






arXiv 2023. [Paper]
Jiyoung Lee, Joon Son Chung, Soo-Whan Chung
NAVER AI Lab | KAIST | NAVER Cloud
27 Feb 2023
Introduction
TTS는 주어진 텍스트 transcription(전사)에서 음성 waveform(파형)을 생성하는 음성 처리의 핵심 task 중 하나이다. 텍스트 시퀀스에서 고품질 spectral feature을 생성하기 위해 심층 생성 모델이 도입되었으며, 기존의 합성 방법에 비해 합성 음성 신호의 품질이 크게 향상되었다. Diffusion model에 대한 최근 연구는 이미지 생성, 동영상 생성, 자연어 처리와 같은 다양한 연구 분야에서 고품질의 출력의 우수한 생성 결과를 제공하고 있다. Diffusion 방법은 음향(acoustic) 모델링과 vocoder 모두에서 이전 생성 방법과 비교하여 TTS에서 인상적인 결과를 보여주었다.
그러나 TTS 분야에는 몇 가지 해결되지 않은 문제가 있다. 한 가지 문제는 single speaker TTS 모델을 multi-speaker TTS로 확장하는 것이다. 사람마다 말하는 스타일, 어조 또는 억양이 다르기 때문에 TTS 모델이 다양한 speaker 스타일을 배우는 것은 매우 어렵다. 또 다른 문제는 multi-speaker TTS의 경우에도 학습중에 보지 못한 speaker의 음성을 생성하기 위해 상당한 양의 target speaker의 음성 샘플이 필요하다는 것이다. 말하는 스타일의 다양성은 모델이 각 speaker에 대해 학습하기 위해 상당한 양의 등록 데이터를 사용할 수 있어야 함을 의미한다. 각 speaker에 대해 깨끗한 발화를 얻기가 어렵기 때문에 “깨끗한 말 대신 얼굴 이미지를 등록 데이터로 사용할 수 있다면 어떨까요?”라는 질문이 제기된다.
Face2speech 논문에서는 얼굴 이미지를 활용하여 합성 음성의 speaker 특성을 제어할 것을 제안한다. TTS 모델과 독립적으로 음성 인코더와 공동 임베딩 공간을 공유하도록 얼굴 ID 인코더를 학습시킨다. 이 접근 방식을 사용하면 별도의 speaker 적응 없이 보지 못한 speaker를 위한 음성 생성이 가능하다. 그러나 TTS 모델을 학습시킬 때 얼굴 이미지를 입력으로 사용하지 않는다. 대신 speaker 임베딩을 입력으로 사용하여 모델을 학습하고 임베딩은 inference 중에만 얼굴 이미지로 교체된다.
본 논문에서는 speaker의 robust한 특성을 제공하기 위해 얼굴 이미지를 활용한 새로운 음성 합성 모델인 Face-TTS를 제안한다. Learnable pins 논문에서 cross-modal 생체 인식을 탐구하고 목소리와 얼굴 모양 사이에 강한 상관 관계가 있음을 입증했다. 이에 영감을 받아 말하는 스타일이 얼굴 특성에 따라 결정되는 multi-speaker TTS 모델을 디자인한다. 모든 speaker의 등록을 위해 음성 세그먼트를 수집하는 것은 어렵지만 얼굴 이미지를 얻는 것은 훨씬 쉽다. 말하기 스타일의 강력한 cross-modal 표현을 학습시키기 위해 얼굴의 identity와 합성된 음성의 identity의 일치를 시행한다. 본 논문의 접근 방식은 speaker 등록 없이 음성 신호를 생성할 수 있으며 이는 zero-shot 또는 few-shot TTS 모델링에 유리하다. TTS 모델의 backbone 구조는 diffusion 방법을 사용하여 음향 feature을 학습하는 Grad-TTS에서 파생된다. 다른 face-to-speech 합성 방법과 달리 Face-TTS는 실제 데이터셋을 사용하여 얼굴 인코더에서 음향 모델까지 end-to-end로 학습된다. 얼굴 이미지가 TTS 모델 학습 조건으로 사용된 것은 본 논문이 처음이다. Speaker의 표현과 합성된 음성의 지각적(perceptual) 품질을 평가하기 위해 정성 및 정량 테스트를 수행한다. 또한 합성된 음성이 아래 그림과 같이 자신의 목소리가 없는 가상인간의 모습과 잘 어울리는지 검증한다.
Face-TTS
1. Score-based Diffusion Model
Face-TTs는 score 기반 diffusion model인 Grad-TTS를 기반으로 하며, 3가지 부분으로 구성된다.
- 텍스트 인코더
- Duration predictor
- Diffusion model
텍스트 전사 $C$와 mel-spectrogram $X_0$가 주어지면, forward process는 다음과 같은 연속적인 SDE를 만족하도록 점진적으로 standard Gaussian noise를 더한다.
\[\begin{equation} dX_t = - \frac{1}{2} X_t \beta_t dt + \sqrt{\beta_t} dW_t \end{equation}\]$W_t$는 standard Brownian motion이고 $\beta_t$는 noise schedule이다. Reverse diffusion process에서는 다음과 같은 SDE로 $X_t$에서 $X_0$를 얻는다.
\[\begin{equation} dX_t = - \bigg( \frac{1}{2} X_t + S(X_t, t) \bigg) \beta_t dt + \sqrt{\beta_t} d \bar{W}_t \end{equation}\]$\bar{W}_t$는 reverse-time Brownian motion이고 $S(X_t, t)$는 $X_t$의 log-density의 기울기를 추정하는 diffusion model이다. 다음과 같이 SDE를 $N$ step으로 풀어서 $X_0$를 얻는다.
\[\begin{equation} X_{t- \frac{1}{N}} = X_t + \frac{\beta_t}{N} \bigg( \frac{1}{2} X_t + S(X_t, t) \bigg) + \sqrt{\beta_t} \bar{W}_t \\ t \in \{ \frac{1}{N}, \frac{2}{N}, \cdots, 1 \} \end{equation}\]전체적인 아키텍처는 아래와 같다.

2. Speaker Conditioning with Cross-modal Biometrics
Grad-TTS와 Glow-TTS 논문에서는 말하는 스타일을 학습하기 위한 speaker model을 활용하지 않지만 각 identity에 대한 사전 정의된 speaker codebook을 준비한다. 따라서 모델에 새로운 speaker를 제시하기 어렵고, 이를 해결하기 위해서는 어려운 적응 과정이 필요하다. Adaspeech 등의 논문에서는 speaker embedding이 합성된 음성에서 말하는 스타일을 정확하게 조정함을 증명하였다. 그러나 여전히 문제가 남아 있다. Speaker embedding은 일반적으로 speaker의 과도한 디테일을 나타내며 TTS의 음향 모델링에서 불안정한 학습을 생성한다. 따라서 speaker embedding은 합성된 음성에서 speaker의 음성을 나타내도록 일반화되어야 한다.
본 논문에서는 multi-speaker 모델링을 위한 TTS 모델의 컨디셔닝 feature로 얼굴 이미지에서 ID 임베딩을 제공한다. Cross-modal 생체인식 모델에서 임베딩된 얼굴은 음성과 관련된 identity를 나타내므로 얼굴 속성과 일치하는 음성 생성에 적합하다다. 이러한 얼굴 임베딩은 speaker의 복잡한 분포를 포함하지 않고 음성과 얼굴의 연관 표현만 포함하며 speaker embedding을 자연스럽게 일반화하고 효율적인 multi-speaker 모델링을 가능하게 한다. Mel-spectrogram $X = X_0$와 얼굴 이미지 $I$가 주어지면 네트워크는 서로 다른 양식의 동일한 speaker ID를 연결하도록 사전 학습된다. 여기서 전체 네트워크는 오디오 네트워크 $\mathcal{F} (X)$와 시각적 네트워크 $\mathcal{G}(I)$로 구성된다.
시각적 네트워크는 target speaker의 얼굴 이미지를 수집하여 speaker 표현을 생성한다. 그런 다음 텍스트 인코더와 duration predictor는 주어진 텍스트 전사와 얼굴 이미지에서 음향 feature의 통계를 추정한다. 세부적으로 텍스트 인코더는 텍스트 시퀀스에 맞는 음향 feature을 생성하고 duration predictor는 자연스러운 발음을 위해 대상 speaker의 예측된 duration으로 feature을 colourise한다. 학습 중에 diffusion process는 colourise된 feature에 Gaussian noise를 추가하여 잡음이 있는 데이터를 만들고 diffusion model은 target 오디오를 얻기 위해 noisy한 데이터에서 데이터 분포의 기울기를 추정한다. 특히 speaker 표현은 diffusion model을 guide하여 speaker의 음성에서 합성된 음성을 생성하는 데 최적인 기울기를 추정한다. 네트워크 구성은 Grad-TTS를 따른다.
그러나 multi-speaker TTS를 위한 다양한 speaker의 특성을 학습하기 위해서는 TTS 모델은 각 사람마다 충분한 길이의 녹음된 음성이 필요하다. 이전 연구에서는 발화 길이가 충분한 여러 speaker가 읽은 오디오북 데이터셋을 사용하여 모델을 학습했으며, 이는 보지 못한 speaker에 대한 모델을 일반화하기 어렵다. 이 문제를 해결하기 위해 합성 음성에서 target 음성의 speaker 특성을 유지하면서 speaker feature binding loss라는 효과적인 전략을 제안한다. 이를 통해 Face-TTS는 길이가 짧은 경우에도 오디오 세그먼트에서 얼굴-음성 연관성을 학습할 수 있다. Cross-modal 생체 인식에서 학습된 오디오 네트워크의 convolution layer의 latent embedding은 각각 합성된 음성과 target 음성에서 추출된다. Speaker feature binding loss \(\mathcal{L}_{spk}\)는 다음과 같이 두 latent embedding 집합의 거리를 최소화하여 Face-TTS 모델을 학습시킨다.
\[\begin{equation} \mathcal{L}_{spk} = \sum_B \vert \mathcal{F}_b (X_0) - \mathcal{F}_b (X_t') \vert \end{equation}\]$X_0$는 target speaker의 발화의 mel-spectrogram이고 $X_t’$는 신경망의 denoise된 출력이다. $B$는 처음 두 개의 convolution block을 제외한 오디오 네트워크의 convolution block 수를 나타낸다. 이 loss로 업데이트되지 않도록 오디오 네트워크를 freeze한다. 이 학습 전략은 target 음성과 유사하게 합성 음성의 speaker 관련 latent 분포를 형성하도록 한다.
3. Training & Inference
학습 시에 Face-TTs는 여러 학습 기준을 통해 multi-speaker 음성 합성을 학습한다. 텍스트 인코더와 duration 인코더를 학습시키기 위해 정규 분포에서 평균을 추정하기 위해 prior loss를 활용하고, 음성과 텍스트 시퀀스 간의 monotonic alignment를 사용하여 duration을 제어하기 위해 duration loss를 활용한다. Diffusion loss는 diffusion model을 학습시켜 Grad-TTs에서와 같이 데이터 분포의 기울기를 추정한다. 최종 목적 함수는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{prior} + \mathcal{L}_\textrm{duration} + \mathcal{L}_\textrm{driff} + \gamma \mathcal{L}_\textrm{spk} \end{equation}\]$\gamma$는 경험적으로 0.01로 설정한다. 전체 프레임워크는 LRS3 데이터셋(TED 동영상에서 수집된 오디오-시각 데이터셋)에서 end-to-end로 학습된다. LRS3 데이터셋이 다양한 각도와 표졍의 데이터를 가지고 있기 때문에 Face-TTS는 정면 이미지만 사용한 기존 연구들보다 실제 얼굴 이미지에 더 robust하다.
Inference 시에는 target speaker의 얼굴로 컨디셔닝된 전사로 $X_t$에서 mel-spectrogram $X_0$를 샘플링한다. Reverse diffusion process는 점진적으로 step별 noise를 추정하도록 반복적으로 처리된다. 마지막으로 사전 학습된 vocoder를 사용하여 추정된 mel-spectrogram을 waveform으로 변환한다.
Experiments
Audio quality
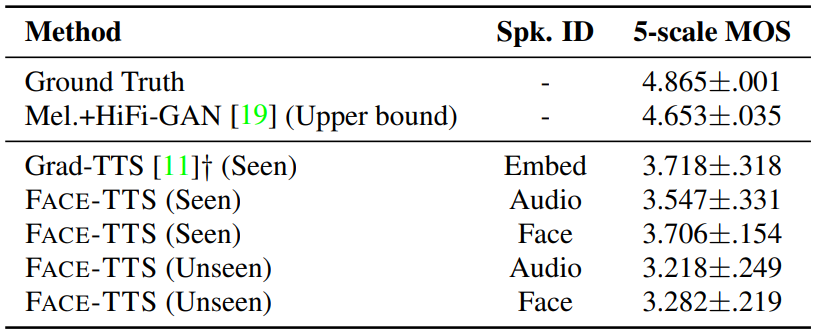
다음은 mean opinion score (MOS)로 오디오 품질에 대한 주관적 평가를 비교한 표이다.
Speaker verification
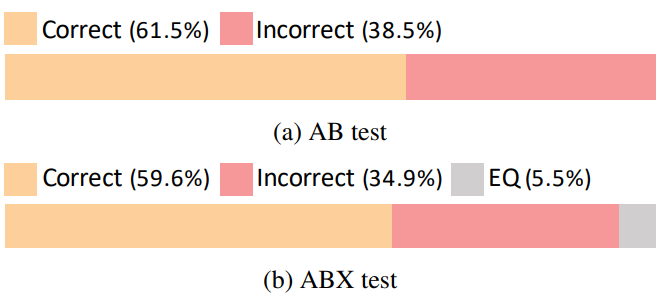
다음은 두 합성 발화와 일치하는 얼굴에 대한 선호도(a)와 두 얼굴 모습에 일치하는 합성 발화에 대한 선호도(b)를 테스트한 결과이다.
다음은 speaker 신원 일치 정확도에 대한 표이다.

Virtual speech generation
다음은 Stable Diffusion으로 생성한 가상 얼굴 이미지와 생성된 발화 사이의 일치 선호도를 평가한 표이다.

![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)