






arXiv 2022. [Paper] [Page]
Susung Hong, Gyuseong Lee, Wooseok Jang, Seungryong Kim
Korea University, Seoul, Korea
3 Oct 2022

Introduction
최근 denoising diffusion model은 고품질의 다양한 이미지를 합성하는 놀라온 능력을 보여주였다. 그러나 이 성능 이면의 메커니즘은 상대적으로 연구되지 않았으며 추가 연구가 필요한 블랙 박스로 남아 있다.
일반적으로 최근 diffusion model들은 아키텍처 안에 self-attention 모듈을 가지고 있다. DDPM은 self-attention과 convolution으로 구성된 UNet으로 디자인되었다. ADM은 여기서 확장하여 여러 스케일에 self-attention layer를 적용하여 성능을 개선하였다. LDM은 비슷한 아키텍처를 사용하지만 이미지 대신 latent code를 다룬다.
이런 모델들의 놀라운 성능에도 불구하고 diffusion model의 self-attnetion 연산 이면의 메커니즘이 아직 연구되지 않았다. 그 동안 여러 연구에서 ViT의 self-attention 연산의 특성을 분석하였다. DINO는 self-supervised transformer의 self-attention map이 객체에 집중하는 경향이 있고 semantic segmentation과 video object segmentation과 같은 task에 효과적이라는 것을 발견했다.
이와 관련하여 저자들은 먼저 diffusion model의 self-attention에 존재하는 특성을 조사하였다. 이를 위해 먼저 주파수 분석을 수행하여 self-attention 계층의 동작을 연구하였다. 특히 attention score가 높은 패치를 선택하여 FFT(Fast Fourier Transform)를 수행하고 주파수 요소를 모든 패치들과 비교한다.
저자들은 attention이 높은 토큰이 평균 주파수가 더 높음을 확인하였으며 attention score가 높은 패치가 일반적으로 고주파수 정보를 포함하고 있음을 확인했다. 또한 기성 object detector를 사용하여 얻은 mask와 attention score가 높은 토큰의 mask 사이의 IoU를 계산하였으며 이들이 대체로 겹치는 것을 발견했다. 이러한 결과는 이러한 영역의 특성이 인간의 지각에 중요한 요소로 알려져 있으며 photorealism과 이미지 품질에 밀접한 관련이 있다는 점에서 흥미롭다.

한편 diffusion model의 샘플링 품질을 향상시키기 위해서는 클래스 레이블이나 캡션을 사용한 guidance가 가장 중요하다는 연구 결과가 있다. 주목할만한 task에는 위 그림의 (a)에 표시된 classifier-free guidance가 있다. 이러한 방법은 종종 얻기 힘든 annotation과 추가 학습이 필요하다는 점에서 본질적으로 제한적이다.
Self-Attention의 특성에 대한 분석을 바탕으로 저자들은 추가 레이블이나 학습 없이 기존 확산 모델에 자유롭게 연결하거나 제거할 수 있는 새로운 guidance 체계, 즉 Self-Attention Guidance(SAG)를 제시한다 (위 그림의 (b)). 이는 각 timestep에서 attention score가 높은 패치를 선택적으로 흐리게 처리하고, 이 부분적으로 흐린 이미지를 diffusion model에 넣어 얻은 출력과 원래 입력을 넣어 얻은 출력을 비교하여 수행되며, 이는 guidance의 수단 역할을 한다.
Exploring Properties of the Self-Attention in Diffusion Models
일부 논문은 label-efficient semantic segmentation을 위해 diffusion model의 U-Net feature map을 활용하지만 diffusion model 내부의 self-attention map을 분석하고 활용하는 것은 아직 연구되지 않은 상태로 남아 있다.
Visualization of the self-attention
Diffusion model의 U-Net 내부의 self-attention이 특정 방식으로 동작한다는 가정하에 시각화 실험을 통해 self-attention map의 특성을 연구한다.

위 그림과 같이 저자들은 ADM의 각 이미지에 대한 object mask, frequency mask, self-attention mask를 시각화한다. Object mask와 frequency mask는 각각 기존의 Mask R-CNN과 high-pass filter를 사용하여 추출된다. Self-attention map에서 self-attention mask를 얻으려면, self-attention map을 차원 $\mathbb{R}^{HW}$로 집계하기 위해 global average pooling(GAP)을 수행하고 $\mathbb{R}^{H \times W}$로 reshape한 다음 $x_t$의 해상도와 일치하도록 nearest-neighbor upsampling을 수행한다.
$A_t$는 self-attention map이다. 추가로 timestep에 대한 $A_t$를 집계한 다음 DINO와 비슷하게 threshold를 넘는 영역만 골라 attention mask를 얻는다. 위의 시각화에서 self-attention mask가 다른 mask와 겹치는 것을 볼 수 있다.
Frequency analysis
위 그림의 시각화를 살펴보면 self-attention mask가 high-pass filter의 mask와 상당히 겹치는 것을 발견할 수 있다. 따라서 저자들은 관계를 정량적으로 측정하기로 했으며, self-attention mask와 관련된 패치에 대한 frequency 분석을 수행한다. 구체적으로 특정 값 $\psi$ 이상의 attention score를 가진 패치를 선택하고 2D FFT를 수행하고 attention score에 관계없이 모든 패치에 대해 변환을 수행한다. 그런 다음 주파수 영역에서 평균 크기를 비교한다. 이 실험에서는 각 해상도, 즉 8$\times$8, 16$\times$16 및 32$\times$32 해상도의 마지막 self-attention 모듈을 사용한다.
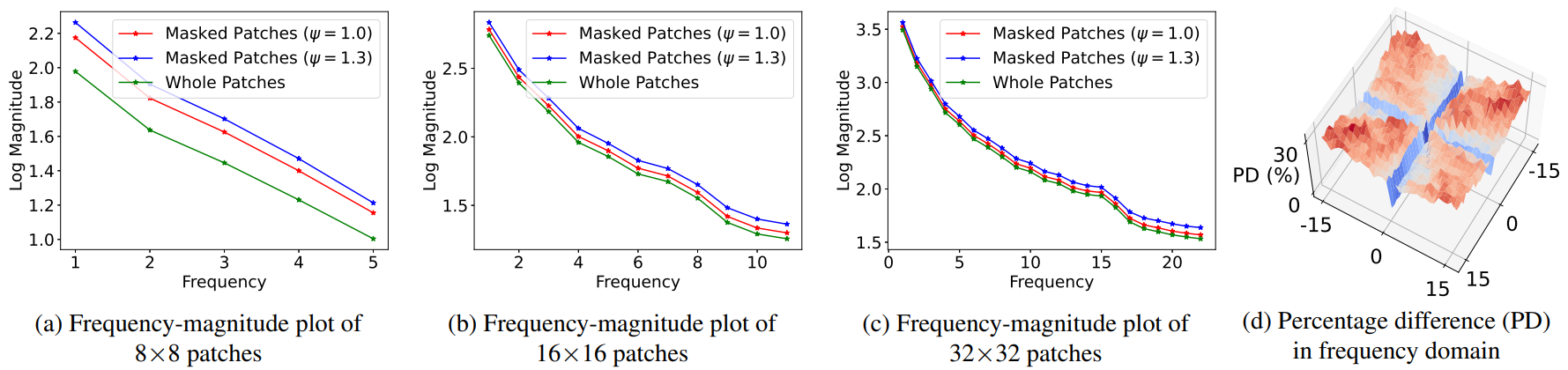
패치들의 주파수 크기 시각화는 위와 같다. Attention score가 높은 마스킹된 패치들이 마스킹되지 않은 패치보다 상대적으로 더 높은 주파수를 가짐을 보여준다. 이러한 실험 결과를 통해 diffusion model의 self-attention map 기반 mask가 텍스처와 가장자리와 같은 높은 주파수의 디테일들을 효과적으로 캡처할 수 있다고 볼 수 있다.
Semantic analysis
Diffusion model의 self-attention이 생성된 이미지의 고주파수 부분에 초점을 맞추는 반면, 저자들은 self-attention이 semantic 정보에 초점을 맞추는 경향에도 관심을 가졌다. 이를 정량적으로 측정하기 위해 COCO 2017 데이터셋으로 사전 학습된 Mask R-CNN으로 생성된 이미지의 foreground object mask를 가져오고 주파수 분석에서와 동일한 방식으로 얻은 self-attention mask로 IoU를 계산한다. 저자들은 동일한 수의 픽셀을 예측하기 위해 임의의 짝들을 설정했다.
실험 결과는 아래 표와 같다. ($\psi$는 masking threshold이다.)
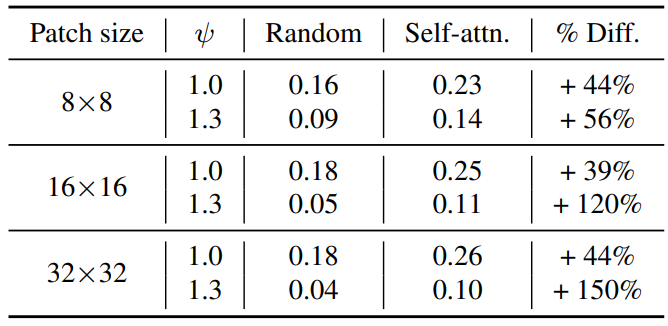
Diffusion model에서 self-attention map에 의해 생성된 mask는 완전하지 않지만 일반적인 semantic 정보를 캡처하며, self-attention map이 의미 정보에 집중하는 경향은 모든 해상도에서 attention map 전반에 걸쳐 존재한다.
Utilizing the Self-Attention Map to Improve Sample Quality
저자들은 위의 실험 결과에서 영감을 받아 diffusion model의 self-attention map을 활용하여 기존 diffusion model에 쉽게 적용할 수 있는 plug-and-play diffusion guidance인 Self-Attention Guidance(SAG)를 제안하였다.
1. Blur Guidance for Diffusion Models
물체의 텍스처, 가장자리와 같은 고주파 정보는 인간의 지각에 크게 기여한다. Gaussian blur를 사용하여 이러한 고주파수 정보로 컨디셔닝되지 않은 예측을 수행하기 위해 diffusion model을 의도적으로 방해하고 조건부 정보에 대한 guidance를 제공하면 모델이 고주파수 정보를 추가로 개발하는 데 도움이 될 수 있다. 이 방법을 blur guidance라고 한다. Gaussian blur의 결과는 원본 이미지에서 크게 벗어나지 않으므로 사전 학습된 diffusion model을 사용하여 두 입력을 모두 처리할 수 있다.
구체적으로, 가우시안 블러는 커널 크기 $k$와 표준편차 $\sigma$로 이미지에 적용된다. Blur guidance는 샘플링 시간 동안 다음과 같이 공식화된다.
\[\begin{equation} \tilde{\epsilon} (x_t) = \epsilon_\theta (\tilde{x}_t) + (1 + s) (\epsilon_\theta (x_t) - \epsilon_\theta (\tilde{x})) \end{equation}\]여기서 \(\tilde{x}_t\)는 $x_t$의 Gaussian blur를 적용한 버전이고, $s > 0$는 guidance scale이다. Guidance를 컨텐츠에 컨디셔닝하기 위하여 random noise가 아닌 \(\hat{x}_0\)에 blur가 적용되고 noise $\epsilon_\theta (x_t)$로 다시 diffuse되어 \(\hat{x}_t\)가 생성된다.
\[\begin{equation} \hat{x}_0 = \frac{x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon_\theta (x_t, t)}{\sqrt{\vphantom{1} \bar{\alpha}_t}} \\ \tilde{x}_t = \sqrt{\vphantom{1} \bar{\alpha}_t} \textrm{Blur} (\hat{x}_0) + \sqrt{1 - \bar{\alpha}_t} \epsilon_\theta (x_t, t) \end{equation}\]이와 비슷한 형태로 classifier-free guidance를 표현할 수 있다.
\[\begin{equation} \tilde{\epsilon} (x_t) = \epsilon_\theta (\tilde{x}_t) + (1 + s) (\epsilon_\theta (\tilde{x}_t, h_t) - \epsilon_\theta (\tilde{x})) \end{equation}\]$h_t = x_t - \tilde{x}_t$는 고주파 residual이고 실제로 입력 $(\tilde{x}_t, h_t)$는 $\tilde{x}_t + h_t$로 간단히 계산된다. $h_t$가 $x_t$의 고주파수 디테일을 포함하고 있기 때문에 샘플링 프로세스는 정보를 더 잘 표현하는 이미지로 guide된다.
이 방법이 fidelity를 일부 향상시킬 수는 있지만 blur guidance를 기존 방법에 직접 적용할 때 몇 가지 문제가 있다. Blur가 전역적으로 적용되기 때문에 네트워크 출력은 어떠한 원본 픽셀에도 컨디셔닝되지 않는다. 따라서 예측이 원본 이미지의 예측과 완전히 다르다.

또한 위와 같이 guidance가 배경과 부드러운 영역을 불안정하게 만들기 때문에 샘플링된 이미지의 품질 저하가 발생한다. 위가 blur guidance를 적용한 결과이고 아래가 SAG를 적용한 결과이다. Blur guidance는 불안정한 이미지를 생성한다.
2. Self-Attention Guidance for Diffusion Models
여러 실험 결과를 기반으로, 저자들은 diffusion model의 내부 self-attention map이 의미론적으로 유의미한 영역을 캡처하면서 고주파수 디테일에 초점을 맞추는 경향이 있다고 주장한다. 이러한 특성은 고주파수 정보와 의미론적 의미에도 의존하기 때문에 인간의 지각의 특성과 일치한다. 패치를 선택적으로 흐리게 하면 모델이 사실적인 이미지 생성에 필요한 디테일들을 개발하는 데 방해가 된다. 따라서 디테일로 컨디셔닝되지 않은 예측에서 컨디셔닝된 예측에 대한 guidance를 제공하여 모델이 디테일을 정교하게 만들 수 있다. 게다가 출력이 일부 원본 픽셀로 컨디셔닝되기 때문에 blur guidance의 문제를 피할 수 있다.
실질적으로 $A_t$의 평균값으로 설정되는 masking threshold $\psi$가 주어지면, self-attention guidance가 self-attention map을 따라 마스킹된 $x_t$의 패치들에만 blur를 적용한다.
\[\begin{equation} M_t = \unicode{x1D7D9} (A_t > \psi) \\ \bar{x}_t = (1 - M_t) \odot x_t + M_t \odot \bar{x}_t \\ \tilde{\epsilon} (x_t) = \epsilon_\theta (\bar{x}_t) + (1 + s) (\epsilon_\theta (x_t) - \epsilon_\theta (\bar{x}_t)) \end{equation}\]$\odot$은 Hadamard product (element-wise product)이다. Blur guidance와 다르게 $\epsilon (\bar{x}_t)$는 명시적으로 몇몇 원본 패치들로 컨디셔닝된다. 다시, 이와 비슷한 형태로 classifier-free guidance를 표현할 수 있다.
\[\begin{equation} \tilde{\epsilon} (x_t) = \epsilon_\theta (\bar{x}_t) + (1 + s) (\epsilon_\theta (\bar{x}_t, h_t^\ast) - \epsilon_\theta (\bar{x}_t)) \end{equation}\]여기서 $h_t^\ast = M_t \odot x_t - M_t \odot \tilde{x}_t$이다. $h_t$는 고주파수와 semantic 정보를 포함하는 패치들의 high-information residual이며, 클래스 레이블 역할을 한다.
SAG의 샘플링 알고리즘은 다음과 같다.

3. Generalization to Latent Diffusion Models
SAG는 latent 기반 diffusion model에 쉽게 일반화될 수 있다. 이미지 $x$ 대신 latent $z$로 이루어진 식을 사용하면 된다.
Experiments
1. Experimental Results
ADM with SAG
다음은 256$\times$256에서 사전 학습된 ADM에 SAG를 적용한 결과이다.

IDDPM with SAG
다음은 ImageNet 64$\times$64에서 사전 학습된 IDDPM에 SAG를 적용한 결과이다.
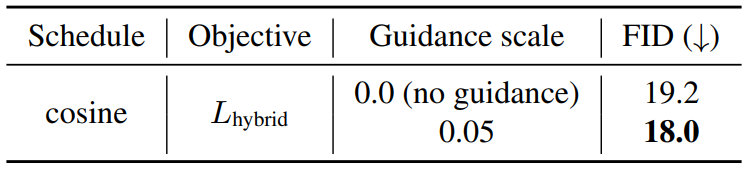
Stable Diffusion with SAG
다음은 Stable Diffusion에 SAG를 적용한 것과 적용하지 않은 것의 샘플들을 사람이 평가한 결과이다.

다음은 Stable Diffusion에 SAG를 적용하지 않은 것(위)과 적용한 것(아래)의 text-to-image 결과이다.

SAG를 적용하였을 때 더 높은 fidelity를 보인다. 신기한 점은 빈 프롬프트에 대해서도 더 좋은 성능을 보이고 있다는 것이다.
Compatibility with CG
다음은 classifier guidance (CG)와의 호환성을 나타낸 표이다.
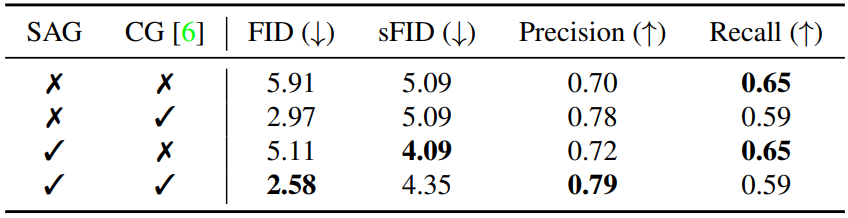
(ImageNet 128$\times$128 모델로 생성한 5만 개의 샘플로 평가)
2. Ablation Studies and Analyses
Masking strategy
다음은 다양한 마스킹 전략에 대한 샘플 품질 개선 효과를 나타낸 표이다.

다른 마스킹 전략보다 self-attention 마스킹 전략의 성능이 우수했다. Blur guidance와 같이 전역적인 마스킹을 적용할 때의 성능이 가장 좋지 못했다. 또한 각 $\hat{x}_0$에 DINO의 self-attention mask를 적용한 것이 본 논문의 방법보다 성능이 좋지 못했다. 이는 self-attention masking이 높은 샘플 품질 생성에 충분히 효과적임을 보여준다.
Masking threshold
다음은 흐려지는 영역의 비율에 영향을 주는 masking threshold $\psi$에 대한 실험이다.
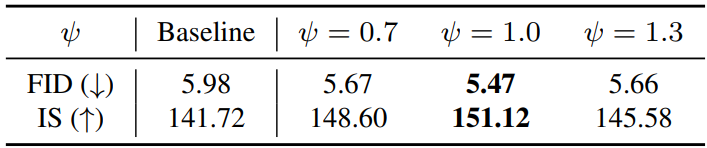
Threshold 값이 1.0일 때 성능이 가장 좋다.
Extraction layer
다음은 attention map을 추출한 layer에 대하 성능 비교 결과이다.

각 해상도에서 마지막 self-attention layer를 선택하는 것이 성능이 가장 좋았다.
Guidance scale
다음은 guidance scale의 변화에 따른 성능 변화를 평가한 결과이다.
$s = 0.1$일 때 가장 좋은 성능을 보인다.
Gaussian blur
다음은 Gaussian blur의 파라미터에 대한 실험 결과이다. $k = 31$로 고정해두고 \(\sigma \in \{1, 3, 9\}\)를 테스트한 결과이다. (128$\times$128에서 실험 진행)

$\sigma = 3$일 때 성능이 가장 좋았다.
Computational cost
다음은 SAG를 CFG와 guidance가 없는 경우와 비교한 표이다.
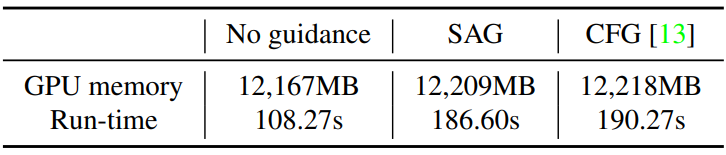
SAG의 메모리와 시간 소비가 CFG와 거의 같았다. 이는 SAG의 연산에 의한 추가 비용이 무시할 수준이라는 것을 의미한다. 반면, CFG와 마찬가지로 추가 feedforward step이 필요하므로 시간 복잡도가 guidance가 없는 경우와 비교했을 때 상대적으로 높다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)