






arXiv 2022. [Paper]
Gyeongman Kim, Hajin Shim, Hyunsu Kim, Yunjey Choi, Junho Kim, Eunho Yang
KAIST | NAVER AI Lab | AITRICS
6 Dec 2022

(왼쪽은 안경 추가, 오른쪽은 수염 추가)
Introduction
주어진 얼굴 이미지의 머리색, 성별, 안경과 같은 다양한 얼굴 속성을 변경하기 위한 컴퓨터 비전의 task 중 하나로서 얼굴 편집은 지속적으로 주목을 받고 있다. 특히, 최근 GAN 모델에 대한 분석과 조작 기술의 개선으로 주어진 이미지의 latent feature를 조작 하여 이 task를 수행 할 수 있다. 또한, 최근에 얼굴 이미지 편집을 위한 많은 방법이 Diffusion Probabilistic Model (DPM)을 기반으로 고품질 및 유연한 조작 성능을 보여주었다.
자연스럽게 동영상의 시간 축을 통합하기 위해 이미지 편집 방법을 확장하기 위한 추가 연구가 제안되었다. 인간의 얼굴이 있는 실제 동영상을 감안할 때, 이 연구는 다른 나머지 feature와 모션으로 대상의 일부 얼굴 속성을 조작하려고 하며, 기본적으로 동영상의 각 프레임을 StyleGAN 기반 이미지 편집 기술을 통해 독립적으로 편집한다.
이 task에서 고해상도 이미지 생성 및 굉장히 disentangle한 semantic representation space와 같은 Stylegan의 장점에도 불구하고, GAN 기반 편집 방법의 단점 중 하나는 인코딩된 실제 이미지를 사전 학습된 generator에 의해 완벽하게 복구할 수 없다는 것이다. 특히, 주어진 이미지의 얼굴이 일부 물체에 의해 비정상적으로 장식되거나 가려진 경우, 고정된 generator는 이를 합성할 수 없다. 완벽한 재구성을 위해, 하나 또는 몇 개의 대상 이미지에서 GAN-inversion을 위한 generator를 추가로 finetuning하는 몇 가지 방법이 필요하며, 이는 계산적으로 비싸다. 또한, finetuning 후 GAN의 원래 편집 가능성을 보장 할 수 없다. 이 위험은 여러 프레임의 모델을 finetuning해야 하므로 동영상 도메인에서 더 악화 될 수 있다.
기존 GAN 기반 방법의 재구성 문제 외에도 동영상 편집 task에서 편집된 프레임 간의 시간적 일관성을 고려하여 현실적인 결과를 생성하는 것이 중요하다. 이를 해결하기 위해 일부 이전 연구들은 원래 프레임의 latent trajectory의 부드러움에 의존하거나 모든 프레임에 대해 동일한 편집 step을 수행하면서 latent feature를 직접 부드럽게 한다. 그러나 이 부드러움은 시간적 일관성을 보장하지 않는다. 오히려, 동일한 편집 step은 의도하지 않게 관련없는 모션 feature과 얽히게 될 수 있기 때문에 다른 프레임에 대해 다른 결과를 만들 수 있다. 예를 들어, 위 그림의 중간 줄에서 안경은 시간이 지남에 따라 다양하며 때로는 사람이 눈을 감을 때 줄어 든다.
본 논문에서는 기존의 한계를 극복한 Diffusion Video Autoencoder라는 얼굴 영상을 위한 새로운 영상 편집 프레임워크를 제안한다. 첫째, 불완전한 재구성 품질로 어려움을 겪는 GAN 기반의 편집 방법 대신 얼굴 동영상 편집을 위한 diffusion 기반 모델을 새로 도입한다. 최근에 제안된 DiffAE처럼 모델은 원본 이미지를 완벽하게 복구할 수 있고 직접 편집할 수 있는 의미론적으로 유의미 한 latent space를 학습한다. 뿐만 아니라 동영상 편집 모델 최초로 동영상의 다음과 같이 분해된 feature를 인코딩한다.
- 모든 프레임이 공유하는 identity feature
- 각 프레임에서 동작이나 표정의 feature
- 큰 편차로 인해 높은 레벨의 representation이 없는 배경 feature
그런 다음 일관된 편집을 위해 원하는 속성에 대해 단일 불변 feature를 조작하기만 하면 된다. 이는 모든 프레임의 latent feature를 편집해야 하는 이전 연구와 비교하여 계산적으로도 이점이 있다.
저자들은 모델이 동영상을 시간 불변 및 프레임별 변형 feature로 적절하게 분해하고 일시적으로 일관된 조작을 제공할 수 있음을 실험적으로 보여준다. 구체적으로 두 가지 조작 방법을 살펴본다.
- 주석이 달린 CelebA-HQ 데이터셋의 semantic representation space에서 linear classifier를 학습하여 타켓 방향으로 semantic feature를 이동하여 미리 정의된 속성 집합의 feature를 편집하는 것
- CLIP loss로 시간 불변 latent feature를 최적화하는 텍스트 기반 편집 방법
계산 비용으로 인해 CLIP loss에 대한 편집 이미지를 완전히 생성할 수 없기 때문에 효율성을 위해 중간 timestep의 latent state를 사용하는 새로운 전략을 제안한다.
Diffusion Video Autoencoders
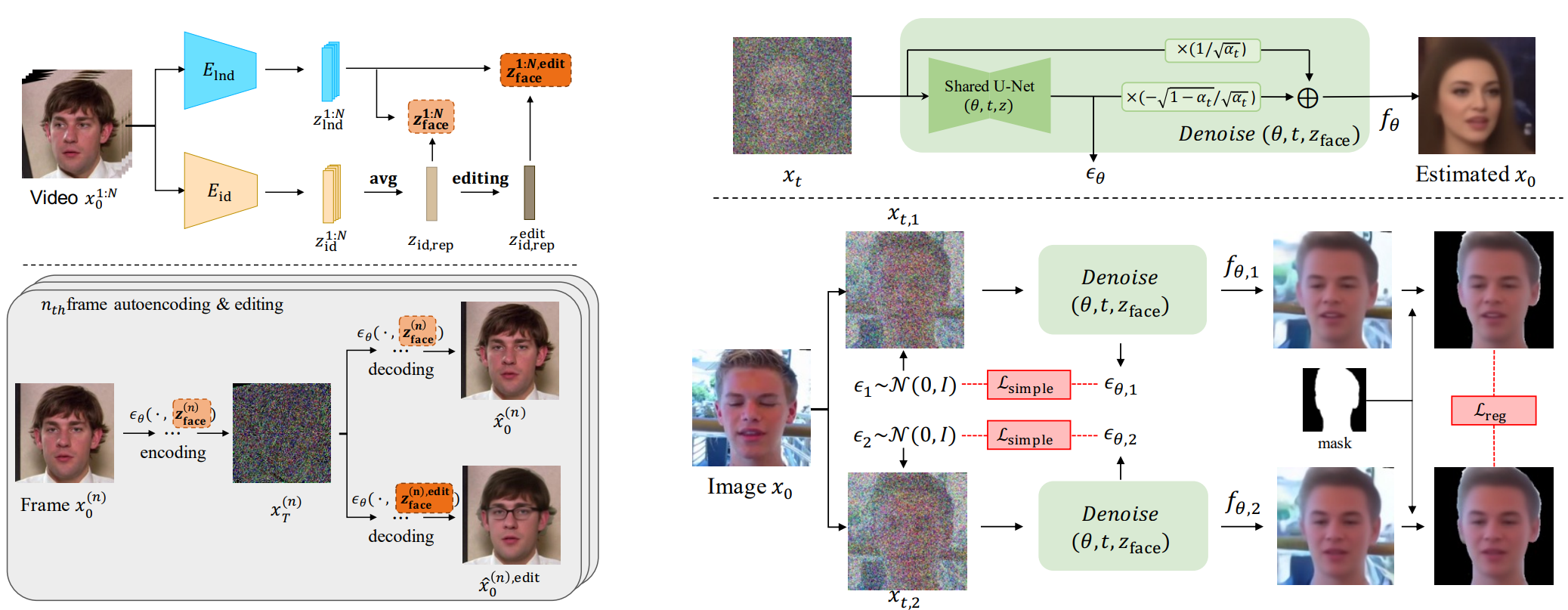
1. Disentangled Video Encoding
N 프레임 \(\{x_0^{(n)}\}_{n=1}^N\)으로 동영상을 인코딩하기 위해 사람 얼굴 동영상의 시불변 feature를 identity 정보로, 각 프레임의 시간 종속 feature를 모션 및 배경 정보로 간주한다. 이 세 가지 중에서 얼굴과 관련된 identity 정보나 모션 정보는 상위 representation을 추출하기 위해 저차원 space에 project하기에 적합하다. 상대적으로 배경은 임의의 디테일로 높은 분산을 나타내며 얼굴 영역을 자르고 정렬하여 머리 모션에 따라 더 많이 변경된다. 따라서 배경 정보를 높은 레벨의 semantic space로 인코딩하는 것은 매우 어려울 수 있다. 따라서 identity와 모션 feature는 동영상의 identity feature $z_\textrm{id}$와 각 프레임의 모션 feature $z_\textrm{lnd}^{(n)}$을 결합하여 높은 레벨의 semantic space $z_\textrm{face}^{(n)}$에 인코딩되고, 배경 feature는 noise map $x_T^{(n)}$에 인코딩된다. 프레임 인덱스는 시간 불변이고 동영상의 모든 프레임에서 공유되므로 위첨자 $(n)$ 없이 $z_{id}$로 표시된다.
이와 같이 분해하기 위해 본 논문의 모델은 2개의 semantic encoder인 ID encoder $E_\textrm{id}$와 landmark encoder $E_\textrm{lnd}$, 그리고 diffusion modeling을 위한 조건부 noise estimator $\epsilon_\theta$로 구성된다. 두 인코더로 인코딩된 feature $(z_\textrm{id}, z_\textrm{lnd}^{(n)})$는 concat되고 MLP를 통과하여 최종적으로 얼굴 관련 feature $z_\textrm{face}^{(n)}$을 얻는다. 그런 다음 $z_\textrm{face}^{(n)}$으로 컨디셔닝된 $\epsilon_\theta$를 사용하여 DDIM의 결정론적 forward process를 실행하여 noise map $x_T^{(n)}$로 인코딩한다. $x_T^{(n)}$이 이미지와 크기가 같은 공간 변수이므로 배경 정보를 공간 정보의 손실 없이 보다 쉽게 인코딩할 수 있을 것으로 기대된다. 그런 다음 조건부 DDIM의 reverse process로 $(x_T^{(n)}, z_\textrm{face}^{(n)})$을 원본 프레임으로 재구성한다.
\[\begin{equation} p_\theta (x_{0:T} \vert z_\textrm{face}) = p(x_T) \prod_{t=1}^T p_\theta (x_{t-1} \vert x_t, z_\textrm{face}) \end{equation}\]모션과 분리된 ID feature를 얻기 위해 ArcFace라는 ID detection을 위한 사전 학습된 모델을 활용한다. ArcFace는 포즈나 표정에 관계없이 얼굴 이미지에서 사람의 신원을 분류하도록 학습되었으므로 필요한 disentangle한 속성을 제공할 것으로 기대한다. 그럼에도 불구하고 사전 학습된 identity encoder를 통해 각 프레임에 대한 ID feature를 추출할 때 일부 프레임은 일부 이유(ex. 과도한 측면 포즈)로 부분적인 ID feature를 가질 수 있으므로 프레임별로 feature가 조금씩 다를 수 있다. 이 문제를 완화하기 위해 inference 단계에서는 ID feature를 모든 프레임에 대하여 평균을 취한다. 비슷하게 사전 학습된 landmark detection model을 활용하여 프레임당 모션 정보를 얻는다. 여러 연구에서 학습 없이 사전 학습된 encoder를 통해 추출한 feature가 충분히 disentangle함을 보였다. 따라서 사전 학습된 encoder로 ID 및 landmark feature를 추출하고 추가 MLP를 사용하여 동시에 높은 레벨의 semantic space로 매핑한다.
간단한 표현을 위해 지금부터 프레임 인덱스의 위첨자를 빼고 생각한다. 목적 함수는 두 부분을 구성된다. 하나는 DDPM loss의 simple 버전이다.
\[\begin{equation} \mathcal{L}_\textrm{simple} = \mathbb{E}_{x_0 \sim q(x_0), \epsilon_t \sim \mathcal{N}(0,I), t} \| \epsilon_\theta (x_t, t, z_\textrm{face}) - \epsilon_t \|_1 \end{equation}\]$z_\textrm{face}$는 입력 이미지 $x_0$의 인코딩된 높은 레벨의 feature이다. 이 목적 함수는 이미지의 유용한 정보가 semantic latent $z_\textrm{face}$에 충분히 포함되도록 하며 $\epsilon_\theta$의 denoising을 통해 찾는다.
두번째로, 얼굴 정보(identity와 모션)가 $x_T$로 누출되는 것을 방해하기 위해 regularization loss을 고안하지만 배경과 얼굴 정보 사이의 명확한 분해를 위해 가능한 한 $z_\textrm{face}$에 포함되어 있다. 만일 몇몇 얼굴 정보를 $z_\textrm{face}$에서 잃는다면, 잃은 정보는 nosie latent $x_T$에 의도치 않게 남게 된다. 이를 피하기 위해 서로 다른 두 Gaussian noise $\epsilon_1$과 $\epsilon_2$를 샘플링하여 서로 다른 noisy한 샘플 $x_{t,1}$과 $x_{t,2}$를 얻는다. 그런 다음 추정된 원본 이미지 $f_{\theta, 1}$과 $f_{\theta, 2}$ 사이의 거리를 배경 부분을 제외하고 최소화한다.
\[\begin{equation} \mathcal{L}_\textrm{reg} = \mathbb{E}_{x_0 \sim q(x_0), \epsilon_1, \epsilon_2 \sim \mathcal{N}(0,I), t} \|f_{\theta, 1} \odot m - f_{\theta, 2} \odot m \|_1 \\ f_{\theta, 1} = f_\theta (x_{t, 1}, t, z_\textrm{face}), \quad f_{\theta, 2} = f_\theta (x_{t, 2}, t, z_\textrm{face}) \end{equation}\]$m$은 $x_0$의 얼굴 부분에 대한 segmentation mask이다. 결과적으로 얼굴 영역에 대한 $x_t$ 안의 noise의 영향은 줄어들며 $z_\textrm{face}$는 얼굴 feature를 담당한다. 즉, 얼굴 feature는 가능한 한 높은 레벨의 semantic latent $z_\textrm{face}$에 포함하도록 권장된다. 전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{dva} = \mathcal{L}_\textrm{simple} + \mathcal{L}_\textrm{reg} \end{equation}\]2. Video Editing Framework
이제 diffusion video autoencoder를 사용한 동영상 편집 프레임워크를 설명한다. 먼저 전체 동영상 프레임 \(\{I_n\}_{n=1}^N\)을 관심있는 얼굴 영역에 대하여 정렬하고 자른다. 그런 다음 자른 프레임 \(\{x_0^{(n)}\}_{n=1}^N\)을 diffusion video autoencoder를 사용하여 latent feature로 인코딩한다.
\[\begin{equation} z_\textrm{id}^{(n)} = E_\textrm{id} (x_0^{(n)}) \end{equation}\]동영상의 표현력이 있는 identity feature를 추출하기 위해 각 프레임의 ID feature에 평균을 취한다.
\[\begin{equation} z_\textrm{id, rep} = \frac{1}{N} \sum_{n=1}^N (z_\textrm{id}^{(n)}) \end{equation}\]비슷하게 프레임당 landmark feature를 인코딩한다.
\[\begin{equation} z_\textrm{lnd}^{(n)} = E_\textrm{lnd} (x_0^{(n)}) \end{equation}\]그리고 두 feature를 MLP에 통과시켜 프레임당 얼굴 feature를 얻는다.
\[\begin{equation} z_\textrm{face}^{(n)} = MLP (z_\textrm{id, rep}, z_\textrm{lnd}^{(n)}) \end{equation}\]그런 다음 DDIM forward process를 $z_\textrm{face}^{(n)}$로 컨디셔닝하여 $x_T^{(n)}$을 계산한다. 그후에 ID space의 선형 속성 classifier 또는 텍스트 기반 최적화를 사용하여 $z_\textrm{id, rep}$에서 $z_\textrm{id, rep}^\textrm{edit}$을 편집하여 조작을 수행한다. Identity feature를 수정한 후 $(z_\textrm{face}^{(n), \textrm{edit}}, x_T^{(n)})$에 조건부 reverse process를 사용하여 $x_0^{(n), \textrm{edit}}$을 생성한다. 여기서
\[\begin{equation} z_\textrm{face}^{(n), \textrm{edit}} = MLP (z_\textrm{id, rep}^\textrm{edit}, z_\textrm{lnd}^{(n)}) \end{equation}\]이다. 그런 다음 편집된 프레임의 얼굴 영역을 원래 프레임의 해당 영역에 붙여 최종 결과를 만들어낸다. 이 프로세스의 경우, 사전 학습된 segmentation network를 사용하여 얼굴 영역을 구분한다.
다음은 저자들이 연구한 2가지 편집 방법이다.
Classifier-based editing
DiffAE와 같이 CelebA-HQ에서 linear classifier
\[\begin{equation} C_\textrm{attr} (z_\textrm{id}) = \textrm{sigmoid}(w_\textrm{attr}^\top z_\textrm{id}) \end{equation}\]를 학습시킨다. $\textrm{attr}$을 바꾸기 위해서는 scale hyperparamter $s$를 사용하여 identity feature $z_\textrm{id}$를
\[\begin{equation} l_2 \textrm{Norm} (z_\textrm{id} + sw_\text{attr}) \end{equation}\]으로 바꾸면 된다.
CLIP-based editing

사전 학습된 classifier는 몇 가지 미리 정의된 속성에 대해서만 편집할 수 있으므로 저자들은 CLIP-guidance identity feature 최적화 방법을 추가로 고안하였다. Directional CLIP loss에는 중립 텍스트와 대상 텍스트에 각각 해당하는 두 개의 이미지가 필요하다. 이는 diffusion model을 사용하여 합성된 이미지가 필요하다는 것을 의미하며, 전체 생성 프로세스의 비용이 많이 든다.
따라서, 계산 비용을 줄이기 위해 이미지 샘플링에 굉장히 감소된 step 수 $S (\ll T)$를 사용한다. 즉, $T$를 균등하게 분할한 timestep $t_1, t_2, \cdots, t_S$를 사용한다. 그리고 나서 $x_{t_S}$를 $x_0$에 대하여 계산한다. Reverse step을 통해 원본 $z_\textrm{id}$를 사용하여 각 timestep $t_s$에 대하여 \(\hat{x}_{t_s}\)를 복구한다.
그동안 $x_{t_s}^\textrm{edit}$은 \(\hat{x}_{t_{s+1}}\)에서 단일 reverse step으로 얻어지지만 변수 $z_\textrm{id}^\textrm{opt}$는 $z_\textrm{id}$로 최적화되어 초기화된다 (위 그림 참고). 마지막으로 \(\hat{x}_{t_s}\)와 $x_{t_s}^\textrm{edit}$ 사이의 directional CLIP loss를 최소화한다.
CLIP loss 계산에 추정된 $x_0$ 대신 \(\hat{x}_{t_{s+1}}\)에서 얻은 \(\hat{x}_{t_s}\)와 $x_{t_s}^\textrm{edit}$를 사용하며, 이는 $t_s$가 크면 $x_{t_s}$에서 바로 얻은 $x_0$가 불완전하고 잘못된 것이기 때문이다. 따라서, 추정된 $x_0$ 대신 보수적으로 $x_{t_{s-1}}$을 선택하면 편집 방향을 더 안정적으로 찾는 데 도움이 될 것으로 예상된다.
CLIP loss 외에도 나머지 속성을 보존하기 위해 ID loss ($z_\textrm{id}$와 $z_\textrm{id}^\textrm{opt}$ 사이의 cosine 거리)와 모든 $s$에 대한 \(\hat{x}_{t_s}\)와 $x_{t_s}^\textrm{edit}$ 사이의 $l_1$ loss도 사용한다. 결국, 학습된 편집 step $\Delta z_\textrm{id} = z_\textrm{id}^\textrm{opt} - z_\textrm{id}$는 최종 동영상 편집을 위해 $z_\textrm{id}$에 적용된다.
Experiments
세 가지 baseline과 비교하였다.
- Yao et al.: A latent transformer for disentangled face editing in images and videos
- Tzaban et al.: Stitch it in time: Gan-based facial editing of real videos
- Xu et al.: Temporally consistent semantic video editing
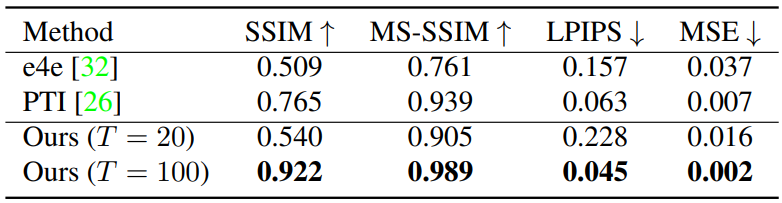
1. Reconstruction
다음은 정량적 reconstruction 결과를 나타낸 표이다.
2. Temporal Consistency
다음은 동영상 편집 성능을 정성적으로 평가하기 위해 시각적 비교를 한 것이다. (수염 추가)

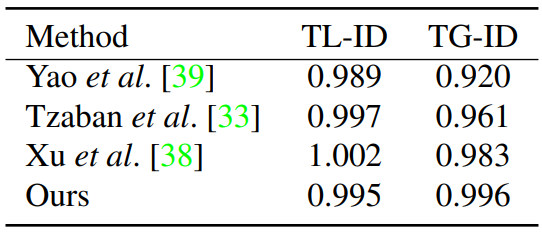
다음은 동영상 편집 성능에 대한 정량적 결과이다.
3. Editing Wild Face Videos
다음은 실제 얼굴 동영상을 편집한 것을 나타낸 것이다. Classifier 기반 편집이 사용되었으며 위는 얼굴을 어리게 편집한 것이고 아래는 성별을 바꾸도록 편집한 것이다.

4. Decomposed Features Analysis
저자들은 diffusion video autoencoder가 feature를 적합하게 분해하는 지 확인하기 위해 합성된 이미지의 각 분해된 feature를 바꿔보는 실험을 진행하였다.

5. Ablation Study
저자들은 추가로 제안된 regularization loss $\mathcal{L}_\textrm{reg}$에 대한 ablation study를 진행하였다.

![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)