






NeurIPS 2022. [Paper] [Github]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, Mohammad Norouzi
Google Research, Brain Team
23 May 2022
Introduction
Multimodal 학습은 최근 text-to-image 합성 및 이미지-텍스트 contrastive learning과 함께 두각을 나타내고 있다. 이러한 모델은 독창적인 이미지 생성 및 편집 어플리케이션으로 광범위한 대중의 관심을 끌었다. 이 연구 방향을 더욱 추구하기 위해 저자들은 transformer language model (LM)의 파워를 고성능 diffusion model과 결합하여 전례없는 정도의 사실감과 text-to-image 합성에서 깊은 수준의 언어 이해를 제공하는 text-to-image diffusion model인 Imagen을 소개한다. 모델 학습에 이미지-텍스트 데이터만 사용하는 이전 연구들과 달리 Imagen의 주요 발견은 텍스트 전용 말뭉치에서 사전 학습된 대형 LM의 텍스트 임베딩이 text-to-image 합성에 매우 효과적이라는 것이다.
Imagen은 입력 텍스트를 임베딩 시퀀스와 64$\times$64 이미지 확산 모델로 매핑하는 고정된 T5-XXL 인코더와 256$\times$256 및 1024$\times$1024 이미지를 생성하기 위한 2개의 super-resolution diffusion model로 구성된다. 모든 diffusion model은 텍스트 임베딩 시퀀스로 컨디셔닝되며 classifier-free guidance를 사용한다. Imagen은 새로운 샘플링 기술을 사용하여 이전 연구들에서 관찰된 샘플 품질 저하 없이 큰 guidance 가중치를 사용할 수 있도록 하여 이전에 가능했던 것보다 더 높은 fidelity와 더 나은 이미지-텍스트 alignment를 가진 이미지를 생성한다.
Imagen
Imagen은 텍스트를 임베딩 시퀀스에 매핑하는 텍스트 인코더와 이러한 임베딩을 증가하는 해상도의 이미지에 매핑하는 조건부 diffusion model의 cascade로 구성된다.
1. Pretrained text encoders
Text-to-image model은 임의의 자연어 텍스트 입력의 복잡성과 구성성을 캡처하기 위해 강력한 semantic text encoder가 필요하다. 쌍을 이룬 이미지-텍스트 데이터에 대해 학습된 텍스트 인코더는 현재 텍스트-이미지 모델에서 표준이다. 처음부터 학습하거나 이미지-텍스트 데이터(ex. CLIP)에 대해 사전 학습할 수 있다. 이미지-텍스트 목적 함수는 이러한 텍스트 인코더가 특히 text-to-image 생성 task와 관련된 시각적으로 의미론적이고 유의미한 표현을 인코딩할 수 있음을 시사한다.
대규모 언어 모델은 텍스트를 인코딩하기 위해 선택할 수 있는 또 다른 모델이 될 수 있다. 대규모 언어 모델(ex. BERT, GPT, T5)의 최근 발전으로 인해 텍스트 이해 및 생성 기능이 크게 향상되었다. 언어 모델은 쌍으로 된 이미지-텍스트 데이터보다 훨씬 더 큰 텍스트 전용 corpus에 대해 학습되므로 매우 풍부하고 광범위한 텍스트 분포에 노출된다. 이러한 모델은 또한 일반적으로 현재 이미지-텍스트 모델의 텍스트 인코더보다 훨씬 크다.
따라서 저자들은 text-to-image task를 위해 두 가지 텍스트 인코더를 탐색하였다. Imagen은 BERT, T5, CLIP 과 같은 사전 학습된 텍스트 인코더를 탐색한다. 단순화를 위해 이러한 텍스트 인코더의 가중치를 freeze한다. Freezing은 임베딩의 오프라인 계산과 같은 몇 가지 장점이 있어 text-to-image 모델을 학습하는 동안 무시할 수 있는 계산 또는 메모리 공간을 사용한다. 저자들은 텍스트 인코더 크기를 조정하면 텍스트-이미지 생성 품질이 향상된다는 점을 발견했다. 또한 T5-XXL과 CLIP 텍스트 인코더가 MS-COCO와 같은 간단한 벤치마크에서 유사하게 수행된다. 반면 인간 평가자는 어려운 프롬프트로 구성된 DrawBench에서 이미지-텍스트 alignment와 이미지 fidelity 모두에서 CLIP 텍스트 인코더보다 T5-XXL 인코더를 선호하였다고 한다.
2. Diffusion models and classifier-free guidance
Diffusion model은 반복적인 denoising process를 통해 Gaussian noise를 학습된 데이터 분포의 샘플로 변환하는 생성 모델 클래스이다. 이 모델은 클래스 레이블, 텍스트, 저차원 이미지 등으로 컨디셔닝할 수 있다. Diffusion model $\hat{x}_\theta$는 다음과 같은 목적 함수로 학습된다.
\[\begin{equation} \mathbb{E}_{x, c, \epsilon, t} [ w_t \| \hat{x}_\theta (\alpha_t x + \sigma_t \epsilon, c) - x \|_2^2 ] \\ t \sim \mathcal{U} ([0, 1]), \quad \epsilon \sim \mathcal{N} (0, I) \end{equation}\]여기서 $(x, c)$는 데이터-컨디셔닝 쌍이며, $\alpha_t$, $\sigma_t$, $w_t$는 샘플 품질에 영향을 미치는 $t$의 함수이다. 직관적으로, \(\hat{x}_\theta\)는 $z_t := \alpha_t x + \sigma_t \epsilon$을 $x$로 denoise하도록 학습된다. Ancestral sampler나 DDIM과 같은 샘플링은 순수한 noise $z_1 \sim \mathcal{N}(0,I)$에서 시작하여 $1 = t_1 > \cdots > t_T = 0$에 대하여 점진적으로 $z_{t_1}, \cdots, z_{t_T}$를 생성한다. 이 값들은 $x$ 예측값 \(\hat{x}_0^t = \hat{x}_\theta (z_t, c)\)의 함수이다.
Classifier guidance는 샘플링 중에 사전 학습된 모델 $p(c \vert z_t)$의 기울기를 사용하여 조건부 diffusion model의 다양성을 감소시키면서 샘플 품질을 개선시키는 테크닉이다. Classifier-free guidance는 사전 학습된 모델을 사용하지 않는 대신 학습 중에 랜덤하게 $c$를 drop하여 하나의 diffusion model을 conditional 및 unconditional 목적 함수로 동시에 학습 시키는 테크닉이다. 샘플링은 수정된 $x$ 예측값 \((z_t - \sigma \tilde{\epsilon}_\theta)/\alpha_t\)을 사용한다. 여기서 $\tilde{\epsilon}_\theta$는 다음과 같이 정의된다.
\[\begin{equation} \tilde{\epsilon}_\theta (z_t, c) = w \epsilon_\theta (z_t, c) + (1 - w) \epsilon_\theta (z_t) \\ \epsilon_\theta := \frac{z_t - \alpha_t \hat{x}_\theta}{\sigma_t} \end{equation}\]$w$는 guidance 가중치이다. $w = 1$이면 guidance 효과가 사라지고, $w$를 증가시키면 점점 guidance의 효과가 강해진다. Imagen은 효과적인 텍스트 컨디셔닝을 위해 classifier-free guidance에 굉장히 의존한다.
3. Large guidance weight samplers
저자들은 최근 text-guided diffusion 연구의 결과를 확증하고 classifier-free guidance 가중치를 높이면 이미지-텍스트 alignment가 향상되지만 이미지 fidelity가 손상되어 채도가 높고 부자연스러운 이미지가 생성됨을 확인했다. 또한 이것이 높은 guidance 가중치로 인해 발생하는 학습-테스트 불일치 때문임을 발견했다. 각 샘플링 단계 $t$에서 $x$ 예측값 $\hat{x}_0^t$는 학습 데이터 $x$와 동일한 범위 내에 있어야 하지만, 경험적으로 높은 guidance 가중치를 사용하면 $x$ 예측값이 이 범위를 넘게 된다. 이는 학습-테스트 불일치이며 diffusion model은 샘플링 전체에 걸쳐 자체 출력에 반복적으로 적용되기 때문에 샘플링 과정에서 부자연스러운 이미지가 생성되고 때로는 발산하기도 한다. 이 문제를 해결하기 위해 static thresholding과 dynamic thresholding을 조사한다.
Static thresholding
$x$ 예측값을 $[-1, 1]$로 elementwise clipping하는 것을 static thresholding이라 한다. 이 방법은 이전 논문에서 실제로 사용되었지만 강조되지 않았으며 그 중요성은 guided sampling의 맥락에서 조사되지 않았다. 저자들은 static thresholding이 큰 guidance 가중치로 샘플링하는 데 필수적이며 빈 이미지 생성을 방지한다는 것을 발견했다. 그럼에도 불구하고 static thresholding은 guidance 가중치가 더 증가함에 따라 여전히 과포화되고 덜 상세한 이미지를 생성한다.
Dynamic thresholding
저자들은 새로운 dynamic thresholding을 도입하였다. 각 샘플링 step $s$를 $\hat{x}_0^t$의 특정 백분위수 절대 픽셀 값으로 설정하고 $s > 1$이면 $\hat{x}_0^t$을 범위의 threshold로 지정한 다음 $s$로 나눈다. Dynamic thresholding은 포화된 픽셀(-1과 1에 가까운 픽셀)을 안쪽으로 밀어 넣어 각 step에서 픽셀이 포화되지 않도록 능동적으로 방지한다. 저자들은 dynamic thresholding을 사용하면 특히 매우 큰 guidance 가중치를 사용할 때 이미지-텍스트 alignment가 훨씬 더 좋아질 뿐만 아니라 훨씬 더 사실적인 결과를 얻을 수 있음을 발견했다.
Robust cascaded diffusion models
Imagen은 base 64$\times$64 모델의 파이프라인과 두 개의 텍스트 조건부 super-resolution diffusion model을 활용하여 64$\times$64로 생성된 이미지를 256$\times$256 이미지로 upsampling한 다음 1024$\times$1024 이미지로 upsampling한다. Noise conditioning augmentation 기능이 있는 cascaded diffusion model은 높은 fidelity의 이미지를 점진적으로 생성하는 데 매우 효과적이다. 또한 noise level conditioning을 통해 super-resolution model이 추가된 noise의 양을 인식하게 하면 샘플 품질이 크게 향상되고 super-resolution model의 견고성이 향상되어 저해상도 모델에서 생성된 아티팩트를 처리할 수 있다. Imagen은 두 super-resolution model 모두에 대해 noise conditioning augmentation를 사용한다. 저자들은 이것이 높은 fidelity의 이미지를 생성하는 데 중요하다는 것을 알았다.
저해상도 이미지와 augmentation level($\textrm{aug_level}$)이 컨디셔닝으로 주어지면 $\textrm{aug_level}$로 저해상도 이미지를 손상시키고 diffusion model을 $\textrm{aug_level}$로 컨디셔닝한다. 학습 중에는 $\textrm{aug_level}$이 랜덤하게 선택되지만 inference 중에는 다양한 값을 스윕하여 최상의 샘플 품질을 찾는다. 저자들은 Gaussian noise를 augmentation으로 사용하고 diffusion model에서 사용되는 forward process와 유사한 variance preserving Gaussian noise augmentation을 적용한다. Augmentation level은 $\textrm{aug_level} \in [0, 1]$를 사용한다.
5. Neural network architecture
Base model
Base 64$\times$64 text-to-image diffusion model에는 Improved DDPM의 U-Net 아키텍처를 적용한다. 신경망은 pooled embedding vector로 된 텍스트 임베딩을 timestep 임베딩에 더해 컨디셔닝된다. 추가로 다양한 해상도에서 텍스트 임베딩을 cross attention에 더해 텍스트 임베딩의 전체 시퀀스를 컨디셔닝한다. 또한 성능 개선을 돕기 위해 attention layer와 pooling layer에 텍스트 임베딩을 위한 Layer Normalization을 사용한다.
Super-resolution model
64$\times$64 $\rightarrow$ 256$\times$256 super-resolution의 경우 Improved DDPM과 Palette에 사용된 U-Net model을 사용한다. 메모리 효율성, inference 속도, 수렴 속도를 위해 U-Net model에 다양한 수정을 하였다. 이 모델을 Efficient U-Net이라고 한다.
256$\times$256 $\rightarrow$ 1024$\times$1024 super-resolution model은 1024$\times$1024 이미지의 64$\times$64 $\rightarrow$ 256$\times$256 crop으로 학습시킨다. 이를 위해 self-attention layer를 제거하고 텍스트 cross-attention layer를 유지한다. inference 중에는 full 256$\times$256 저해상도 이미지를 입력으로 받아 upsampling된 1024$\times$1024 이미지를 출력한다.
Evaluating Text-to-Image Models
COCO는 text-to-image model을 평가하기 위한 표준 벤치마크이다. FID로 이미지 품질을 측정하고 CLIP score로 이미지-텍스트 alignment를 측정한다. FID와 CLIP score 모두 제한점을 가지고 있다. FID는 지각적 품질을 잘 측정하지 못하며, CLIP은 counting에 효과적이지 못하다. 이러한 제한점 때문에 이미지 품질과 캡션 유사성에 대해 인간 평가를 사용한다.
DrawBench
COCO가 가치 있는 벤치마크이지만, 모델 간의 차이점에 대한 통찰력을 쉽게 제공하지 않는 제한된 스펙트럼의 프롬프트가 있다고 알려져 있다. 본 논문에서는 text-to-image model의 평가 및 비교를 지원하는 포괄적이고 어려운 프롬프트 세트인 DrawBench를 도입한다. DrawBench는 모델의 다양한 능력을 테스트하는 11개의 카테고리의 프롬프트를 가지고 있으며, 다양한 색상, 개체의 수, 공간 관계, 장면 안의 텍스트, 개체 간의 비정상적인 상호 작용 등을 충실하게 렌더링하는 능력이 포함된다. 또한 길고 복잡한 텍스트 설명, 희귀한 단어, 철자가 틀린 프롬프트를 포합하는 복잡한 프롬프트가 카테고리에 포함된다. 저자들은 DALL-E, DALL-E 2, Reddit에서 모은 프롬프트의 세트를 추가하였다. 이 11개의 카테고리에서 DrawBench는 총 200개의 프롬프트로 구성되어 크고 포괄적인 데이터셋에 대한 요구와 사람의 평가가 가능할 만큼 충분히 작은 데이터셋 사이에 적절한 균형을 유지한다.
Experiments
1. Results on COCO
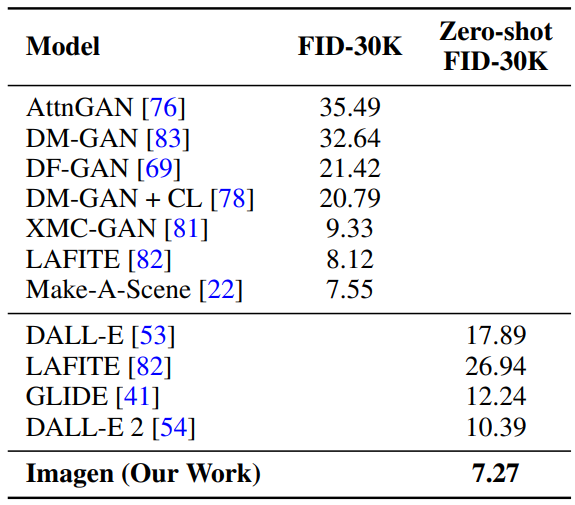
다음은 MS-COCO 256$\times$256에서 FID-30K를 측정한 표이다. Guidance 가중치는 base model이 1.35, super-resolution model이 8이다.
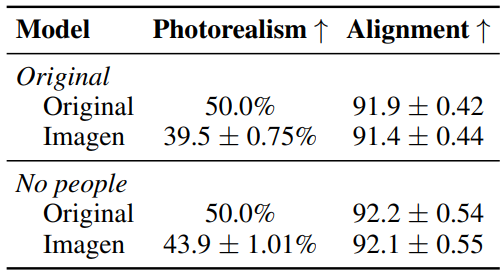
다음은 이미지 품질과 alignment에 대한 인간 평가 결과를 나타낸 표이다.
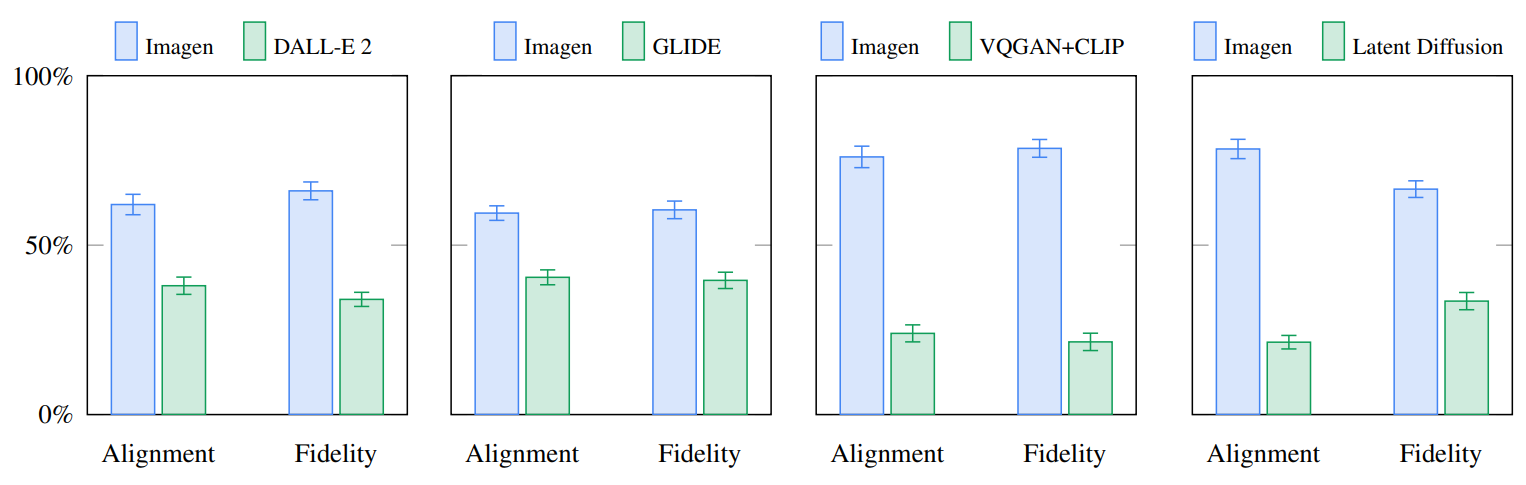
2. Results on DrawBench
다음은 DrawBench에서 Imagen을 다른 모델들과 비교한 인간 평가 결과를 나타낸 그래프이다.
3. Analysis of Imagen
다음은 다양한 guidance 값에 대한 trade-off 곡선을 나타낸 그래프이다.
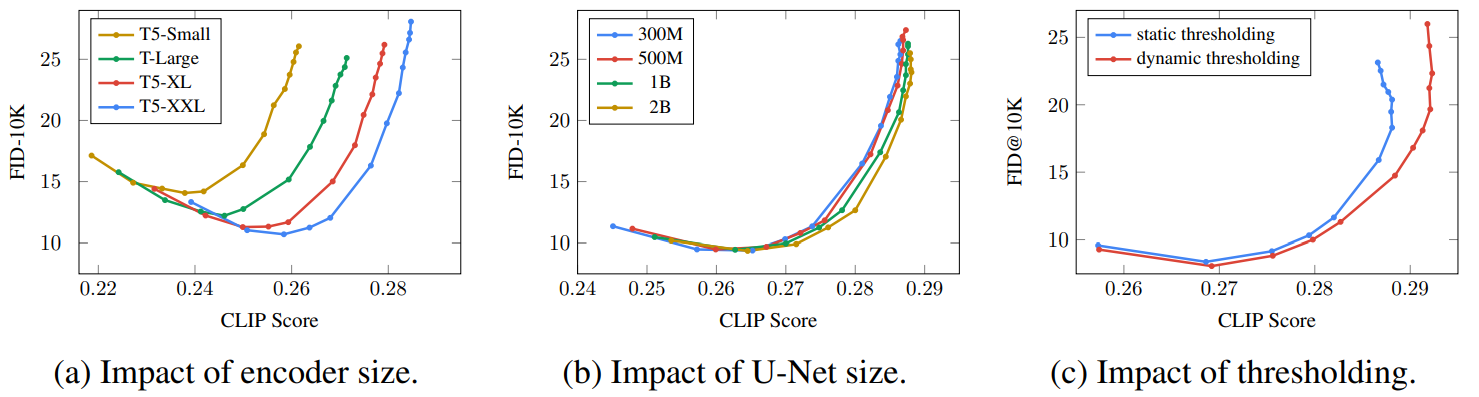
텍스트 인코더의 크기가 커지면 이미지-텍스트 alignment와 이미지 fidelity 모두 지속적으로 개선된다. U-Net의 크기를 키우면 샘플 품질이 개선되지만 텍스트 인코더의 크기를 키우는 것이 더 효과적이다. Dynamic thresholding을 사용하면 사용하지 않았을 떄보다 이미지 품질과 alignment가 좋아지며, 특히 guidance 가중치가 클 때 큰 효과가 보인다.
그 외에도 인간 평가에서 텍스트 인코더로 T5-XXL을 사용할 때가 CLIP을 사용할 때보다 평가가 좋았다. 또한 noise conditioning augmentation을 사용하는 것과 텍스트 임베딩을 cross-attention으로 컨디셔닝하는 것이 중요한 성능 개선을 이끌었다고 한다.
4. Samples for various text inputs
다음은 DrawBench의 다양한 프롬프트에 대한 cherry-picking하지 않은 샘플들이다.

다음은 다양한 텍스트 입력에 대한 1024$\times$1024 Imagen의 샘플이다.

![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)