






arXiv 2022. [Paper] [Github]
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, Mark Chen
OpenAI
16 Dec 2022
Introduction
최근 text-to-image 생성 모델이 폭발적으로 증가함에 따라 이제 몇 초 만에 자연어 설명에서 고품질 이미지를 생성하고 수정할 수 있다. 이러한 결과에 영감을 받아 최근 연구에서는 비디오나 3D 개체와 같은 다른 도메인에서의 텍스트 조건부 생성을 탐색했다. 본 논문에서는 가상 현실, 게임, 산업 디자인과 같은 광범위한 응용 프로그램을 위한 3D 콘텐츠 생성에 상당한 잠재력이 있는 text-to-3D 생성 문제에 특히 중점을 둔다.
Text-to-3D 합성을 위한 최근 방법은 일반적으로 다음 두 카테고리 중 하나에 속한다.
- 쌍을 이룬 (text, 3D) 데이터 또는 레이블이 없는 3D 데이터에서 생성 모델을 직접 학습시키는 방법. 이러한 방법은 기존 생성 모델링 접근 방식을 활용하여 샘플을 효율적으로 생성할 수 있지만 대규모 3D 데이터셋이 없기 때문에 다양하고 복잡한 텍스트 프롬프트로 확장하기 어렵다.
- 사전 학습된 text-to-image 모델을 활용하여 미분 가능한 3D 표현을 최적화하는 방법. 이러한 방법은 복잡하고 다양한 텍스트 프롬프트를 처리할 수 있지만 각 샘플을 생성하는 데 비용이 많이 드는 최적화 프로세스가 필요하다. 또한 강력한 3D prior가 없기 때문에 이러한 방법은 의미 있거나 일관된 3D 개체에 해당하지 않는 local minima에 빠질 수 있다.
본 논문은 text-to-image 모델과 image-to-3D 모델을 결합하여 두 카테고리의 이점을 결합하는 것을 목표로 한다. Text-to-image 모델은 (text, image) 쌍의 대규모 corpus를 활용하여 다양하고 복잡한 프롬프트를 따를 수 있도록 하는 반면, image-to-3D 모델은 (image, 3D) 쌍의 더 작은 데이터셋에서 학습된다. 텍스트 프롬프트에서 3D 개체를 생성하려면 먼저 text-to-image 모델을 사용하여 이미지를 샘플링한 다음 샘플링된 이미지에 따라 3D 개체를 샘플링한다. 이 두 단계는 모두 몇 초 안에 수행할 수 있으며 비용이 많이 드는 최적화 절차가 필요하지 않다. 아래 그림은 이 2단계 생성 프로세스를 보여준다.
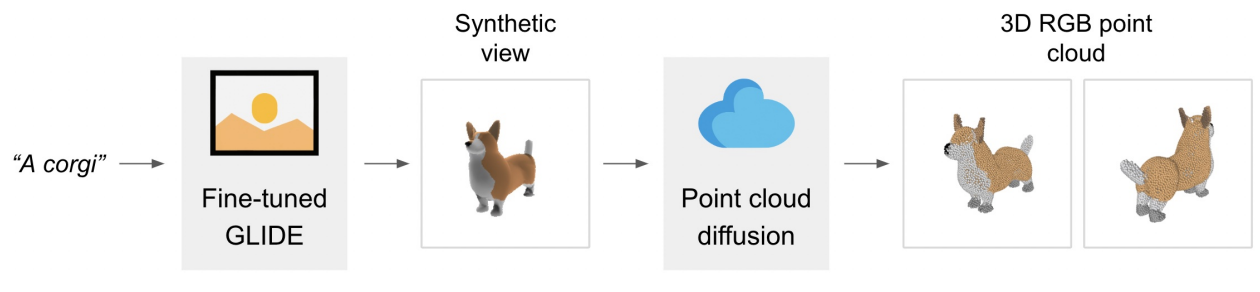
텍스트 조건부 이미지 생성을 위한 인기 있는 선택이 된 diffusion model에 생성 stack을 기반으로 한다. Text-to-image 모델의 경우 3D 렌더링에서 fine-tuning된 GLIDE 버전을 사용한다. Image-to-3D 모델의 경우 이미지에 따라 조절되는 RGB point cloud를 생성하는 diffusion model stack을 사용한다. 렌더링 기반 평가를 위해 한 단계 더 나아가 regression 기반 접근 방식을 사용하여 생성된 point cloud에서 mesh를 생성한다.
저자들은 본 논문의 시스템이 단순하고 복잡한 텍스트 프롬프트와 일치하는 컬러 3D point cloud를 생성할 수 있음을 발견했다. Point cloud를 효율적으로 (efficiently) 생성하므로 본 논문의 시스템을 Point·E라고 부른다.
Method
단일 생성 모델을 학습시켜 텍스트 조건의 point cloud를 직접 생성하는 대신 생성 프로세스를 세 단계로 나눈다. 먼저 텍스트 캡션을 조건으로 하는 합성 view를 생성합니다. 다음으로 합성 view에 따라 coarse point cloud (1,024개)를 생성한다. 마지막으로 저해상도 point cloud와 합성 view를 기반으로 fine point cloud (4,096개)를 생성한다. 실제로 이미지에 텍스트의 관련 정보가 포함되어 있다고 가정하고 point cloud를 텍스트로 컨디셔닝하지 않는다.
텍스트 조건부 합성 view를 생성하기 위해 데이터셋에서 렌더링된 3D 모델에 fine-tuning된 30억 개의 파라미터의 GLIDE 모델을 사용한다. 저해상도 point cloud를 생성하기 위해 조건부 순열 불변 diffusion model을 사용한다. 이러한 저해상도 point cloud를 upsampling하기 위해 저해상도 point cloud에서 추가로 컨디셔닝되는 유사하지만 더 작은 diffusion model을 사용한다.
수백만 개의 3D 모델과 관련 메타데이터 데이터 셋에서 모델을 학습시킨다. 데이터 셋은 렌더링된 뷰, 텍스트 설명, 각 point에 대해 연결된 RGB 색상이 있는 3D point cloud로 구성된다.
1. Dataset
수백만 개의 3D 모델로 모델을 학습시킨다. 데이터 형식과 품질이 데이터셋 전체에서 매우 다양하다는 것을 알게 되었고 더 높은 데이터 품질을 보장하기 위해 다양한 후처리 단계를 개발해야 했다고 한다. 모든 데이터를 하나의 일반 형식으로 변환하기 위해 다양한 3D 형식과 최적화된 렌더링 엔진을 지원하는 Blender를 사용하여 20개의 임의의 카메라 각도에서 RGBAD 이미지로 모든 3D 모델을 렌더링했다. 각 모델에 대해 Blender 스크립트는 모델을 경계 큐브로 정규화하고 표준 조명 설정을 구성한 다음 마지막으로 Blender의 내장 실시간 렌더링 엔진을 사용하여 RGBAD 이미지를 내보낸다.
그런 다음 렌더링을 사용하여 각 개체를 color point cloud로 변환한다. 특히 각 RGBAD 이미지의 각 픽셀에 대한 point를 계산하여 각 개체에 대한 조밀한 point cloud를 먼저 구성했다. 이러한 point cloud는 일반적으로 고르지 않은 간격의 수십만 개의 point를 포함하므로 farthest point sampling을 추가로 사용하여 균일한 4096개의 point cloud를 생성했다. 렌더에서 직접 point cloud를 구성함으로써 3D mesh에서 직접 point를 샘플링하려고 시도할 때 발생할 수 있는 다양한 문제를 피할 수 있었다고 한다.
마지막으로 저자들은 데이터셋에서 저품질 모델의 빈도를 줄이기 위해 다양한 휴리스틱을 사용했다. 먼저 각 point cloud의 SVD를 계산하고 가장 작은 특이값이 특정 임계값을 초과하는 항목만 유지하여 평평한 개체를 제거했다. 다음으로 CLIP feature로 데이터셋을 클러스터링했다. 일부 클러스터에는 저품질의 모델이 많이 포함되어 있는 반면 다른 클러스터는 더 다양하거나 해석 가능해 보였다. 저자들은 이러한 클러스터를 다양한 품질의 여러 bucket으로 binning하고 결과 bucket의 가중 혼합을 최종 데이터셋으로 사용했다.
2. View Synthesis GLIDE Model
Point cloud model은 모두 동일한 렌더러와 조명 설정을 사용하여 생성된 데이터셋의 렌더링된 view로 컨디셔닝된다. 따라서 이러한 모델이 생성된 합성 view를 올바르게 처리할 수 있도록 데이터셋 분포와 일치하는 3D 렌더링을 명시적으로 생성하는 것을 목표로 한다.
이를 위해 원본 데이터셋과 3D 렌더링 데이터셋을 혼합하여 GLIDE를 fine-tuning한다. 본 논문의 3D 데이터셋는 원래 GLIDE 학습셋에 비해 작기 때문에 3D 데이터셋의 이미지를 5%만 샘플링하고 나머지 95%는 원래 데이터셋을 사용한다. 10만 iteration으로 fine-tuning하며, 이는 모델이 3D 데이터셋에 대해 여러 epoch을 만들었다는 의미이다 (그러나 정확히 동일한 렌더링된 view를 두 번 본 적은 없음).
시간의 5%만 샘플링하는 것이 아니라 in-distribution 렌더를 항상 샘플링하기 위해 모든 3D 렌더의 텍스트 프롬프트에 3D 렌더임을 나타내는 특수 토큰을 추가한다. 그런 다음 테스트 시에 이 토큰으로 샘플링한다.
3. Point Cloud Diffusion
Diffusion으로 point cloud를 생성하기 위해 3D Shape Generation and Completion through Point-Voxel Diffusion이 사용한 프레임워크를 확장하여 point cloud의 각 point에 RGB 색상을 포함한다. 특히 point cloud를 $K \times 6$ 모양의 텐서로 표현한다. 여기서 $K$는 point의 수이고 6은 $(x, y, z)$ 좌표와 $(R, G, B)$ 색상이 포함된다. 모든 좌표와 색상은 $[-1, 1]$ 범위로 정규화된다. 그런 다음 $K \times 6$ 모양의 random noise에서 시작하여 점진적으로 denoise하여 이러한 텐서를 직접 생성한다.
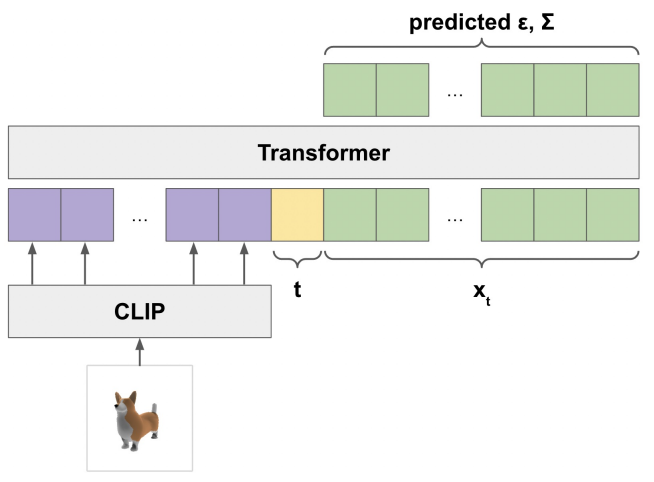
Point cloud를 처리하기 위해 3D에 특화된 아키텍처를 활용하는 이전 연구들과 달리 간단한 Transformer 기반 모델을 사용하여 이미지, timestep $t$, noise가 있는 point cloud $x_t$를 조건으로 $\epsilon$과 $\Sigma$를 예측한다. 아키텍처의 개요는 위 그림과 같다. Point cloud의 각 point를 출력 차원이 $D$인 linear layer에 넣어 $K \times D$ 입력 텐서를 얻고 모델에 입력 컨텍스트로 제공한다. 또한 작은 MLP에 timestep $t$를 넣어 컨텍스트 앞에 추가할 다른 $D$차원 벡터를 얻는다.
ViT-L/14 CLIP 모델은 이 CLIP 모델에서 모양이 $256 \times D’$인 마지막 layer embedding을 가져와 Transformer 컨텍스트에 추가하기 전에 $256 \times D$의 다른 텐서에 선형으로 project한다. 최종 입력 컨텍스트는 모양이 $(K + 257) \times D$이다. 길이 $K$의 최종 출력 시퀀스를 얻기 위해 출력의 최종 토큰 $K$개를 가져오고 이를 project하여 입력 point $K$개에 대한 $\epsilon$과 $\Sigma$ 예측을 얻는다. 이 모델에는 위치 인코딩을 사용하지 않는다. 출력 순서가 입력 순서에 연결되어 있음에도 불구하고 결과적으로 모델 자체는 입력 point cloud에 대해 순열 불변이다.
4. Point Cloud Upsampler
이미지 diffusion model의 경우 일반적으로 저해상도 base model이 출력을 생성한 다음 다른 모델에 의해 upsampling되는 일종의 계층 구조를 사용하여 최상의 품질을 얻을 수 있다. 먼저 큰 base model로 1024개의 point를 생성한 다음 더 작은 upsampling model을 사용하여 4096개의 point로 upsampling하여 point cloud 생성에 이 접근 방식을 사용한다. 특히 모델의 컴퓨팅 요구 사항은 point 수에 따라 확장되므로 고정된 모델 크기에 대해 1024개의 point보다 4096개의 point를 생성하는 것이 4배 더 비싸다.
Upsampler는 base model과 동일한 아키텍처를 사용하며 저해상도 point cloud를 위한 추가 컨디셔닝 토큰이 있다. 4096개의 point에 도달하기 위해 upsampler는 1024개의 point를 조건으로 하여 저해상도 point cloud에 추가되는 추가 3072개의 point를 생성한다. $x_t$에 사용된 layer가 아닌 별도의 linear embedding layer를 통해 컨디셔닝 point를 전달하므로 모델이 위치 임베딩을 사용하지 않고도 컨디셔닝 정보를 새 point와 구별할 수 있다.
5. Producing Meshes
렌더링 기반의 평가를 위해 생성된 point cloud를 직접 렌더링하지 않는다. 오히려 point cloud를 textured mesh로 변환하고 Blender를 사용하여 이러한 mesh를 렌더링한다. Point cloud에서 mesh를 생성하는 것은 잘 연구된 문제이며 때로는 어려운 문제이다. 모델에서 생성된 point cloud에는 문제를 특히 어렵게 만드는 균열, 이상값, 기타 유형의 noise가 있는 경우가 많다. 저자들은 이를 위해 사전 학습된 SAP 모델을 사용하여 간단히 시도해보았지만, 결과 mesh가 때때로 point cloud에 있는 모양의 많은 부분이나 중요한 디테일을 잃는다는 것을 발견했다. 저자들은 새로운 SAP 모델을 학습하는 대신 더 간단한 접근 방식을 선택했다.
Point cloud를 mesh로 변환하기 위해 regression 기반 모델을 사용하여 point cloud가 주어진 개체의 signed distance field를 예측한 다음 marching cube를 결과 SDF에 적용하여 mesh를 추출한다. 그런 다음 원래 point cloud에서 가장 가까운 point의 색상을 사용하여 mesh의 각 정점에 색상을 지정한다.
Results
Point cloud의 Inception Score와 FID를 측정한 P-IS와 P-FID라는 새로운 metric 2가지를 도입하였다. 추가로 text-to-3D 방법을 평가하는 데 사용하는 CLIP R-Precision도 사용하였다.
1. Model Scaling and Ablations
저자들은 다음과 같은 base model에 대하여 학습 중에 생성한 샘플들로 평가하였다.
- 40M (uncond.): 컨디셔닝 정보가 없는 작은 모델
- 40M (text vec.): CLIP으로 임베딩된 텍스트 캡션만으로 컨디셔닝된 작은 모델
- 40M (image vec.): 렌더링된 이미지의 CLIP image embedding으로 컨디셔닝된 작은 모델
- 40M: CLIP latent grid로 컨디셔닝된 작은 모델
- 300M: CLIP latent grid로 컨디셔닝된 중간 모델
- 1B: CLIP latent grid로 컨디셔닝된 큰 모델
평가 결과는 아래 그래프와 같다.
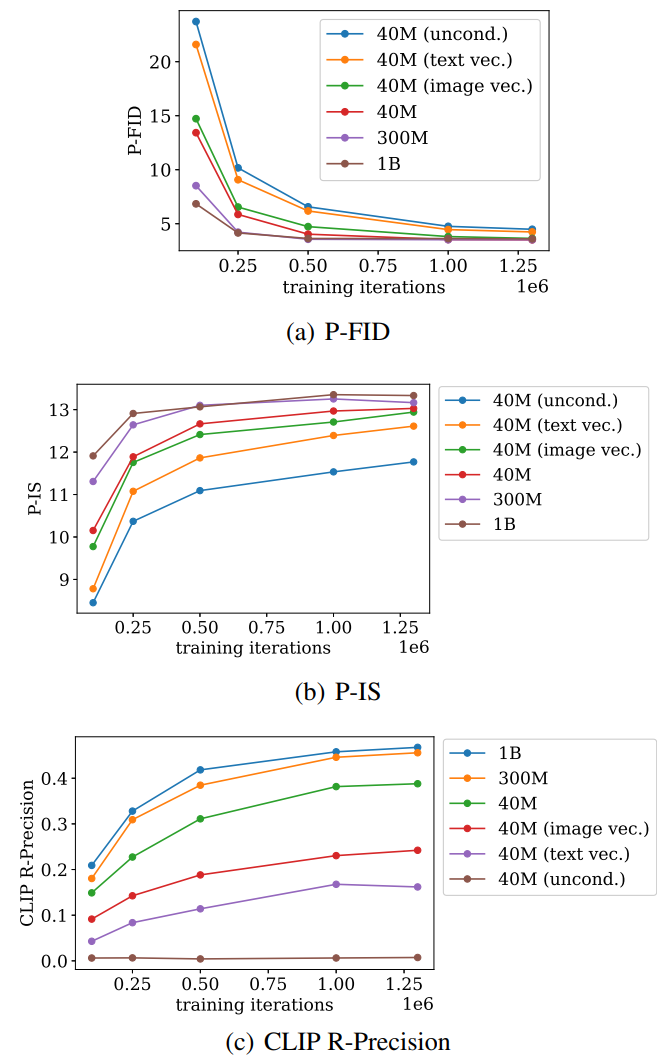
Text-to-image step 없이 텍스트 컨디셔닝만 사용하면 CLIP R-Precision이 훨씬 나빠진다. 또한 단일 CLIP embedding을 사용하여 이미지를 컨디셔닝 것이 embedding grid를 사용하는 것보다 나쁘다. 이는 point cloud model이 컨디셔닝 이미지에 대한 더 많은 공간적 정보를 볼 수 있다는 이점이 있음을 시사한다. 마지막으로 모델을 스케일링하면 P-FID 수렴 속도가 향상되고 최종 CLIP R-Precision이 증가한다.
2. Qualitative Results

Point·E는 복잡한 프롬프트를 위해 일관되고 고품질의 3D 모양을 생성할 수 있다. 위 그림에서는 모양의 관련 부분에 색상을 올바르게 바인딩하면서 다양한 모양을 추론하는 모델의 능력을 보여주는 다양한 point cloud 샘플을 보여준다.

때로는 point cloud diffusion model이 컨디셔닝 이미지를 이해하거나 외삽(extrapolate)하지 못하여 모양이 원래 프롬프트와 일치하지 않는 경우가 있다. 이는 일반적으로 두 가지 문제 중 하나 때문입이다.
- 모델이 이미지에 묘사된 개체의 모양을 잘못 해석한 경우
- 모델이 이미지에서 가려진 모양의 일부를 잘못 추론하는 경우
위 그림은 이 2가지 경우의 failure mode의 예시이다.
3. Comparison to Other Methods
다음은 CLIP-R-Precision을 측정하여 Point·E를 다른 3D 생성 테크닉과 비교한 표이다.
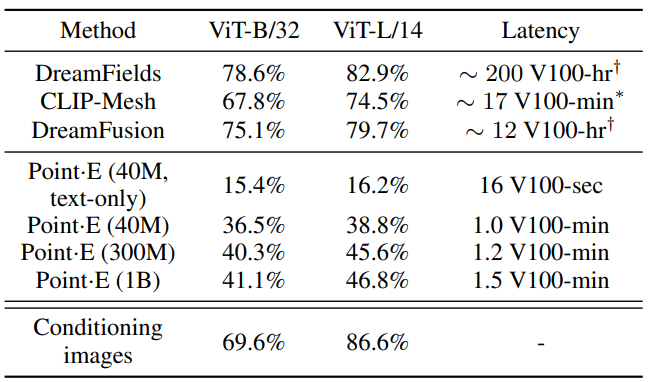
Point·E는 state-of-the-art 테크닉보다 성능이 좋지 않지만, 이 불일치의 일부를 설명할 수 있는 이 평가의 두 가지 미묘한 점에 주목해야 한다.
- DreamFusion과 같은 multi-view 최적화 기반 방법과 달리 Point·E는 텍스트 프롬프트와 일치하도록 모든 view를 명시적으로 최적화하지 않는다. 특정 물체는 모든 각도에서 식별하기 쉽지 않기 때문에 단순히 CLIP R-Precision이 낮아질 수 있다.
- 본 논문의 방법은 렌더링 전에 사전 처리되어야 하는 point cloud를 생성한다. Point cloud를 mesh로 변환하는 것은 어려운 문제이며 본 논문이 사용하는 접근 방식은 때때로 point cloud 자체에 있는 정보를 잃을 수 있다.
Point·E는 최신 테크닉보다 이 평가에서 성능이 좋지 않지만 짧은 시간 내에 샘플을 생성한다. 이를 통해 보다 실용적으로 응용 프로그램을 만들거나 많은 개체를 샘플링하고 최상의 개체를 휴리스틱을 따라 선택하여 고품질 3D 개체를 찾을 수 있다.
Limitations and Future Work
Point·E는 빠른 text-to–3D 합성을 향한 의미 있는 발걸음이지만 몇 가지 제한 사항도 있다. 현재 본 논문의 파이프라인에는 합성 렌더링이 필요하지만 이 제한은 실제 이미지를 조건으로 하는 3D 생성기를 학습함으로써 향후 제한이 사라질 수 있다. 또한 색상이 있는 3차원 모양을 생성하지만 세밀한 모양이나 질감을 캡처하지 않는 3D 형식(point cloud)에서 상대적으로 낮은 해상도로 수행한다. 이 방법을 확장하여 mesh나 NeRF와 같은 고품질 3D 표현을 생성하면 모델의 출력을 다양한 애플리케이션에 사용할 수 있다. 마지막으로 최적화 기반 기술을 초기화하여 초기 수렴 속도를 높이는 데 사용할 수 있다. 또한 저자들은 많은 편향이 데이터셋에서 상속되는 DALL·E 2와 같은 편향을 이 모델이 포함하여 많은 제한 사항을 공유할 것으로 예상한다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)