






arXiv 2023. [Paper] [Github]
Roy Hachnochi, Mingrui Zhao, Nadav Orzech, Rinon Gal, Ali Mahdavi-Amiri, Daniel Cohen-Or, Amit Haim Bermano
Tel Aviv University | Simon Fraser University
20 Feb 2023

Introduction
주어진 시각적 prior에서 새로운 장면을 구성하는 능력은 컴퓨터 그래픽 분야에서 오랜 과제이다. 목표는 하나 이상의 이미지에서 개체를 추출하여 새로운 장면에 접목하는 것이다. 이 과제는 이미 어려운 작업으로, 일관된 조명과 부드러운 전환으로 새로운 물체가 장면과 조화를 이루어야 한다. 그러나 구성 요소가 서로 다른 시각적 도메인에서 시작되는 경우 더욱 문제가 악화된다. 이러한 경우 콘텐츠를 손상시키지 않고 새 도메인의 스타일과 일치하도록 객체를 추가로 변형해야 한다.
본 논문은 diffusion 기반 생성 모델을 활용하여 도메인 간 합성 task를 해결할 것을 제안한다. Diffusion model은 최근 이미지 합성 및 조작 task에서 놀라운 발전을 이루었다. 사전 학습된 diffusion model은 종종 이미지 콘텐츠를 보존하면서 현실감과 일관성을 보장할 수 있는 강력한 시각적 prior 역할을 한다. 여기에서 저자들은 diffusion model을 사용하여 새로운 장면에 도메인 간 객체를 자연스럽게 주입하는 것을 목표로 한다.
본 논문의 접근 방식은 두 가지 목표를 달성하는 것을 목표로 한다.
- 시각적 입력을 기반으로 이미지의 local한 변경을 유도할 수 있어야 한다.
- 주변 장면에 더 잘 몰입할 수 있도록 입력의 사소한 변화를 허용해야 한다.
이상적으로는 이러한 변경 사항을 제어할 수 있어야 사용자가 보존하려는 유사성의 유형과 정도를 지정할 수 있다. Diffusion 기반 inpainting과 조건부 guidance의 최근 연구를 확장하여 이러한 목표를 해결한다. 주어진 컨디셔닝 입력에서 제어 가능한 수준의 정보가 이미지의 localize된 영역에 주입되는 반복적인 inference-time 컨디셔닝 방식을 제안한다.
METHOD
1. Preliminaries
\[\begin{equation} p_\theta (x_{t-1} \vert x_t) = \mathcal{N} (\mu_\theta (x_t, t), \sigma_t I) \\ \mu_\theta (x_t, t) = \frac{1}{\sqrt{\alpha_t}} \bigg( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta (x_t, t) \bigg) \\ \hat{x}_0 = \frac{x_t}{\sqrt{\vphantom{1} \bar{\alpha}_t}} - \frac{\sqrt{1 - \bar{\alpha}_t} \epsilon_\theta(x_t, t)}{\sqrt{\vphantom{1} \bar{\alpha}_t}} \\ q (x_t \vert x_{t-1}) = \mathcal{N} (\sqrt{1 - \sigma_t} x_{t-1}, \sigma_t I) \\ x_t = \sqrt{\vphantom{1} \bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \end{equation}\]자세한 내용은 DDPM Paper review 참고
2. Masked ILVR
본 논문의 목표는 서로 다른 시각적 도메인의 부분을 포함하는 합성 이미지를 만드는 것이다. 이를 위해서는 객체의 구조를 유지하면서 외형을 변경할 수 있는 방법이 필요하다. 또한 이 방법은 사실적인 블렌딩과 같은 다른 합성 요구 사항을 이상적으로 해결해야 한다.
본 논문은 사전 학습된 diffusion model을 활용하여 inference-time에 이러한 모든 요구 사항을 한 번에 해결할 것을 제안한다. 외부 이미지 입력에 대한 생성을 컨디셔닝하기 위해 ILVR을 활용한다. ILVR에서 각 denoising step에 대해 diffusion model은 먼저
\[\begin{equation} x_{t-1}' \sim p_\theta (x_{t-1}' \vert x_t) \end{equation}\]을 예측한다. 이 $x_{t-1}’$은 다음과 같은 업데이트 규칙을 통해 컨디셔닝 이미지의 저주파수 데이터를 사용하여 정제된다.
\[\begin{equation} x_{t-1} = \phi (y_{t-1}) + (I - \phi) (x_{t-1}') \\ x_{t-1} = x_{t-1}' + \phi (y_{t-1}) - \phi (x_{t-1}') \\ y_{t-1} \sim q(y_{t-1} \vert y_0) \end{equation}\]$\phi$는 low-pass filter 연산이다. 실제로 $\phi$는 scaling factor $N$의 bi-linear down-sampling 및 up-sampling step을 통해 구현된다. 이 정제 연산은 사용자가 정한 threshold $T_{stop}$까지 각 diffusion step마다 반복되며, 그 다음부터는 guidance 없이 denoising이 진행된다.
이 두 파라미터 $N$과 $T_{stop}$은 레퍼런스 이미지와의 유사성에 대한 제어 권한을 부여한다. 직관적으로 더 큰 $N$과 더 큰 $T_{stop}$은 더 적은 step으로 더 낮은 주파수가 재정의되기 때문에 컨디셔닝 이미지에 대한 더 높은 다양성을 가져오지만 fidelity가 낮아진다. 따라서 이러한 파라미터는 레퍼런스 이미지에 대한 fidelity와 현실감 사이의 고유한 trade-off를 제어한다. 저자들은 사용자에게 이 trade-off에 대한 로컬 제어를 제공하는 것을 목표로 한다.
Localize된 편집에 ILVR을 활용하기 위해 $N$과 $T_{stop}$을 개별적으로 제어할 수 있는 local mask 내부에 적용하고 싶지만 ILVR은 global한 방식으로 디자인되었으며 이를 local하게 적용하려고 시도하면 아티팩트가 생긴다. (아래 그림 참고)

저자들은 이러한 아티팩트가 이미지에 급격한 변화를 시도할 때 나타나는 것을 관찰하였으며 중간 생성 ff-manifold를 유도한다. 저자들은 이것이 영역 간의 급격한 전환에서 비롯된 주파수 앨리어싱의 결과라고 가정한다. 따라서 이러한 장애물을 극복하기 위해 ILVR을 다음과 같이 수정할 것을 제안한다.
Localizing the control
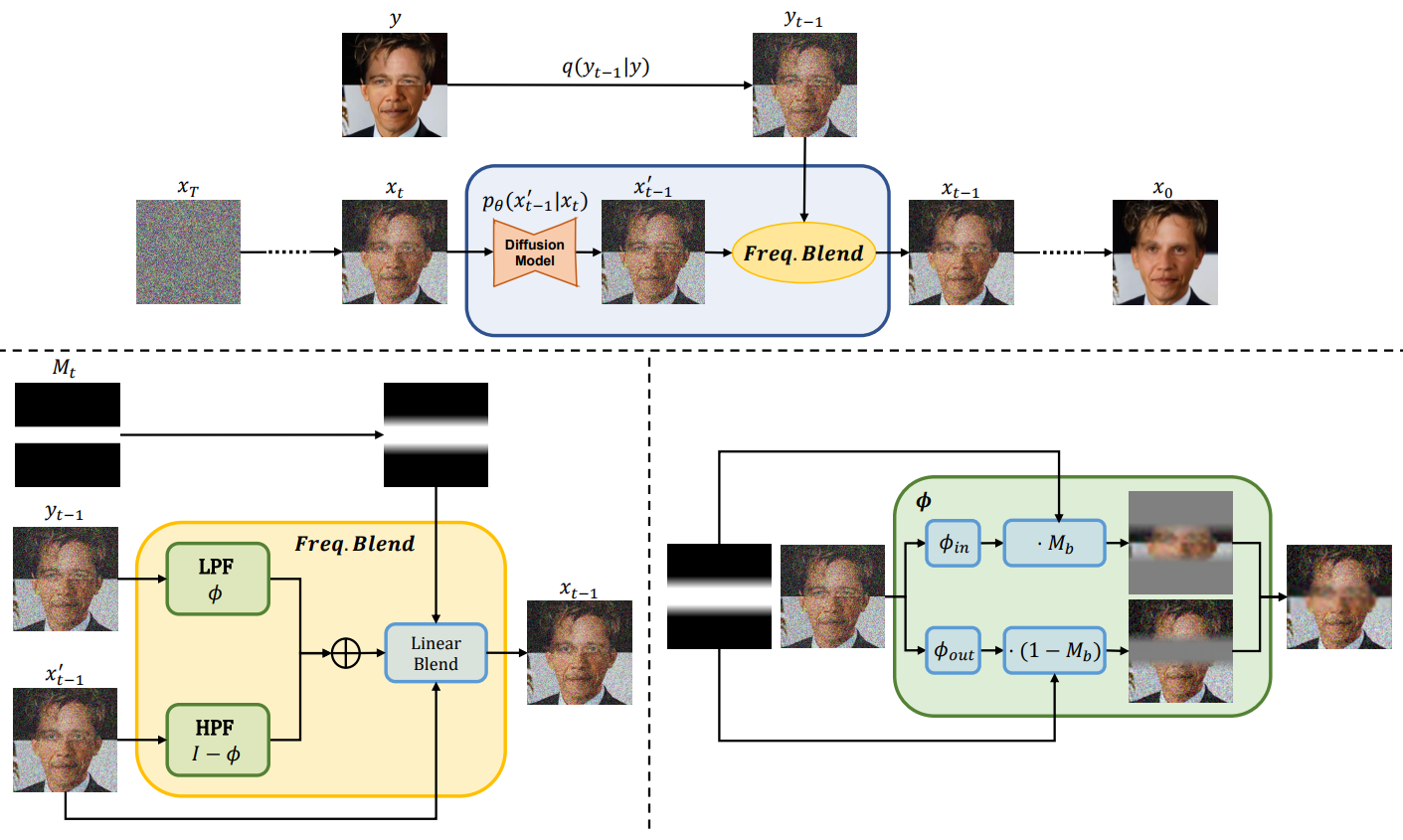
로컬 제어를 허용하기 위해 ILVR 프로세스를 별도의 이미지 영역으로 분리할 것을 제안한다. 본 논문의 로컬 제어 guidance 방법은 위 그림에 설명되어 있다. 레퍼런스 이미지 $y \in \mathbb{R}^{H \times W \times C}$와 mask $M \in [0, 1]^{H \times W}$가 주어지면 사용자는 low-pass filter $\phi_{in}$, $\phi_{out}$을 위한 $N_{in}$, $N_{out}$을 정의하고 영역별 ILVR 강도를 $T_{in}$, $T_{out}$으로 정의한다. 먼저 선형 low-pass filtering 연산을 다음과 같이 정의한다.
$M_b$는 blending mask이다. ILVR에서 이 연산은 guidance를 위해 사용되지만 여기에 mask $M_t$를 도입하여 guidance 강도에 대한 로컬 제어를 추가한다.
\[\begin{equation} x_{t-1} = x_{t-1}' + M_t (\phi(y_{t-1}) - \phi(x_{t-1}')) \end{equation}\]Blending mask $M_b$와 time mask $M_t$는 다음과 같다.
\[\begin{equation} M_b = M \\ M_T = (1 - T_{in}) T \cdot M + (1 - T_{out}) T \cdot (1 - M) \\ M_t^{(i,j)} (t) = \begin{cases} 0 & : t < M_T^{(i, j)} \\ 1 & : t \ge M_T^{(i, j)} \end{cases} \end{equation}\]$T$는 diffusion step의 전체 수이다. 예를 들어, $T_{in} = 0.2$, $T_{out} = 1$로 두면 mask 내부는 diffusion step의 20%에서 ILVR-guidance를 수행하고 mask 외부는 100%에서 수행한다. 이 time-schedule 분리를 도입하면 영역별 ILVR의 강도를 제어할 수 있어 사용자가 영역별 fidelity-realism trade-off를 조정할 수 있는 동시에 $N_{in}$, $N_{out}$ 값을 설정하여 영역별 ILVR의 양을 추가로 제어할 수 있다. 이 제어 방법은 latent space가 pixel space와 공간적 일관성을 갖는 경우 latent diffusion model에도 적용될 수 있다. 이러한 경우 latent space에서의 low-pass filtering은 pixel space에서의 filtering과 동일하다.
Overcoming the aliasing artifacts
앞서 언급한 바와 같이 Guided Diffusion과 같은 pixel space diffusion model의 경우 제안된 방법이 결과 이미지에 부자연스러운 아티팩트를 유발한다. Latent-space diffusion model에서는 이 효과가 덜 관찰되며, 이러한 효과에 대처할 수 있는 latent decoder의 능력 때문이다. 이러한 제한을 완화하기 위해 두 가지 방법을 제안한다.
첫째, $x_t$ 대신 $\tilde{x}_0$-space에 공식들을 적용할 것을 제안한다. 이렇게 하면 low-pass filter $\phi$가 이미지에만 적용되고 노이즈에는 적용되지 않는다. 이 방법은 각 timestep에 적절한 noise 레벨을 유지하여 앨리어싱 효과를 해결한다.
둘째, mask $M_b$, $M_t$에 적용할 smoothing 연산자 $b(M)$을 추가하여 mask를 스무딩할 것을 제안한다. 이 방법은 이미지의 서로 다른 영역 간의 전환을 부드럽게 하여 앨리어싱 효과를 극복한다. 실제로는 $N_{in}$, $N_{out}$과 관련된 요인으로 mask를 흐리게 하는 것이 적절하다는 것을 알 수 있다. 이 방법은 서로 다른 이미지 영역 간에 noise 레벨을 부드럽게 전환하여 앨리어싱 효과를 줄인다.
저자들은 첫 번째 방법이 중간 diffusion step에서 그럴듯한 $\tilde{x}_0$ 이미지를 예측할 수 있는 모델을 사용할 때 더 잘 작동한다는 것을 발견했다. 저자들은 이것이 레퍼런스 이미지와 예측 사이를 의미 있게 보간하는 능력과 관련이 있다고 가정한다. 예측이 영역을 벗어난 경우 보간으로 인해 이미지가 저하되고 의미 없는 guidance가 생성된다. 이 경우 다음의 방법을 사용하는 것이 좋다.
Local editing as guided inpainting
레퍼런스 이미지에 의해 guidance가 수행되는 이미지 inpainting task의 guide된 변형으로 본 논문의 방법을 이해할 수 있다. 객체와 배경을 변경하거나 구조를 잃지 않고 더 많은 도메인 간 정보를 주입하고 싶지만 정보 교환 속도는 denoiser의 receptive field에 의해 제한된다. RePaint는 denoising step을 반복하는 것만으로도 그러한 효과를 얻을 수 있음을 보여주었고, 따라서 유사한 접근 방식을 사용한다. 사용할 수 있는 경우 전용 inpainting 모델도 사용할 수 있지만 주어진 시각적 개체로 inpainting을 수행하도록 디자인되지 않았지만 본 논문의 방법은 수행한다.
Applications and Evaluation
1. Image Modification via Scribbles
다음은 낙서 guidance를 사용한 로컬 이미지 편집을 정성적으로 비교한 것이다. 텍스트 프롬프트는 위에서부터 a corgi wearing a business suit, a cat reading a book, a living room with a sofa and a table, a sofa with pillows이다.
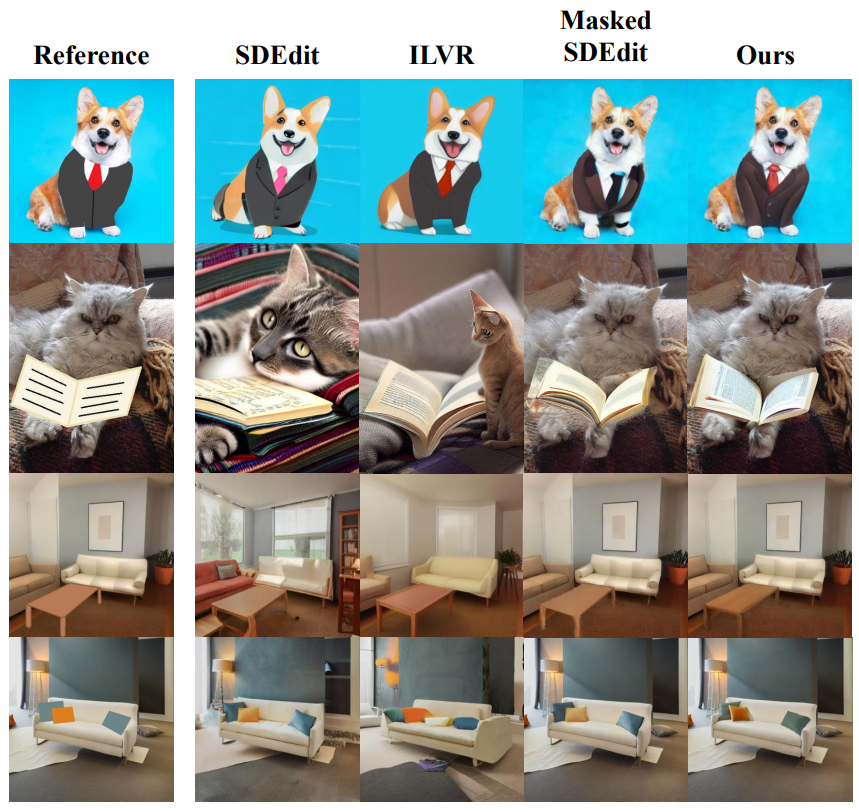
각 방법에 대해 parameter sweep을 실행하고 경험적으로 최상의 결과를 선택한다. 다른 방법들은 배경을 유지하거나 낙서를 사실적인 개체로 변경하는 데 실패한다. 특히 본 논문의 방법은 양복의 주름과 단추 또는 베개의 그림자와 질감과 같이 낙서에 추가된 고주파수 디테일이 추가된다.
2. Object Immersion
다음은 object immersion을 비교한 것이다.

본 논문의 방법은 보다 적절한 스타일 일치를 보여주며 개체는 그대로 두고 배경과 일치하도록 만든다.
다음은 참가자들이 입력 이미지와 함께 한 쌍의 결과를 제시받고 개체가 배경에 더 잘 맞는 결과를 선택하도록 요청받았을 때 다른 방법보다 본 논문 방법을 선호하는 답변의 비율을 나타낸 것이다.

3. Single-view 3D Reconstruction (SVR)
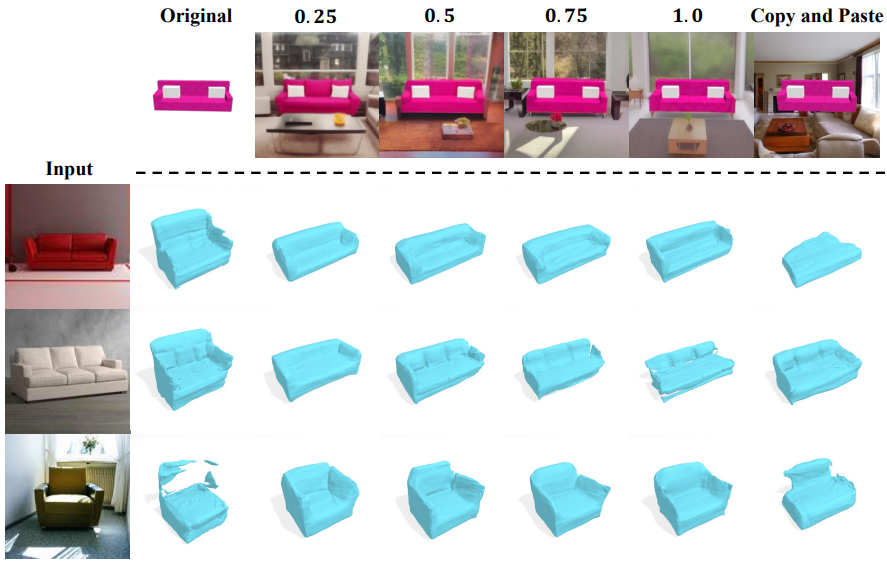
다음은 다양한 포즈에서 ShapeNet 개체에 대한 배경 augmentation 결과이다. 맨 윗줄은 입력 이미지이고 나머지는 배경이 추가된 다양한 이미지이다.

기하학적으로 일관된 배경이 생성되는 동시에 개체가 보다 사실적으로 보이도록 변경한다.
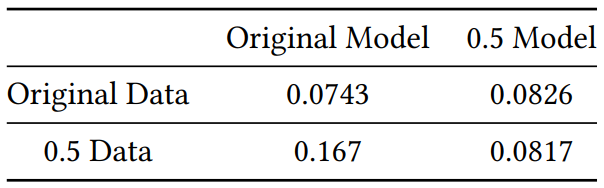
다음은 다양한 데이터셋에서 SVR 모델의 Chamfer $L_1$ distance를 평가한 것이다. Original Model은 오리지널 데이터셋으로 학습한 모델이고 0.5 Model은 $T_{in} = 0.5$인 데이터셋으로 학습한 모델이다.
다음은 다양한 데이터셋에서 학습된 D²IMNet의 SVR 결과이다.
다음은 다양한 데이터셋에서 학습된 모델의 2D IoU를 평가한 것이다. 맨 윗줄의 숫자는 배경 augmentation에 사용된 $T_{in}$의 값을 나타낸다. CP는 copy-paste 데이터셋을 의미한다.

4. Parameter Ablation
다음은 파라미터의 영향을 나타낸 그림이다.

Limitations
다음 그림은 다양한 failure case들을 보여준다.

- (1): 어렵고 디테일한 객체
- (2): 어려운 시점을 제공하여 모델이 semantic을 이해하기 어려운 경우
- (3): 작고 디테일한 객체
- (4): 도메인 밖의 컨텐츠
본 논문의 방법의 주요 한계는 작은 물체의 사용에서 비롯된다. 저해상도 latent space에서 작업하는 것은 모델이 디테일을 보존하는 능력을 방해하므로 모델이 물체를 더럽힐 뿐이다. 이 제한점은 mask 크기와 관련하여 적절한 파라미터를 조정하여 해결할 수 있을 것으로 기대한다.
또 다른 결함은 diffusion model이 주입된 객체를 의미상 적절한 클래스에 귀속시키는 데 실패할 때 발생한다. 이는 비표준 모델이나 어려운 시점을 제공하는 경우와 같이 레퍼런스 이미지에 까다로운 개체가 포함되어 있을 때 발생할 수 있다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)