






arXiv 2022. [Paper] [Github]
Zhangxuan Gu, Haoxing Chen, Zhuoer Xu, Jun Lan, Changhua Meng, Weiqiang Wang
Tiansuan Lab, Ant Group Inc | Nanjing University
6 Dec 2022
Introduction
Instance segmentation은 binary mask로 개체를 나타내는 것을 목표로 한다. 표준 instance segmentation 방식은 두 그룹, 즉 two-stage와 single-stage로 나눌 수 있다. Two-stage 방법은 먼저 객체를 감지한 다음 RoI alignment로 영역의 feature를 잘라 각 픽셀을 추가로 분류한다. Single-stage instance segmentation의 프레임워크는 일반적으로 anchor를 기반으로 하므로 훨씬 간단하다. 그러나 두 그룹 모두 dense prediction head를 가지고 있어 inference 중에 NMS(Non-Maximum Suppression)가 필요하다.
최근에 SOLQ, QueryInst, Mask2Former는 학습 가능한 쿼리와 이분 매칭을 사용하는 end-to-endins tance segmentation 프레임워크를 제안했다. 특히 instance mask를 예측하기 위해 instance-aware RoI feature을 mask head에 공급하여 DETR을 확장하였다. 기존의 anchor 기반 방법과 anchor가 없는 방법과 달리 쿼리 기반 접근 방식은 임의로 생성된 쿼리를 사용하여 RPN과 anchor를 대체하여 localization instance의 inductive bias를 줄이고 일대일 레이블 할당으로 segmentation 성능을 향상시켰다.
쿼리 기반 접근 방식이 noise-to-mask 방식 같이 공식화된다는 점을 고려할 때 diffusion model의 특수한 경우라고 생각한다. 정확히 말하면 diffusion model이 점진적으로 여러 step의 denoising을 수행하지만, 쿼리 기반 접근 방식은 디코더의 forward pass 하나만으로 개체에 대한 랜덤 쿼리를 직접 denoising한다. 이는 저자들이 diffusion process를 통해 instance segmentation을 위한 새로운 프레임워크를 탐색하도록 영감을 주었다.
그러나 instance segmentation에서 diffusion model을 적용하는 방법은 여전히 해결되지 않은 문제이다. 최근 DiffusionDet은 이미지에서 bounding box의 공간에 대한 생성 task로 객체 감지 작업을 처리하기 위해 제안되었다. 학습 단계에서 noise box를 얻기 위해 ground-truth boundary box에 가우시안 noise를 추가한다. 그런 다음 ground-truth box를 예측하기 위해 noisy box의 RoI feature가 디코더에 공급된다. 전체 네트워크는 denoising 파이프라인처럼 작동한다. Inference 중에 DiffusionDet은 diffusion process의 역순으로 임의로 초기화된 box를 디코더 네트워크에 반복적으로 공급하여 boundary box를 생성한다.
CondInst 논문에 따르면 하나의 이미지 내의 instance mask는 공통 마스크 feature가 있는 instance-aware filter로 나타낼 수 있다. 이에 영감을 받아 본 논문은 noise-to-filter diffusion 관점에서 새로운 instance segmentation 프레임워크인 DiffusionInst를 제안한다. DiffusionDet의 파이프라인을 재사용하여 instance segmentation에 두 가지 변경 사항을 적용했다.
- 첫째, boundary box 외에도 diffusion 중에 noise filter도 생성한다.
- Global mask 복원을 위해 FPN에서 다중 스케일 정보를 얻기 위해 mask branch를 도입한다.
아래 그림에서 DiffusionInst의 denoising diffusion process를 보여준다.
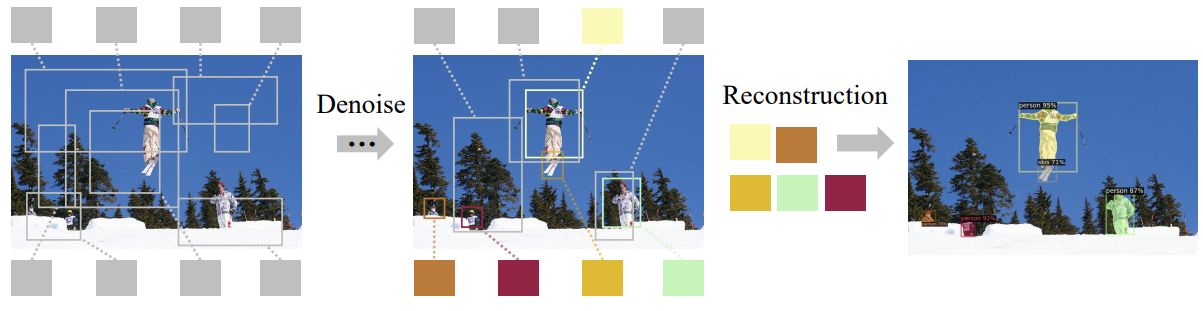
Multi-step inference를 수행하는 능력 외의 또 다른 장점은 noisy라게 생성된 필터가 무작위로 선택된 시간 \(t \in \{0, 1, \cdots, T\}\)에 따라 다른 분포의 noise를 포함할 수 있다는 것이다. 경우에 따라 $T$ denoising step는 $T$개의 다른 분포의 noise로 볼 수 있으며, 이는 학습의 어려움을 크게 증가시키고 모델 견고성과 성능에 크게 기여한다.
Methodology
1. Preliminaries
Diffusion Model
최근 diffusion model은 일반적으로 2개의 Markov chain을 사용한다. 하나는 이미지에 noise를 더하는 forward chain이고, 다른 하나는 noise를 제거하여 이미지를 복원하는 reverse chain이다. 데이터 분포 $x_0 \sim q(x_0)$가 주어지면 $t$에서의 forward process를 $q(x_t \vert x_{t-1})$로 정의한다. 이 process는 점진적으로 가우시안 noise를 분산 schedule에 따라 데이터에 추가한다.
\[\begin{equation} q(x_t \vert x_{t-1}) = \mathcal{N} (x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I) \end{equation}\]$x_0$가 주어지면 $\epsilon \sim \mathcal{N}(0,I)$을 샘플링하여 $x_t$의 샘플을 쉽게 얻을 수 있다.
\[\begin{equation} x_t = \sqrt{\vphantom{1} \bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon, \quad \quad \bar{\alpha}_t = \prod_{s=0}^t (1 - \beta_s) \end{equation}\]신경망은 서로 다른 \(t \in \{1, \cdots, T\}\)에 대하여 $x_t$에서 $x_0$를 예측하도록 학습된다. Inference 시에는 random noise $x_T$에서 시작하여 반복적으로 reverse chain을 적용하여 $x_0$를 얻는다.
DiffusionDet
Object detection task의 첫 번째 diffusion model이다. 데이터 샘플은 bounding box의 집합 $x_0 = b$이고, $b \in \mathbb{R}^{N \times 4}$는 $N$개의 box로 이루어진 집합이다.
학습 중에는 먼저 diffusion process를 구성한 뒤 이 process를 reverse한다. 원래 ground-truth box에 추가로 box를 padding하면 모델이 고정된 수의 instance box를 처리할 수 있다. Set prediction loss는 레이블 할당 전략으로 optimal transport assignment을 사용하여 전체 DiffusionDet를 최적화하는 데 활용된다.
DiffusionDet의 inference 과정은 추가로 DDIM을 사용하여 다음 step을 위한 box를 복원한다.
2. Mask Representation
Instance는 일반적으로 binary mask로 표시된다. 그러나 PolarMask와 BlendMask에 따르면 instance mask에 대한 다양한 표현 방법이 있다. 예를 들어 PolarMask는 극좌표를 사용하여 instance mask를 공식화한다. 360도를 36방향으로 나누어 중심점에서 36차원 벡터로 하나의 마스크를 나타내며 각 값은 반직선 길이를 나타낸다. 경우에 따라 상자(4차원 벡터)가 매우 거친 마스크로 보일 수도 있다.
결과적으로 dynamic mask head를 사용하여 CondInst를 따르는 instance mask를 나타낸다. 구체적으로 instance mask는 mask branch와 instance별 필터 $\theta \in \mathbb{R}^d$에서 instance에 구애받지 않는 mask feature map $F_{mask}$를 convolution하여 생성할 수 있으며 다음과 같이 계산된다.
\[\begin{equation} m = \phi (F_{mask}; \theta) \end{equation}\]$F_{mask}$는 FPN feature \(\{P_3, P_4, P_5\}\)로 이루어진 multi-scale fused feature map이다. $m \in \mathbb{R}^{H \times W}$는 예측된 binary mask이다. $\phi$는 mask head를 나타내며 필터 $\theta$를 가중치로 하는 3개의 1$\times$1 convolutional layer로 구성된다.
Diffusion process에서 instance mask를 나타내기 위해 필터를 사용하면 두 가지 이점이 있다. 하나는 전체 마스크에 대한 random noise를 직접 제거하는 것이므로 벡터보다 훨씬 더 복잡하다. DiffusionDet은 noise-to-box 세팅에서 놀라운 결과를 보여주었지만, noise-to-box의 성공으로 noise-to-filter 프로세스를 제안하는 것은 자연스럽다.
또 다른 이점은 광범위하게 사용되는 box-to-mask 예측 방식, 즉 RoI feature를 local mask로 디코딩하는 것을 global mask 예측을 위한 dynamic mask head로 대체한다는 것이다. Boundary box와 달리 instance box는 instance 가장자리에 대한 더 높은 요구 사항으로 인해 더 큰 receptive field가 필요하다. RoI feature는 일반적으로 instance 가장자리의 디테일이 모두 누락된 크기의 다운샘플링된 feature map에서 잘립니다. 이를 위해 마스크를 필터와 multi-scale feature의 조합으로 표현하면 만족스러운 instance segmentation 성능으로 DiffusionInst를 구축하는 데 도움이 될 수 있다.
3. DiffusionInst
위와 같은 CondInst의 마스크 표현 방법을 사용하면 DiffusionInst의 데이터 샘플을 instance segmentation을 위한 필터 $x_0 = \theta$로 간주할 수 있다. DiffusionInst의 전체 프레임워크는 아래 그림에 설명되어 있다.
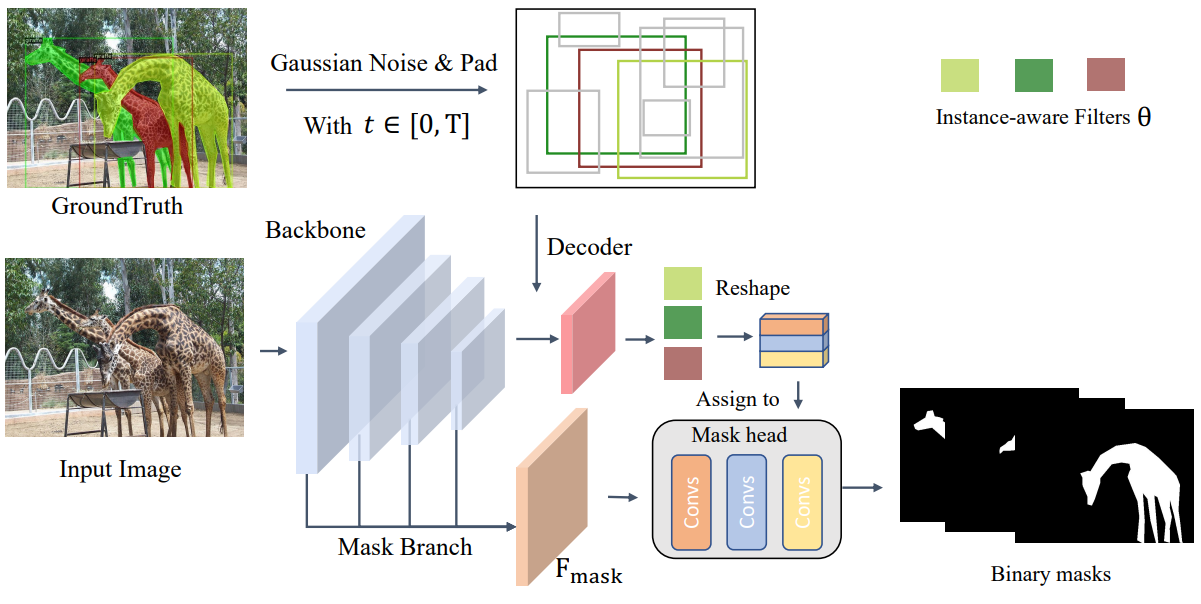
전체 아키텍처는 주로 다음 구성 요소를 포함한다.
- CNN (ex. ResNet-50)이나 Swin (ex. Swin-B) backbone을 사용하여 FPN으로 컴팩트한 visual feature 표현을 추출한다.
- FPN으로부터 여러 스케일 정보를 융합하기 위해 mask branch가 활용되며, 이는 mask feature $F_{mask} \in \mathbb{R}^{c \times H/4 \times W/4}$를 출력한다.
이 두 구성 요소는 인코더처럼 작동하며, 입력 이미지는 feature 추출을 위해 한 번만 전달한다.
- 디코더의 경우 필터와 연결된 noisy한 boundary box 집합을 입력으로 사용하여 denoising process로 box와 필터를 정제한다. 이 구성 요소는 DiffusionDet에서 빌려온 것이며 반복적으로 호출할 수 있다.
- Mask feature $F_{mask}$와 denoising 필터를 사용하여 instance mask를 재구성한다. DiffusionDet과 마찬가지로 boundary box에 최적화 대상을 유지하지만 더 나은 이해를 위해 생략한다.
Training
학습하는 동안 해당 boundary box에 의존하는 ground-truth에서 noise 필터로의 diffusion process를 구성하는 경향이 있다. Noise를 추가한 후 모델을 학습시켜 이 process를 reverse한다. 입력 이미지에 $N$개의 instacne mask $(m^{gt} \in \mathbb{R}^{N \times H \times W})$가 있다고 가정하면 분할해야 한다. 이 ground-truth box를 noisy한 box로 만들기 위해 시간 $t$를 랜덤하게 선택한다. 학습을 위한 noisy한 instance 필터도 noisy한 box feature와 하나의 fully-connected layer $\eta$로 생성된다. Ground-truth padding과 손상에 대한 디테일은 DiffusionDet에서 찾을 수 있다. 결론적으로 예측된 instance mask를 다음과 같이 얻을 수 있다 (디코더의 denoising process는 $f(b, t)$로 표시됨).
\[\begin{aligned} b_t & = \sqrt{\vphantom{1} \bar{\alpha}_t} b_0^{gt} + \sqrt{1 - \bar{\alpha}_t} \epsilon \\ \theta_0 & = \eta (f(b_t, t)) \\ m & = \phi (F_{mask}; \theta_0) \end{aligned}\]CondInst에서 사용한 dice loss를 함께 사용하여 다음과 같은 목적 함수를 얻을 수 있다.
\[\begin{equation} L_{overall} = L_{det} + \lambda L_{dice} (m, m^{gt}) \end{equation}\]$L_{det}$는 DiffusionDet의 loss이고 $\lambda = 5$로 두어 두 loss의 균형을 맞춘다. DiffusionDet을 따라 여러 디코더 단계에서 여러 supervision을 수행한다.
Inference
DiffusionDet의 inference 파이프라인은 noise에서 instance 필터로의 denoising sampling process이다. 가우시안 분포에서 샘플링한 $b_T$에서 시작하여 모델은 점진적으로 예측을 정제한다.
\[\begin{aligned} b_0 & = f(\cdots (f(b_{T-s}, T-s))), \quad s = \{0, \cdots, T\} \\ \theta_0 & = \eta (b_0) \\ m & = \phi (F_{mask}; \theta_0) \end{aligned}\]DiffusionDet과 같이 본 논문의 모델도 DDIM을 사용한다.
4. Discussion
Diffusion model을 instacne segmentation task에 성공적으로 도입했지만 일부 측면은 여전히 개선이 필요하다.
- Ground-truth 필터를 얻기 어렵기 때문에 noise-to-filter 프로세스가 여전히 boundary box에 의존한다. 저자들은 앞으로의 연구에서 boundary box의 목적 함수 없이 DiffusionInst를 직접 학습할 수 있는지 확인한다고 한다.
- Multi-step denoising의 상당한 성능 향상이 필요하다. 구체적으로 4-step denoising을 수행할 때 1% 미만의 AP만 향상된다. 저자들은 앞으로의 연구에서 DDIM 대신 새로운 샘플 전략을 연구하여 보다 효과적인 multi-step denoising을 유도하고자 한다.
- 생성 task를 처리하기 위해 diffusion model이 자연스럽게 제안되기 때문에 판별 task에서 noise-to-filter 프로세스는 정확한 instance context가 조건으로 필요하다. Instance context는 대표적인 backbone feature와 넓은 receptive field에 크게 의존한다.
- DiffusionInst는 SOLO와 Mask RCNN과 같은 표준 instacne segmentation 접근 방식보다 만족스러운 성능을 얻기 위해 더 많은 epoch을 사용한다. Inference 동안 DiffusionInst의 속도도 느리다. 더 빠른 학습과 더 효율적인 denoising process를 설계하는 방법은 필수적이지만 아직 연구되지 않았다.
Experiments
- 데이터셋: COCO, LVISv1.0 (LVIS는 COCO와 동일한 이미지를 사용하지만 긴 instacne에 집중한 데이터셋)
- Implement Details
- Backbone: ResNet-50, ResNet-101, Swin-Base, Swin-Large에 FPN 사용
- Swin transformer backbone은 224$\times$224 ImageNet22k에서 사전 학습됨
- AdamW optimizer (learning rate = $2.5 \times 10^{-5}$, weight decay = $1 \times 10^{-4}$), batch size 32
- Data augmentation: random horizontal flip, scale jitter, random crop (MixUp, Mosaic은 사용되지 않음)
- 8개의 A100 GPU로 26시간 학습
1. Comparison with State-of-the-art
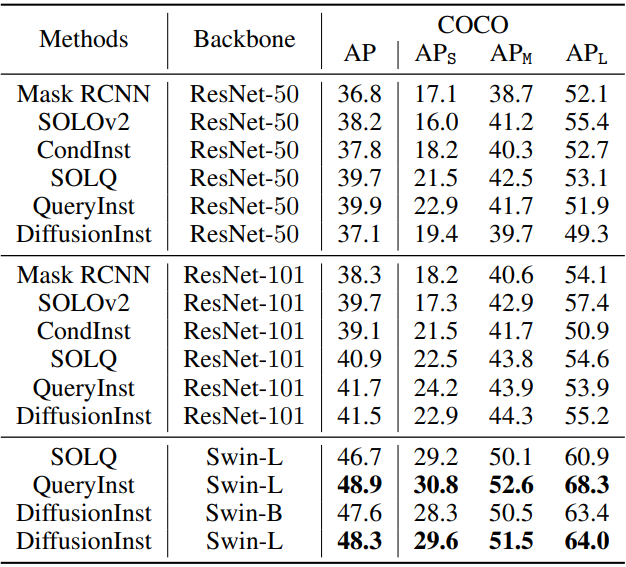
COCO validation set

위 표는 COCO validation set에서의 instacne segmentation 결과이다. 표로부터 4가지 결론을 얻을 수 있다.
- Backbone의 유연성과 capacity가 증가하면 성능이 좋아진다.
- RPN을 제거하면 instance 위치를 모델이 직접 찾아야 하므로 수렴이 느려진다.
- Multi-step denoising은 이점이 있지만 diffusion model의 경우 FPS가 감소한다.
- DiffusionInst는 큰 instacne에 대하여 성능이 좋지만 몇몇 작은 instacne는 놓친다. 이는 더 넓은 receptive field가 필요함을 뜻한다.
COCO test-dev set
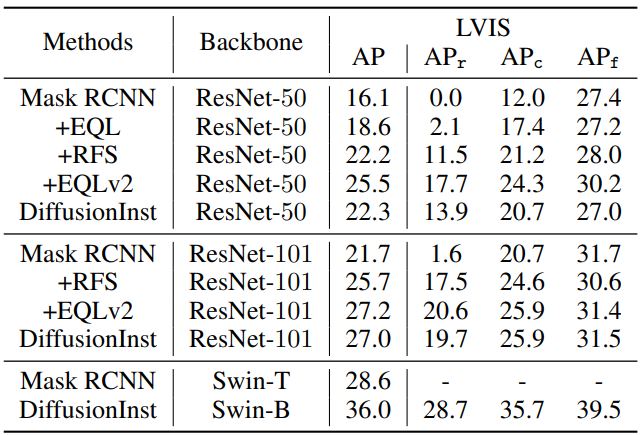
LVIS dataset
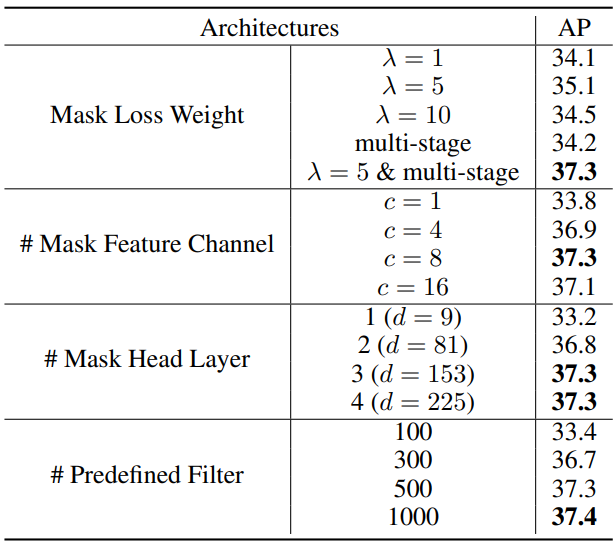
2. Ablation Studies
3. Visualizations

![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)