-swapped image.
Basically, the facial attribute encoder extracts the style code similar to the existing StyleGAN-based GAN inversion encoder. One of the important things in face-swapping is to accurately reconstruct the details of the target image, such as facial expression or background. However, ID-irrelevant style codes without a spatial dimension may not preserve details in the target image. Therefore, the face attribute encoder extracts not only the style code but also the style map with spatial dimensions from the target image. Style maps that utilize spatial dimensions can supplement ID-irrelevant style codes by propagating additional information about the details of the target image. As a result, the face attribute encoder that extracts the style code and style amp can effectively capture ID-irrelevant attributes including the ID attribute of the source image and the details of the target image. The previous model, MegaFS, which utilizes pre-trained StyleGAN, has difficulty reconstructing the details of the target image because it uses only the style code. MegaFS solves this problem by using segmentation labels to pull details from the target image. On the other hand, MFIM solves this problem by extracting style maps instead of using segmentation labels.
For effective ID conversion, use 3DMM (a model that extracts 3D parameters from 2D images) that can capture various face attributes. In particular, we pay attention to the change in face shape, which is one of the important factors for recognizing identity. However, since these two goals conflict, it is difficult to transform the face shape while simultaneously maintaining the ID-irrelevant property of the target image. If the generated image has the same face shape as the original image, the generated image will be very different from the target image. Conversely, if the ID-irrelevant property of the target image is maintained, it will be similar to the target image.
To simultaneously achieve these two contradictory goals, we utilize a 3DMM that can accurately and clearly capture various facial attributes such as shape, pose, and expression in a given image. Specifically, we use 3DMM to train the model to generate a face-swapped image with the desired properties, that is, the same face shape as the source image, but the same pose and expression as the target image. MFIM can transform the face shape well while maintaining the ID-irrelevant property of the target image. In the case of HiFiFace using 3DMM, 3DMM is used for inference as well as learning, but MFIM does not use 3DMM for inference.
Additionally, the authors proposed a new task called ID mixing. ID mixing is to do a face-swap with a new identity created from multiple source images. Here, the authors aim to design a way for users to semantically control the ID generation process. For example, a new ID is created by extracting a face shape from one source image and an eye shape from another source image.
MFIM: Megapixel Facial Identity Manipulation
1. Facial Attribute Encoder
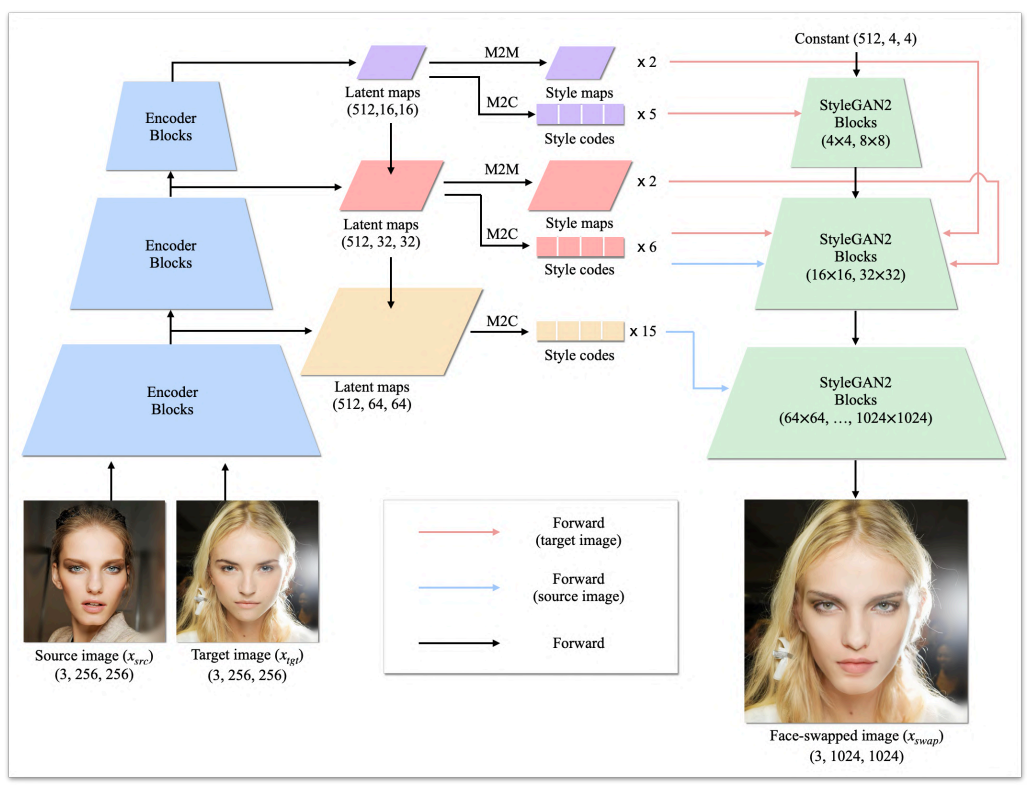
The structure of the facial attribute encoder is as above. First, hierarchical latent maps are extracted from a given image like the pSp encoder. Then, a style code and a style map are generated with the map-to-code (M2C) block and the map-to-map (M2M) block, respectively, and input to the pre-trained StyleGAN generator.
Style code
The facial attribute encoder extracts 26 style codes by mapping the given image to the latent space $\mathcal{S}$. The style code corresponding to the coarse resolution (4x4 ~ 16x16) is extracted from the target image $x_{tgt}$ and synthesizes overall aspects such as the overall structure or pose. Conversely, the style code corresponding to fine resolution (32x32 ~ 1024x1024) is extracted from the source image $x_{src}$ and synthesizes relatively local aspects such as face shape, eyes, nose, and lips. From this point of view, the style code extracted from $x_{tgt}$ is called ID-irrelevant style code, and the style code extracted from $x_{src}$ is called ID style code. On the other hand, it is important to reconstruct the details of the target image (facial expression, background, etc.), but ID-irrelevant style codes lose these details because they have no spatial dimension.
Style map
In order to preserve the detail of $x_{tgt}$, the encoder extracts a style map with spatial dimensions from $x_{tgt}$. Specifically, a style map of the same size as the latent map input to the M2M blocks of the encoder is created. These style maps are then fed into a pre-trained StyleGAN generator as noise input to generate fine details.
2. Training Objectives
ID loss
Since $x_{swap}$ must have the same identity as $x_{src}$, ID loss is calculated as cosine similarity.
\[\begin{equation} \mathcal{L}_{id} = 1 - \cos (R(x_{swap}), R(x_{src})) \end{equation}\]($R$ is a pre-trained face recognition model)
Reconstruction loss
$x_{swap}$ should be similar to $x_{tgt}$ except for the area related to the ID. To impose this constraint, we adopt the pixel-level L1 loss and LPIPS loss to define the reconstruction loss as:
\[\begin{equation} \mathcal{L}_{recon} = L_1 (x_{swap}, x_{tgt}) + LPIPS (x_{swap}, x_{tgt}) \end{equation}\]Adversarial loss
To make $x_{swap}$ realistic, we use non-saturating adversarial loss and R1 regularization.
3DMM supervision
You need to force $x_{swap}$ to have the same face shape as $x_{src}$, and the same pose and expression as $x_{tgt}$. For these constraints, we use 3DMM to define the following loss.
\[\begin{equation} \mathcal{L}_{shape} = \| s_{swap} - s_{src} \|_2 \\ \mathcal{L}_{pose} = \| p_{swap} - p_{tgt} \|_2 \\ \mathcal{L}_{exp} = \| e_{swap} - e_{tgt} \|_2 \\ \end{equation}\]$s$, $p$, and $e$ are face shape, pose, and expression (exp) parameters extracted from the 3DMM encoder. As such, 3DMM is used only for loss calculation in the learning process and is not used in inference.
Full objective
The total loss $\mathcal{L}$ is:
\[\begin{aligned} \mathcal{L} = & \; \lambda_{id} \mathcal{L}_{id} + \lambda_{recon} \mathcal{L}_{recon} + \lambda_{adv} \mathcal{L}_{adv} + \lambda_{R_1} \mathcal{L}_{R_!} \\ & + \lambda_{shape} \mathcal{L}_{shape} + \lambda_{pose} \mathcal{L}_{pose} + \lambda_{exp} \mathcal{L}_{exp} \end{aligned}\]3. ID Mixing

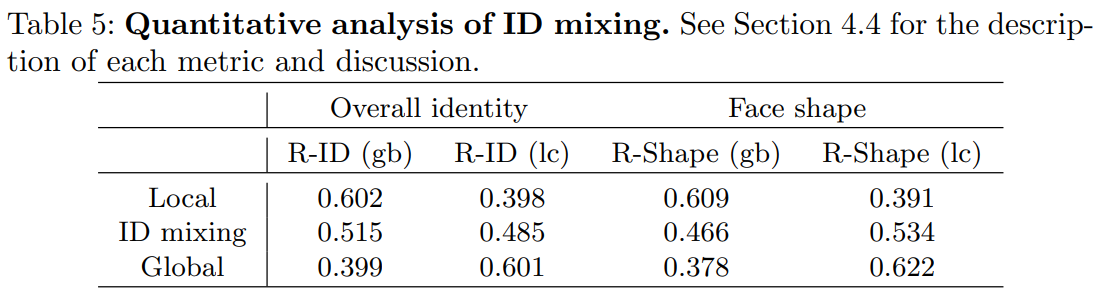
ID Mixing extracts and mixes ID style codes from multiple source images so that users can semantically control the ID creation process. In the figure above, ID mixing is performed from two source images, but it can be generalized to use multiple source images. In case of using two source images, the user can get the global ID attribute from one source image and the local ID attribute from the other source image, mix them together, and compose the ID-mixed image $x_{image}$.
In the figure above, the ID-irrelevant style code and style map are extracted from $x_{tgt}$, and the ID style code is extracted from the global source image $x_{src}^{gb}$ and the local source image $x_{src}^{ Extracted from lc}$. Global ID style code is used for coarse resolution and local ID style code is used for fine resolution.
Experiments
- Baseline: Deepfakes, FaceShifter, Sim-Swap, HifiFace, InfoSwap, MegaFs, SmoothSwap
- Dataset: FFHQ (train), FaceForensics++ & CelebA-HQ (evaluation)
- Evaluation metric
- identity, shape, expression: $L_2$ distance in feature space of face recognition model
- pose: $L_2$ distance in 3DMM parameter space
- posh-HN: $L_2$ distance in feature space of pose prediction model
Here are the results for CelebA-HQ.

A quantitative comparison between FaceForensics++ and CelebA-HQ is as follows.
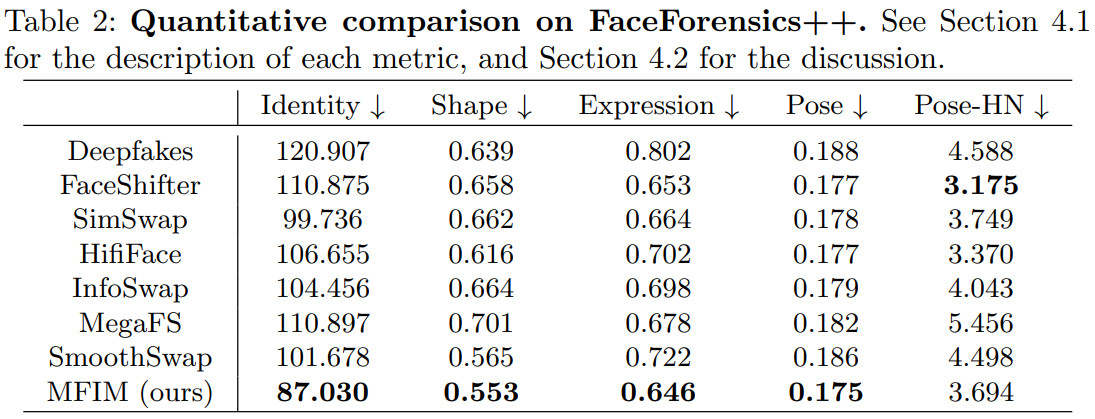

The following is a quantitative comparison with baselines.

Ablation Study


ID Mixing

![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)