






arXiv 2022. [Paper]
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, Yaniv Taigman
Meta AI
29 Sep 2022

Introduction
수십억 개의 텍스트-동영상 데이터셋을 쉽게 수집할 수 없기 때문에 동영상에 대한 성공은 제한적이다. 이미지를 생성할 수 있는 모델이 이미 존재하는데 처음부터 T2V(Text-to-Video) 모델을 학습시키는 것은 낭비이다. 또한 비지도 학습을 통해 신경망은 훨씬 더 많은 데이터를 학습할 수 있다. 이 많은 양의 데이터는 세계에서 더 미묘하고 덜 일반적인 개념의 표현을 학습하는 데 중요하다. 비지도 학습은 오랫동안 자연어 처리(NLP) 분야를 발전시키는 데 큰 성공을 거두었다. 이러한 방식으로 사전 학습된 모델은 supervised 방식으로 단독으로 학습된 경우보다 훨씬 더 높은 성능을 보인다.
본 논문은 이러한 것들에 영감을 받아 Make-A-Video를 제안한다. Make-A-Video는 T2I 모델을 활용하여 텍스트와 비전 간의 대응 관계를 학습하고 레이블이 없는 동영상 데이터에 대한 비지도 학습을 사용하여 사실적인 동작을 학습한다. 또한 Make-A-Video는 쌍으로 된 텍스트-동영상 데이터를 활용하지 않고 텍스트에서 동영상을 생성한다.
이미지를 설명하는 텍스트는 동영상에서 관찰되는 현상을 모두 캡처하지 않는다. 즉, 이미지 기반 동작 인식 시스템에서와 같이 정적 이미지에서 동작 및 이벤트를 추론할 수 있는 경우가 많다. 또한 텍스트 설명이 없더라도 supervise되지 않은 동영상은 현실의 다양한 개체가 어떻게 움직이고 상호 작용하는지 (ex. 해변의 파도 움직임, 코끼리 코의 움직임)를 학습하는 데 충분하다. 결과적으로 이미지를 설명하는 텍스트만 본 모델은 시간적 diffusion 기반 방법에서 입증된 것처럼 짧은 동영상을 생성하는 데 놀라울 정도로 효과적이다. Make-A-Video는 T2V 생성의 새로운 state-of-the-art를 달성하였다.
함수 보존 변환을 사용하여 모델 초기화 단계에서 공간 계층을 확장하여 시간 정보를 포함한다. 확장된 시공간 신경망에는 동영상 컬렉션에서 시간적인 현실의 역학을 학습하는 새로운 attention 모듈이 포함된다. 이 절차는 사전 학습된 T2I 신경망에서 새로운 T2V 신경망으로 지식을 즉시 전달하여 T2V 학습 프로세스를 크게 가속화한다. 시각적 품질을 향상시키기 위해 공간적 super-resolution 모델과 프레임 보간 모델을 학습시킨다. 이것은 생성된 동영상의 해상도를 증가시킬 뿐만 아니라 더 높은 프레임 속도를 가능하게 한다.
Method
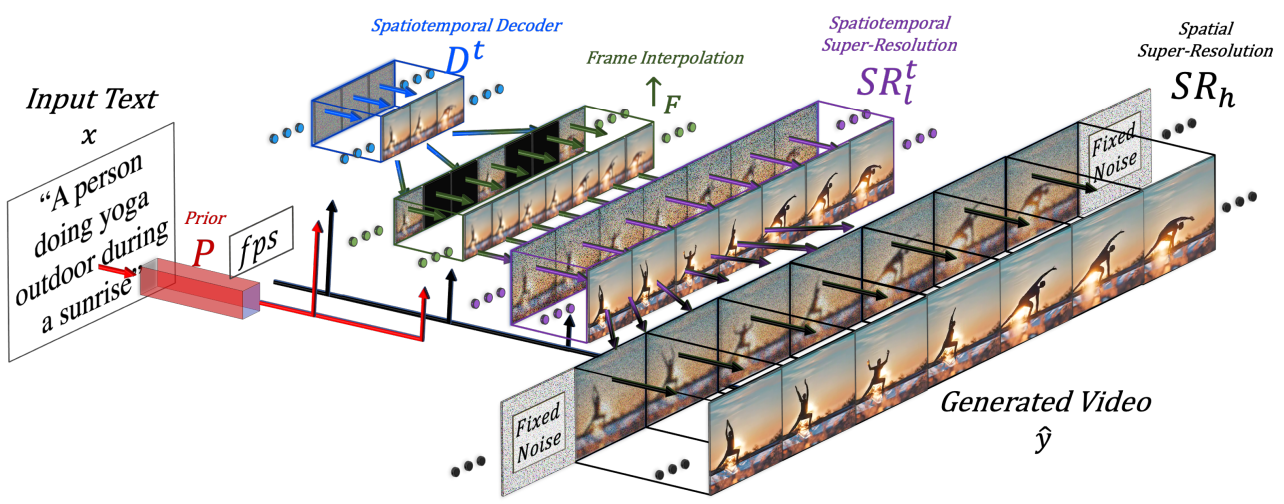
Make-A-Video는 3가지 주요 요소로 구성된다.
- 텍스트-이미지 쌍으로 학습된 base T2I 모델
- 신경망의 블록을 시간 차원으로 확장하는 시공간 convolution 및 attention layer
- 두 시공간 layer로 구성된 시공간 신경망과 높은 프레임 속도 생성을 위한 프레임 보간 신경망
Make-A-Video의 최종 T2V inference 체계는 다음과 같이 공식화할 수 있다.
\[\begin{equation} \hat{y}_t = SR_h \circ SR_l^t \, \circ \uparrow_F \circ \, D^t \circ P \circ (\hat{x}, C_x (x)) \end{equation}\]- $\hat{y}_t$: 생성된 동영상
- $SR_h$, $SR_l$: 시공간적 super-resolution 신경망
- $\uparrow_F$: 프레임 보간 신경망
- $D^t$: 시공간적 디코더
- $P$: prior
- $\hat{x}$: BPE로 인코딩된 텍스트
- $C_x$: CLIP 텍스트 인코더
- $x$: 입력 텍스트
1. Text-to-Image Model
시간적 구성 요소를 추가하기 전에 backbone을 학습시킨다. 텍스트-이미지 쌍에 대해 학습된 T2I 모델은 핵심 구성 요소를 Hierarchical Text-Conditional Image Generation with CLIP Latents 논문과 공유한다.
텍스트에서 고해상도 이미지를 생성하기 위해 다음 신경망을 사용한다.
- Prior network $P$: 텍스트 임베딩 $x_e$와 BPE로 인코딩된 텍스트 토큰 $\hat{x}$가 주어지면 이미지 임베딩 $y_e$ 생성
- 디코더 신경망 $D$: $y_e$를 조건으로 하여 64$\times$64 RGB 이미지 $\hat{y}_t$를 생성
- Super-resolution 신경망 $SR_l$, $SR_h$: $\hat{y}_t$의 해상도를 각각 256$\times$256, 768$\times$768로 올려 최종 생성 이미지 $\hat{y}$ 생성
2. Spatiotemporal Layers
2D 조건부 신경망을 시간적 차원으로 확장하여 동영상을 생성하기 위해 공간적 차원뿐만 아니라 시간적 차원이 필요한 두 가지 주요 구성 요소를 수정한다.
- Convolutional layer
- Attention layer
Fully-connected layer와 같은 다른 layer는 공간 및 시간 정보에 구애받지 않기 때문에 특정 처리가 필요하지 않다. 시간적 수정은 대부분의 U-Net 기반의 diffusion 신경망에서 이루어진다. 시공간 디코더 $D^t$는 각각 크기가 64$\times$64인 16개의 RGB 프레임을 생성하고, 새로 추가된 프레임 보간 신경망 $\uparrow_F$는 생성된 프레임 16개 사이를 보간하여 유효 프레임 속도를 높인다.
Super resolution에는 환각 정보가 포함된다. 아티팩트가 깜박이지 않도록 하려면 환각이 프레임 전체에서 일관되어야 한다. 결과적으로 $SR_l^t$ 모듈은 공간과 시간 차원에서 작동한다. 고해상도 동영상 데이터의 부족뿐만 아니라 메모리와 컴퓨팅 제약으로 인해 $SR_h$를 시간적 차원으로 확장하는 것은 어려운 일이다. 따라서 $SR_h$는 공간 차원에서만 작동한다. 그러나 프레임 전체에서 일관된 디테일의 환각을 만들도록 하기 위해 각 프레임에 대해 동일한 noise 초기화를 사용한다.
2.1 Pseudo-3D convolutional layers
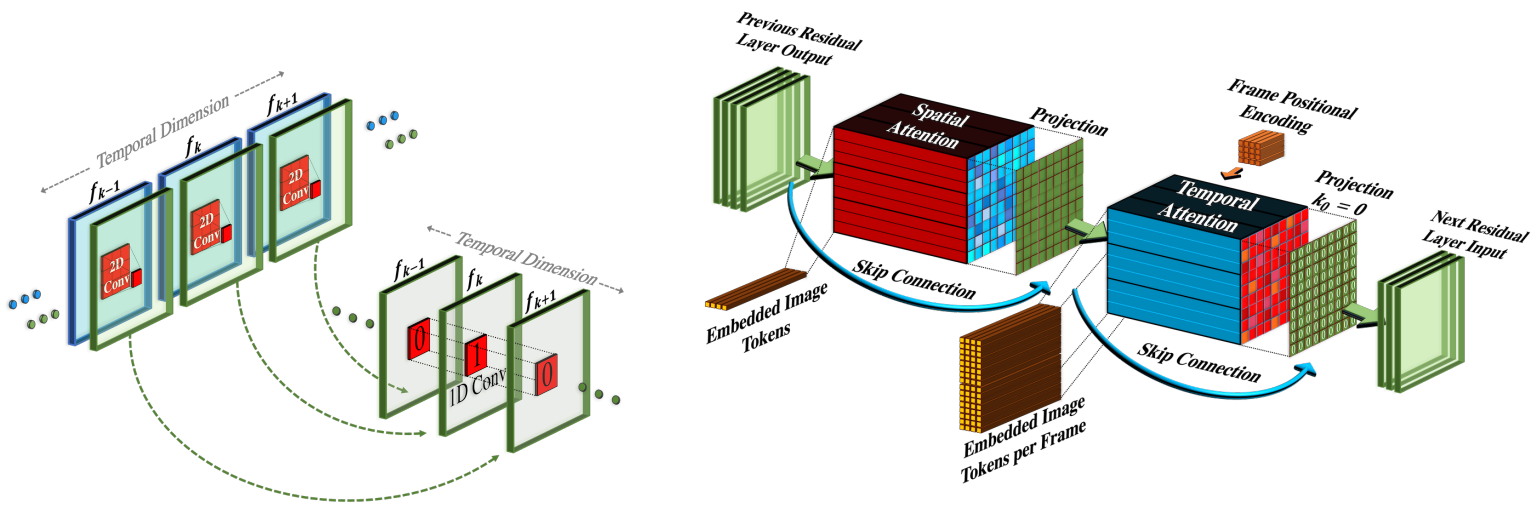
Separable convolution에서 영감을 받아 위 그림과 같이 각 2D conv layer 다음에 1D convolution을 쌓는다. 이는 공간 축과 시간 축 사이의 정보 공유를 촉진하며, 3D conv layer의 많은 계산 없이 가능하다. 또한 사전 학습된 2D conv layer와 새로 초기화된 1D conv layer 사이에 구체적인 파티션을 생성하여, 공간적 convolution의 가중치에서 이전에 학습한 공간적 지식을 유지하면서 시간적 convolution을 처음부터 학습할 수 있다.
입력 텐서 $h \in \mathbb{R}^{B \times C \times F \times H \times W}$가 주어지면 Pseudo-3D convolution layer는 다음과 같이 정의된다.
\[\begin{equation} Conv_{P3D} (h) := Conv_{1D} (Conv_{2D} (h) \circ T) \circ T \end{equation}\]$T$는 공간 차원과 시간 차원을 바꾸는 변환 연산자이다. $Conv_{2D}$ layer는 사전 학습된 T2I 모델로 초기화되며, 부드러운 초기화를 위하여 $Conv_{1D}$ layer는 항등 함수로 초기화된다. 이를 통해 공간적 layer에서 시공간적 layer로의 학습이 매끄러워진다. 초기화 시 신경망은 각각 입력 텍스트에 충실하지만 시간적 일관성이 부족한 $K$개의 서로 다른 이미지를 생성한다.
2.2 Pseudo-3D attention layers
T2I 신경망의 핵심 요소는 attention layer로, 추출된 feature에 대한 self-attention 외에도 텍스트 정보가 diffusion timestep과 같은 기타 관련 정보와 함께 여러 네트워크 계층에 주입된다. 3D conv layer를 사용하는 것은 계산적으로 무겁지만 attention layer에 시간적 차원을 추가하는 것은 메모리 소비 측면에서 완전히 불가능하다. Video diffusion model (VDM) 논문에서 영감을 받아 차원 분해 전략을 attention layer로 확장한다. 각각의 사전 학습된 공간적 attention layer 다음에 시간적 attention layer를 쌓는다. 이 layer는 conv layer와 마찬가지로 전체 시공간 attention layer에 가깝다. 구체적으로 입력 텐서 $h$가 주어지면, $flatten$은 공간 차원을 $h’ \in \mathbb{R}^{B \times C \times F \times HW}$로 flatten하는 행렬 연산자로 정의하고, $unflatten$은 역행렬 연산자로 정의된다. 따라서 Pseudo-3D attention layer는 다음과 같이 정의된다.
\[\begin{equation} ATTN_{P3D} (h) = unflatten (ATTN_{1D} (ATTN_{2D} (flatten (h)) \circ T) \circ T) \end{equation}\]$Conv_{P3D}$와 비슷하게 부드러운 시공간적 초기화를 위하여 $ATTN_{2D}$ layer는 사전 학습된 T2I 모델이고 $ATTN_{1D}$는 항등 함수로 초기화된다.
Factorized space-time attention layers는 VDM과 CogVideo에서도 사용되었다. CogVideo는 각 고정된 공간 layer에 임시 layer를 추가했지만 함께 학습시켰다. VDM은 신경망이 이미지와 동영상을 교환할 수 있도록 학습시키기 위해 flatten되지 않은 1$\times$3$\times$3 convolution 필터를 통해 2D U-Net을 3D로 확장했다. 반대로 시간 정보가 각 conv layer를 통과하도록 추가 3$\times$1$\times$1 convolution projection을 그 다음에 적용한다.
또한 T2I 컨디셔닝을 위해 CogVideo와 비슷하게 추가 컨디셔닝 매개변수 $fps$를 추가하여 생성된 동영상의 초당 프레임 수를 나타낸다. 다양한 fps 컨디셔닝을 통해 학습에 사용 가능한 동영상의 제한된 볼륨을 처리할 수 있는 추가 augmentation 방법을 사용할 수 있으며, inference 시에 생성된 동영상에 대한 추가 제어를 제공한다.
3. Frame interpolation network
앞서 설명한 시공간적 수정에 더하여, 새로운 프레임 interpolation 및 extrapolation 신경망 $\uparrow_F$를 학습시킨다. 이 신경망은 생성된 동영상의 프레임 수를 늘리기 위하여 interpolation으로 생성된 동영상을 부드럽게 하거나 전후 프레임 extrapolation으로 동영상의 길이를 늘릴 수 있다.
메모리와 컴퓨팅 제약 내에서 프레임 속도를 높이기 위해 마스킹된 입력 프레임을 zero-padding한 후 동영상 upsampling을 활성화하여 시공간 디코더 $D_t$를 finetuning한다. 프레임 interpolation을 finetuning할 때 U-Net의 입력에 4개의 채널을 추가한다. 구체적으로, 마스킹된 입력 RGB 동영상을 위한 3개의 채널과 마스킹 여부를 나타내는 추가 binary 채널로 구성된다.
가변 frame-skip과 fps 컨디셔닝으로 finetuning하여 inference 시에 여러 시간적 upsampling 속도를 활성화한다. 모든 실험에서 16프레임 동영상을 76프레임으로 upsampling하기 위해 frame-skip 5와 함께 $\uparrow_F$를 적용한다. 동영상 시작 또는 끝에서 프레임을 마스킹하여 동영상 extrapolation 또는 이미지 애니메이션에 동일한 아키텍처를 사용할 수 있다.
4. Training
위에서 설명한 Make-A-Video의 다양한 구성 요소는 독립적으로 학습된다. 텍스트를 입력으로 받는 유일한 구성 요소는 prior $P$이다. 쌍을 이룬 텍스트-이미지 데이터로 학습하고 동영상에 대해서는 finetuning하지 않는다.
디코더, prior, 두 개의 super-resolution 구성 요소는 정렬된 텍스트 없이 먼저 이미지에 대해서만 학습된다. 디코더는 CLIP 이미지 임베딩을 입력으로 받고 super-resolution 구성 요소는 학습 중에 downsampling된 이미지를 입력으로 받는다.
이미지에 대한 학습 후 새로운 임시 layer을 추가하고 초기화한 후 레이블이 없는 동영상 데이터에 대해 finetuning한다. 1에서 30까지의 무작위 fps로 원본 동영상에서 16개 프레임이 샘플링된다. 샘플에 베타 함수를 사용하고 디코더를 학습하는 동안 더 높은 FPS 범위(적은 움직임)에서 시작하여 더 낮은 FPS 범위(많은 움직임)로 전환한다. 프레임 interpolation 구성 요소는 시간적 디코더에서 finetuning된다.
Experiments
1. Quantitative Results
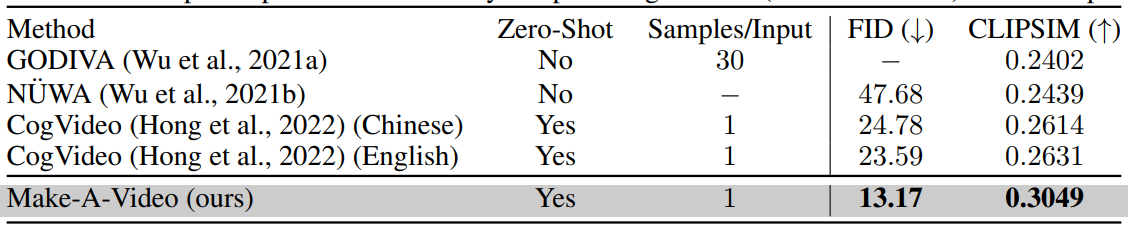
다음은 MSR-VTT 데이터셋에 대한 T2V 생성 평가 결과이다. Zero-Shot은 MSR-VTT에서 학습을 하지 않았다는 것을 의미한다.
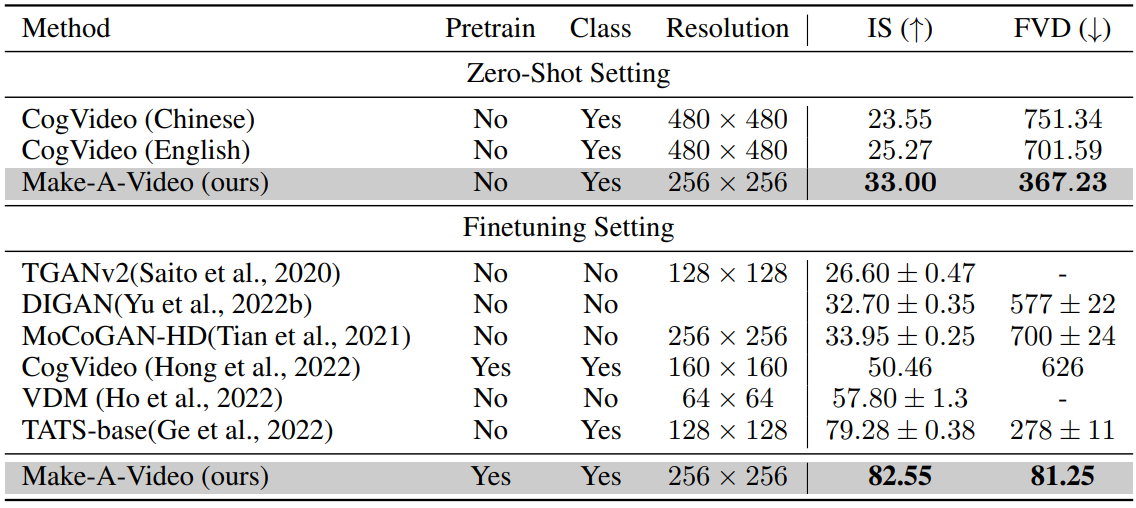
다음은 UCF-101 데이터셋에 대한 T2V 생성 평가 결과이다.
다음은 사람이 직접 Make-A-Video를 CogVideo와 비교한 결과이다. 표의 숫자는 Make-A-Video 모델을 더 선호한다고 답한 비율(%)이다.

2. Qualitative Results
다음은 Make-A-Video 모델의 다양한 비교와 적용을 나타낸 것이다.
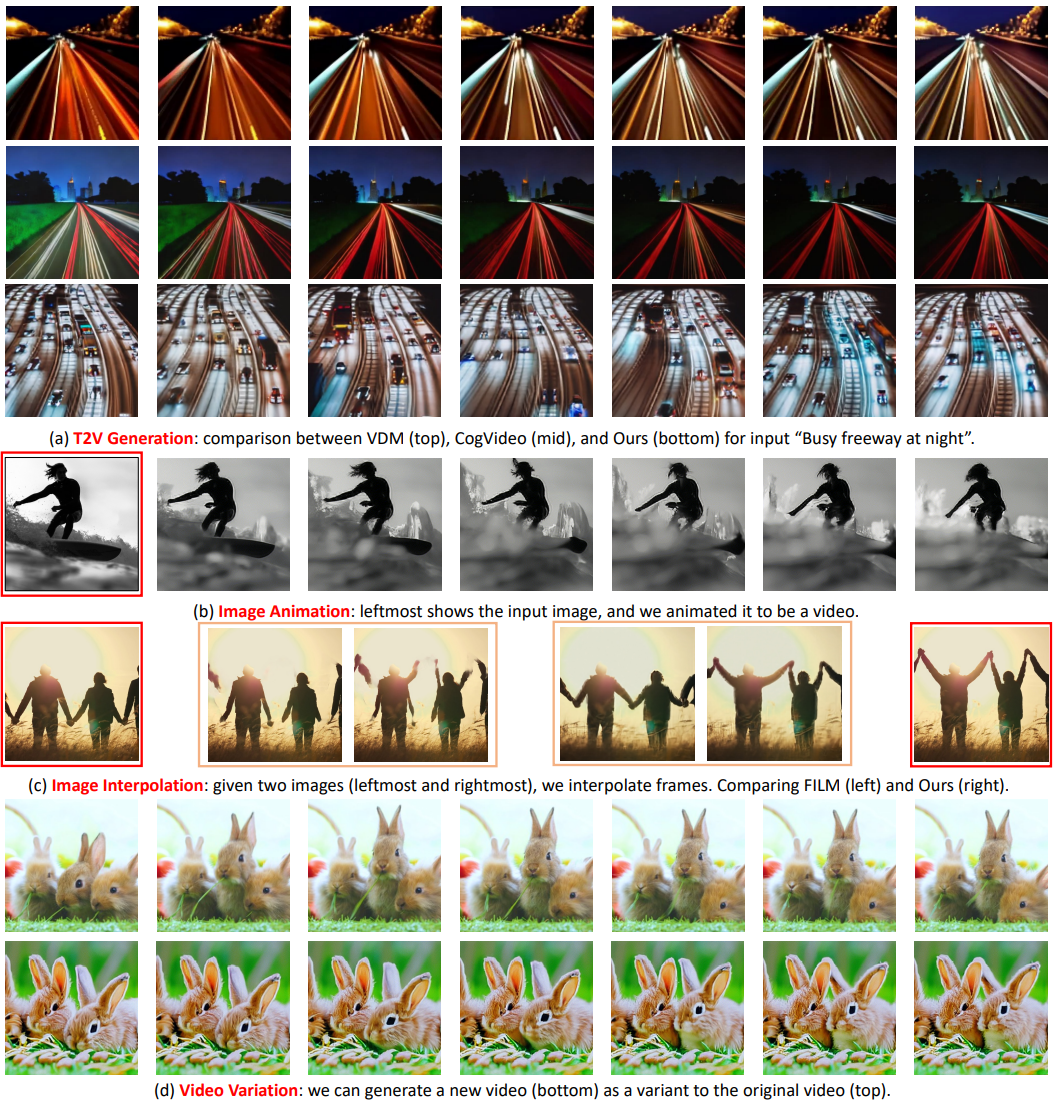
(a)는 같은 텍스트 입력에 대하여 VDM, CogVideo와 비교한 것이다. (b)는 맨 왼쪽 이미지를 시작으로 애니메이션을 만든 것이다. (c)는 두 이미지가 주어질 때 중간 이미지를 interpolation한 것으로 FILM(왼쪽)과 Make-A-Video(오른쪽)를 비교한 것이다. (d)는 같은 CLIP 임베딩을 입력하였을 때의 다양한 결과를 보여준다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)