






arXiv 2022. [Paper] [Page]
Gyeongnyeon Kim, Wooseok Jang, Gyuseong Lee, Susung Hong, Junyoung Seo, Seungryong Kim
Korea University, Seoul, Korea
17 Dec 2022
Introduction

(Guidance 없이 합성한 이미지 (위)와 DAG로 생성한 이미지 (아래), 그리고 각 이미지의 추정 깊이)
일반적으로 생성 모델, 특히 diffusion model은 주로 텍스처나 모양에 중점을 두지만 이미지 생성 프로세스 중에 형상 기하학을 거의 고려하지 않는다. 결과적으로 위 그림에서 볼 수 있듯이 기존의 diffusion model은 종종 모호한 깊이와 어수선한 객체 레이아웃을 포함하는 기하학적으로 믿기지 않는 샘플을 생성한다. 이러한 비현실적인 3D 형상으로 합성된 샘플은 2D의 깊이 맵에 의해 편차가 효과적으로 캡처될 수 있으며 시각적으로 매력적이지 않을 뿐만 아니라 로봇이나 자율 주행과 같은 후속 task에 적합하지 않다는 점에서 문제가 있다.
Diffusion model의 샘플링 프로세스를 클래스별 분포로 유도하는 일부 클래스 조건부 guidance 접근 방식이 있었지만 샘플을 기하학적으로 그럴듯한 이미지 분포로 안내하는 것은 제한된 관심을 받았다. 이를 고려하여 diffusion model에 깊이 인식을 도입하는 DAG (Depth-Aware Guidance)라는 새로운 프레임워크를 제안한다.
기존 guidance에서와 같이 깊이-이미지 쌍을 사용하여 처음부터 diffusion model이나 depth predictor를 학습시키는 것은 ground-truth 깊이 맵에 주석을 추가하는 데 많은 노력이 필요하고 모델을 공동으로 학습시키는 데 엄청난 시간과 계산이 필요하기 때문에 어려울 수 있다. 이러한 문제를 극복하기 위해 사전 학습된 diffusion model의 풍부한 표현을 활용하여 depth predictor를 학습시킴으로써 깊이 예측 task에서 diffusion model의 표현 능력에 대한 지식을 확장하는 새로운 접근 방식을 사용한다.
또한 레이블 효율적인 depth predictor를 활용하여 diffusion model을 사용한 이미지 생성을 위한 depth-aware guidance 방식을 제안힌다. 구체적으로 기하학적 인식을 효과적으로 guide하는 두 가지 guidance 전략인 depth consistency guidance와 depth prior guidance를 제시한다.
첫 번째 전략인 depth consistency guidance는 일관성 정규화에 동기가 부여 받은 전략이다. 더 나은 예측을 depth pseudo-label로 처리함으로써 이미지가 잘못된 예측을 개선하도록 guide한다. 두 번째 전략인 depth prior guidance는 사전 학습된 diffusion U-Net을 추가 사전 네트워크로 활용하여 샘플링 프로세스 중에 guidance를 제공한다. 이 디자인은 diffusion model의 샘플링 프로세스에 깊이 정보를 명시적으로 주입한다.
프레임워크를 평가하기 위해 실내 및 실외 장면 데이터셋에 대한 실험을 수행하고 기하학적 인식을 캡처하기 위한 깊이 추정 task의 관점에서 새로운 메트릭을 제안한다. 본 논문은 이미지 생성이 기하학적 구성을 더 잘 인식하도록 샘플링 프로세스 중에 깊이 정보를 활용하려는 첫 번째 시도이다.
Methodology
1. Motivation and Overview
GAN이나 diffusion model과 같은 기존 생성 모델에 의한 합성 이미지는 상당히 그럴듯해 보이지만 기하학적 인식이 부족한 경우가 많다. 예를 들어, 기존 모델에 의해 생성된 이미지는 원근감이 없거나 레이아웃의 왜곡을 포함하는 경우가 많다. 이러한 기하학적 인식을 고려하지 못하는 것은 기하학적으로 사실적인 이미지가 필요한 많은 후속 task에 적용할 때 문제가 될 수 있다.
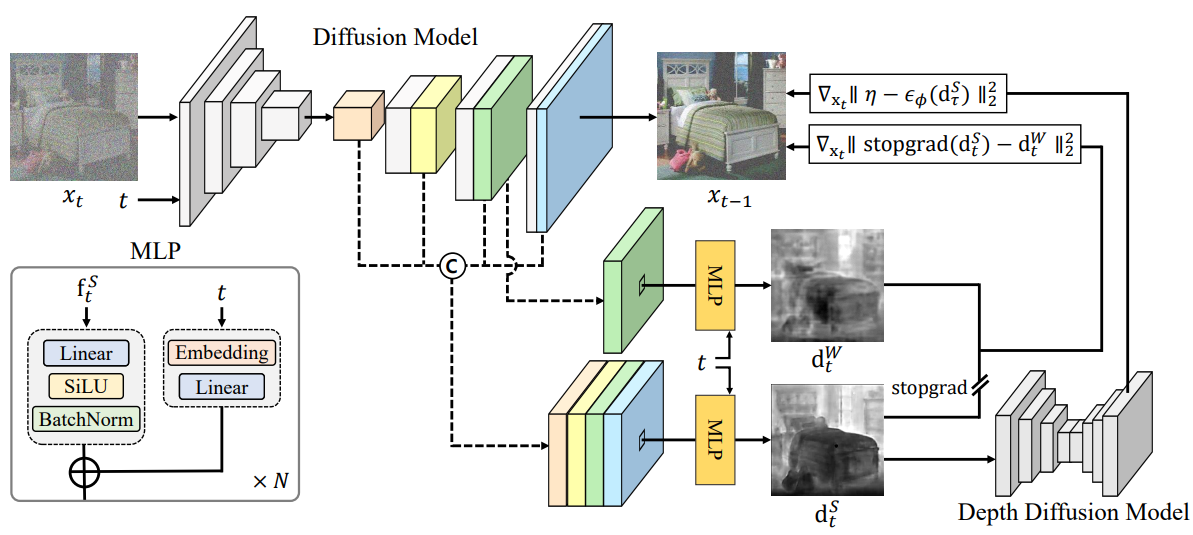
이 한계를 극복하기 위해, 본 논문은 기하학적 정보를 guidance로 diffusion model에 명시적으로 통합하기 위해 위 그림에서 설명된 새로운 프레임워크를 제안한다. 구체적으로 깊이 인식 이미지를 생성하기 위해 소량의 깊이 레이블 데이터로 내부 표현을 사용하여 depth predictor를 학습시킨다. 그런 다음 샘플링 과정에서 얻은 깊이 맵을 사용하여 중간 이미지를 guide한다.
2. Label-Efficient Training of Depth Predictors
Diffusion models beat gans on image synthesis 논문에서와 같이 간단한 방식으로 diffusion guidance를 통해 깊이 인식 이미지를 생성하려면 많은 양의 이미지-깊이 쌍 또는 노이즈가 있는 이미지에 대해 학습된 외부 깊이 추정 네트워크가 필요하며, 둘 다 얻기 어렵다. 이 문제를 해결하기 위해 이미지의 깊이 정보를 포함할 수 있는 DDPM으로 학습한 풍부한 표현을 재사용한다.
Network architecture
최근 연구에서는 diffusion model로 학습된 네트워크의 내부 feature가 의미론적 정보를 인코딩할 수 있음을 보여주었으며, 이를 기반으로 본 논문은 프레임워크에 깊이 정보를 통한다.
레이블 효율적인 방식으로 깊이 추정을 수행하기 위해 U-Net에서 중간 feature을 입력으로 받아 noise가 많은 입력 이미지의 깊이 값을 추정하는 픽셀 단위의 얕은 MLP regressor를 사용한다. 구체적으로 diffusion U-Net에서 $k$번째 디코더 레이어의 출력으로부터 내부 feature
\[\begin{equation} f_t (k) \in \mathbb{R}^{C(k) \times H(k) \times W(k)} \end{equation}\]를 얻는다. 여기서 $C(k)$는 채널 차원을 나타내고, $H(k) \times W(k)$는 U-Net 디코더의 $k$번째 layer의 공간 해상도를 나타낸다. 그런 다음 MLP 블록을 픽셀 단위로 쿼리하여 깊이 맵을 형성합니다. 여기서 깊이 맵은 다음과 같이 공식화할 수 있다.
\[\begin{equation} d_t (k) = \textrm{MLP} (f_t (k)) \end{equation}\]일반적으로 한 layer의 feature만 사용하는 것보다 여러 U-Net layer의 더 많은 feature를 사용하는 것이 좋다. 따라서 저자들은 많은 layer에서 더 많은 feature를 추출하고 다음과 같이 채널 차원에서 연결한다.
\[\begin{equation} g_t = [f_t (1); f_t (2); \cdots; f_t (d)] \end{equation}\]여기서 $[\cdot ; \cdot]$은 channel-wise concatenation 연산이고, $d$는 선택된 layer의 총 개수이다. 그런다음 pixel-wise MLP depth predictor에 입력으로 넣는다.
\[\begin{equation} d_t = \textrm{MLP} (g_t) \end{equation}\]저자들은 입력에 추가로 time-embedding block을 추가하여 임의의 timestep에서 깊이 맵을 예측하도록 pixel-wise depth predictor를 수정한다. 따라서, 이 predictor를 전체 샘플링 프로세스에 사용한다.
\[\begin{equation} d_t = \textrm{MLP} (g_t, t) \end{equation}\]Loss function
저자들은 ground-truth 깊이 맵 $y$를 사용하여 L1 loss로 diffusion U-Net의 고정 feature로만 depth predictor를 학습한다.
\[\begin{equation} \mathcal{L}_\textrm{depth} = \| d_t - y \|_1 \end{equation}\]이 전체 과정으로 깊이 도메인에서 합리적인 레이블 효율적인 예측 성능을 달성한다. 아래 그림과 같이 깊이 예측 방식을 사용하면 임의의 입력 이미지뿐만 아니라 임의의 샘플링 step의 중간 이미지의 깊이 맵을 예측할 수 있다.

3. Depth Guided Sampling for Diffusion Model
생성된 이미지가 그럴듯한 깊이 맵을 생성하도록 하기 위해 샘플링 프로세스 중에 예측된 깊이 맵이 정확하여야 한다. 이를 위해 denoising U-Net의 표현을 사용하는 두 가지 다른 guidance 테크닉을 제안힌다. 샘플링 프로세스 중에 이러한 기술을 활용하면 모델을 정규화하여 dense map prior를 인식하는 이미지를 생성한다. 구체적으로, 앞서 언급한 효율적으로 학습된 depth predictor를 사용하면 모든 샘플링 step에서 이미지의 깊이 맵을 예측할 수 있다.
안타깝게도 미리 결정된 레이블이 없기 때문에 이 레이블을 사용하여 loss를 계산할 수 없으며 샘플링 프로세스 중에 guidance를 제공할 수 없다. 따라서 guidance 제약으로 작용할 수 있는 두 가지 대체 손실 함수를 구축한다. 일반적인 형태의 guidance 방정식은 다음과 같다.
\[\begin{equation} x_{t-1} \sim \mathcal{N} (\mu_\theta (x_t) - \omega \nabla_{x_t} \mathcal{L}, \Sigma_\theta (x_t)) \end{equation}\]Depth consistency guidance (DCG)
Ground-truth 정보가 없을 때 이미지에 깊이 guidance를 제공하는 naive한 접근 방식 중 하나는 pseudo-labeling을 사용하는 것이다. 그러나 pseudo-label이 될 수 있는 신뢰할 수 있는 예측을 생성하는 것은 어렵다. 첫 번째 guidance 방법은 pseudo-labeling과 일관성 정규화를 결합한 FixMatch에서 영감을 받았다고 한다. Weakly-augmented label을 pseudo-label로 간주하여 성능을 향상시킨다.
저자들은 표현이 더 풍부할수록 더 충실하게 생성된 깊이 맵이 된다고 주장한다. 따라서 더 많은 feature block에서 얻은 예측이 더 유익한 것으로 간주하여 강력한 예측, 즉 pseudo-label로 취급하기에 적합하다. 여러 feature block을 사용하는 이러한 예측을 “strong branch prediction”라고 하고 상대적으로 적은 feature를 사용하는 예측을 “weak branch prediction”이라고 한다.
구체적으로, feature $g^W = [f_t (6)]$을 weak branch feature로 사용하고, $g^S = [f_t (2); f_t (4), f_t (5), f_t (6), f_t (7)]$을 strong branch feature로 사용한다. 저자들은 $g^W$와 $g^S$의 서로 다른 채널을 다루기 위해 두 개의 비대칭 predictor MLP-S와 MLP-W를 설계한다.
MLP-S는 더 많은 feature를 U-Net block으로부터 받고 MLP-W는 더 적은 feature를 받으며, 두 MLP를 함께 학습시킨다. 수집한 feature들을 MLP들에 입력하여 깊이 맵 예측을 얻는다.
\[\begin{equation} d_t^S = \textrm{MLP-S} (g_t^S, t), \quad d_t^W = \textrm{MLP-W} (g_t^W, t) \end{equation}\]앞서 설명한 것처럼 $d_t^S$를 pseudo-label로 취급하고 $d_t^W$를 예측값으로 취급한다. 그런 다음 예측된 두 dense map 사이의 consistency loss로 loss를 계산한다. Strong feature에 stop gradient 연산을 적용하여 강한 예측이 약한 예측으로부터 학습하는 것을 방지한다. Loss의 기울기는 diffusion U-Net을 통과하여 샘플링 프로세스를 guide한다.
\[\begin{equation} \mathcal{L}_{dc} = \| \textrm{stopgrad} (d_t^S) - d_t^W \|_2^2 \end{equation}\]Depth prior guidance (DPG)
저자들은 샘플링 프로세스에 depth prior를 주입하기 위해 depth prior guidance라고 하는 또 다른 guidance 방법을 제안한다. 사전 학습된 diffusion model은 noise가 있는 분포를 현실적인 분포로 효과적으로 정제할 수 있거나 diffusion model의 지식을 활용하여 실제 데이터와 일치하도록 데이터의 noise가 있는 초기화를 최적화하는 데 도움이 될 수 있다. 따라서 깊이 도메인에서 또 다른 작은 해상도의 diffusion U-Net $\phi$를 학습시키고 두 번째 guidance 방법을 위한 prior로 사용한다.
앞에서 설명한 것처럼 feature를 U-Net의 디코더 부분에서 추출하여 MLP depth predictor로 대응되는 깊이 맵을 추출할 수 있다. Prior diffusion model을 활용하기 위해 diffusion의 forward process로 깊이 예측 $d_0^S$에 noise를 주입한다.
\[\begin{equation} d_\tau^S = \sqrt{\vphantom{1} \bar{\alpha}_\tau} d_0^S + \sqrt{1 - \bar{\alpha}_\tau} \eta, \quad \eta \sim \mathcal{N}(0, I) \end{equation}\]여기서 $\tau$는 prior diffusion model에서 사용하는 timestep이다. 깊이 예측에 noise를 더한 다음 이를 prior network에 입력하여 추가된 noise를 예측하도록 한다. 그런 다음 추가된 noise와 예측된 noise 사이의 MSE의 기울기를 계산한다.
\[\begin{equation} \mathcal{L}_\textrm{dp} = \| \eta - \epsilon_\phi (d_\tau^S) \|_2^2 \end{equation}\]위 loss의 기울기를 외부 classifier의 기울기로 취급하여 생성된 이미지가 depth prior에 일치하도록 guide한다.
\[\begin{equation} x_{t-1} \sim \mathcal{N}(\mu_\theta (x_t) - \omega_\textrm{dp} \nabla_{x_t} \mathcal{L}_\textrm{dp}, \Sigma_\theta (x_t)) \end{equation}\]여기서 $\omega_\textrm{dp}$는 guidance scale이다.
Overall guidance
제안된 DCG와 DPG를 모두 사용하여 샘플링된 이미지를 guide할 수 있다.
\[\begin{equation} x_{t-1} \sim \mathcal{N} (\mu_\theta(x_t) - \omega_\textrm{dc} \nabla_{x_t} \mathcal{L}_\textrm{dc} - \omega_\textrm{dp} \nabla_{x_t} \mathcal{L}_\textrm{dp}, \Sigma_\theta (x_t)) \end{equation}\]Experiments
1. Experimental Results
Depth prediction performance
다음은 깊이 예측 성능의 정량적 비교 결과이다.
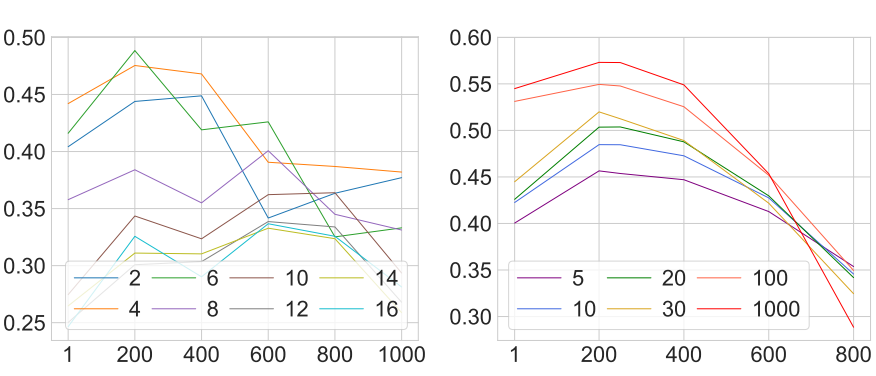
(a)는 다양한 U-Net block에 대한 깊이 예측 정확도를 비교한 것이고, (b)는 학습 이미지 수에 대한 깊이 예측 정확도를 비교한 것이다. (a)의 결과를 바탕으로 저자들은 상대적으로 높은 정확도를 보여주는 중간 feature block \(\{l_n\} = \{2, 4, 5, 6, 7\}\)을 선택하였다. 따라서 \(S = \{2, 4, 5, 6, 7\}\)이고 \(W = \{6\}\)이 사용되었다.
(b)의 결과를 보면 이미지 1000장으로 학습한 모델의 정확도가 가장 높았지만 100장으로 학습한 것과 큰 성능 차이가 없으므로 저자들은 depth predictor 학습에 100장의 이미지를 사용한다.
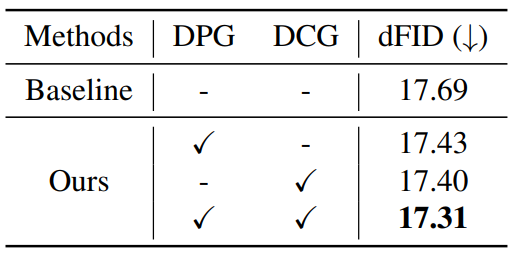
Quantitative results
다음은 LSUN-church 데이터셋에서의 정량적 결과이다. dFID는 추정된 깇이 이미지의 FID를 측정한 것이다.
Qualitative results
다음은 LSUN-bedroom 데이터셋에서의 정성적 비교이다.

(a), (c), (e), (g)는 guidance 없이 생성한 이미지이고 (b), (d), (f), (h)는 depth-aware guidance를 사용하여 생성한 이미지이다. 맨 윗줄은 생성한 이미지, 중간은 대응되는 깊이, 맨 아랫줄은 surface normal이다.
다음은 깊이 정보에서 얻은 point cloud 표현을 시각화한 것이다.

윗 줄의 이미지는 guidance 없이 생성한 이미지이고 아랫 줄의 이미지는 guidance를 사용하여 생성한 이미지이다. Guidance를 사용하였을 때 더 분명한 경계를 보여주며 기하학적으로 더 높은 레벨의 디테일을 포함한다.
다음은 LSUN-church 데이터셋에서의 정성적 결과이다. 윗 줄이 DDIM으로 샘플링한 guide되지 않은 샘플이고 아랫 줄이 DAG로 guide된 샘플이다.

2. Ablation Study
Guidance scale
다음은 DCG와 DPG의 guidance scale에 대한 dFID를 비교한 것이다.

$w_\textrm{dc}$와 $w_\textrm{dp}$가 40일 때 모두 dFID의 결곽 좋았다.
Resolution of the prior network
다음은 depth prior network의 해상도에 따른 dFID를 측정한 표이다.

128$\times$128을 사용할 떄 성능이 가장 좋다.
3. Application for Monocular Depth Estimation
레이블이 없는 데이터로 생성 효과를 개선하기 위해 guide된 이미지와 대응되는 깊이 맵을 활용한다. U-Net 기반의 깊이 추정 네트워크를 학습시키고 NYU-Depth 데이터셋으로 평가한다. 레퍼런스 데이터, guide되지 않은 생성 결과, DAG로 생성한 결과를 사용하여 학습 결과를 비교한다.
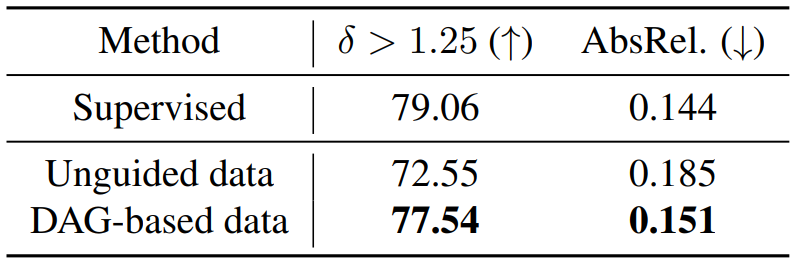
위 표는 DAG로 생성한 데이터가 depth predictor를 학습하는 데 효과적임을 보여준다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)