






arXiv 2022. [Paper] [Page]
Kihong Kim, Yunho Kim, Seokju Cho, Junyoung Seo, Jisu Nam, Kychul Lee, Seungryong Kim, KwangHee Lee
VIVE STUDIOS | Korea University
27 Dec 2022
Introduction
최근 대부분의 face swapping task는 GAN 기반이지만 GAN은 min-max 최적화 문제 때문에 본질적으로 불안정하다. 이 문제를 완화하기 위하여 복잡한 아키텍처, 다양한 손실 함수, hyperparameter 튜닝 등이 필요하다.
Face swap task는 타겟 이미지의 얼굴 속성 (표정, 포즈, 모양 등)을 보존하면서 소스 이미지의 ID의 이미지를 합성한다. 그렇기 때문에 특정 목적애 대하여 학습한 expert model을 사용할 수 있다. 예를 들어 ID embedder를 사용하여 합성 이미지의 ID가 소스 이미지의 ID를 따르도록 강제할 수 있다.
그럼에도 ID와 얼굴 속성의 균형을 맞추는 것이 가장 어려운 문제이다. GAN 기반의 모델들은 ID와 얼굴 속성에 관한 손실 함수의 결합으로 이 균형을 유지한다. 반면, 최적의 hyperparameter를 찾기 위해서는 여러 번의 학습이 필요하다. ID와 얼굴 속성 사이의 trade-off 때문에 자연스러운 얼굴 속성을 유지하는 것에 지나치게 집중하게 되면 소스 이미지의 ID가 만족스럽게 반영되기 힘들다.
최근 diffusion model들이 GAN을 대체하는 것이 큰 관심을 받고 있다. Diffusion model들은 GAN과 다르게 더 안정적인 학습이 가능하며 다양성과 품질 모두 만족할만한 결과가 나타난다.
다양성과 품질 사이의 trade-off를 해결하기 위해 classifier guidance가 제안되었다. 이러한 guidance 테크닉은 조건부 생성에서 광범위하게 사용된다. Guidance 테크닉의 다양한 장점에도 불구하고 guidance로 외부 모듈의 유용성에 단점이 있다.
본 논문에서는 diffusion 기반의 face swap 프레임워크인 DiffFace를 제안한다. DiffFace는 ID Conditional DDPM의 학습, facial guidance를 사용한 샘플링, target-preserving blending 전략으로 구성된다.
먼저 학습 단계에서는 ID Conditional DDPM이 목표 ID로 이미지를 생성하도록 학습된다. 저자들은 ID embedder에서 나오는 ID feature를 주입하는 것 뿐만 아니라 ID similarity loss로 추가 제약을 건다.
샘플링 단계에서는 이미 학습된 다양한 expert model을 사용한 facial guidance로 소스 이미지의 ID를 전달하면서 타겟 이미지의 얼굴 속성을 보존한다.
저자들은 추가로 타겟 이미지의 배경을 보존하고 목표하는 face swapping 결과를 얻기 위해서 target-preserving blending 전략을 제안한다. Diffusion process가 진행됨에 따라 facial mask의 강도를 점진적으로 증가시켜 소스의 ID를 전달하는 과정에서 모델이 타겟의 얼굴 속성을 완전히 잊어버리는 것을 방지한다.
또한, 다양한 facial guidance를 유연하게 적용할 수 있어 ID와 속성 사이의 trade-off를 적절히 조절하여 재학습 없이 목표 결과를 달성할 수 있다. GAN 기반의 face swapping 모델과 비교했을 때 DiffFace는 학습 안정성과 고품질, 조절 가능성 등에서 이점이 있다.
Preliminaries: DDPM
Diffusion model은 noising process를 뒤집어 표준 가우시안 분포에서 사실적인 이미지를 생성한다. Forward process는 점진적으로 가우시안 분포에서 데이터 분포로 교체하며, 사전 정의된 분산 schedule $\beta_t$에 대하여 다음과 같이 정의된다.
\[\begin{equation} q(x_t \vert x_{t-1}) := \mathcal{N} (x_t; \sqrt{1- \beta_t} x_{t-1}, \beta_t I) \end{equation}\]Reverse process는 다음과 같다.
\[\begin{equation} p_\theta (x_{t-1} \vert x_t) := \mathcal{N} (x_{t-1}; \mu_\theta (x_t, t), \sigma_\theta (x_t, t)I) \end{equation}\]여기서 $\mu_\theta$와 $\sigma_\theta$는 신경망으로 parameterize할 수 있다. 하지만 실제로는 noise 근사 모델 $\epsilon_\theta (x_t, t)$를 $\mu_\theta (x_t, t)$ 대신 사용하는 것이 성능이 좋다. 따라서 $\mu_\theta (x_t, t)$는 다음과 같이 구할 수 있다.
\[\begin{equation} \mu_\theta (x_t, t) = \frac{1}{\sqrt{1 - \beta_t}} (x_t - \frac{\beta_t}{\sqrt{1- \alpha_t}} \epsilon_\theta (x_t, t)) \end{equation}\]주어진 $x_t$에 대하여 reverse process는 $x_{t-1}$을 출력한다. 하지만 바로 noise가 모두 제거된 $\hat{x}_0$를 구할 수 있다.
\[\begin{equation} \hat{x}_0 = f_\theta (x_t, t) := \frac{x_t - \sqrt{1-\alpha_t} \epsilon_\theta (x_t, t)}{\sqrt{\alpha_t}} \end{equation}\]본 논문에서는 $\hat{x}_0$를 facial expert module에 사용한다.
한편, ADM은 diffusion model을 위한 guidance 테크닉을 제시하였다. ADM은 classifier $p(y\vert x_t, t)$를 학습시킨 후 classifier의 기울기를 guidance로 사용한다.
\[\begin{equation} p_\theta (x_{t-1} \vert x_t, y) := \mathcal{N} (\mu + s \nabla_{x_t} p (y \vert x_t, t), \sigma I) \end{equation}\]여기서 $s$는 guidance scale을 위한 상수이며 $\mu = \mu_\theta (x_t, t)$와 $\sigma = \sigma_\theta (x_t, t)$이다.
ADM에서 사용한 guidance 테크닉은 unconditional diffusion model을 사용하며 본 논문에서 사용하는 ID Conditional DDPM과 다르다. 그럼에도 diffusion model에 다양한 guidance 테크닉을 추가하는 것은 강한 일반화 능력을 보장해주므로 장점이 있으며, 아래에서 설명할 어려움 때문에 face swapping에 diffusion model을 사용하는 것이 연구되지 못하였다.
Methodology

$x_\textrm{src}$, $x_\textrm{targ}$, $x_\textrm{swap}$은 각각 소스 이미지, 타겟 이미지, 합성 이미지를 나타낸다. 또한 $\mathcal{D}$는 사전 학습된 guidance 신경망을 나타내며, 구체적으로 $\mathcal{D}_I$는 identity embedder, $\mathcal{D}_F$는 face parser, $\mathcal{D}_G$는 gaze estimator이다.
1. ID Conditional DDPM
Diffusion model로 face swapping을 하기 위한 주요 아이디어는 ID feature를 diffusion model에 주입하는 것이다. 기존 방법들은 이러한 컨디셔닝 문제를 광범위하게 연구했지만 diffusion model에 조건으로 ID 정보를 주입하는 연구는 없었다.
따라서, 저자들은 추가 정보가 주입될 수 있도록 conditional diffusion model의 구조를 사용한다.
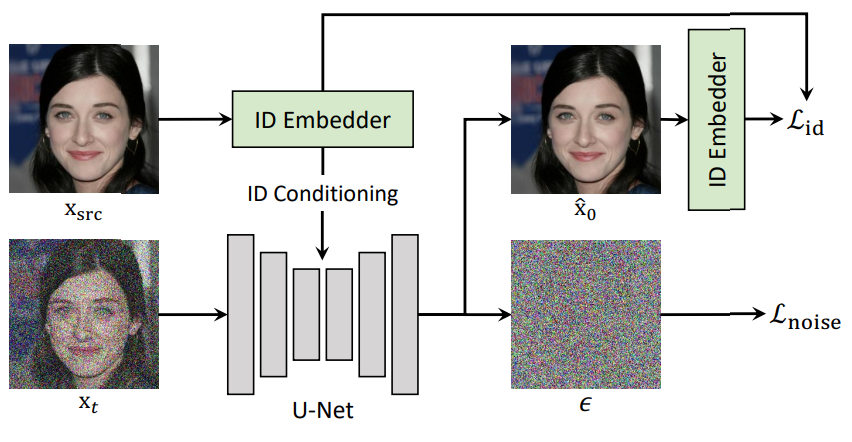
위 그림에서 볼 수 있듯이 먼저 $x_\textrm{src}$를 \(\mathcal{D}_I\)에 넣어 소스의 ID \(v_\textrm{id}\)를 얻는다.
그런 다음 $v_\textrm{id}$를 diffusion model $\epsilon_\theta (x_t, t, v_\textrm{id})$에 넣는다. 여기서 $x_t$는 $x_\textrm{src}$의 timestep $t$에서의 이미지를 계산한 것이다.
Loss Functions
DiffFace는 forward process를 뒤집는 reverse process를 학습한다. 주어진 $x_t$에 대하여 ID Conditional DDPM은 denoising score matching loss로
\[\begin{equation} \mathcal{L}_\textrm{noise} = \| \epsilon - \epsilon_\theta (x_t, t, v_\textrm{id}) \|_2^2 \end{equation}\]를 이용하여 $v_\textrm{id}$를 보존하는 noise를 예측한다. 여기서 $\epsilon$는 $x_t$에 추가된 noise이다.
저자들은 추가로 identity loss를 사용하여 얼굴의 ID를 효과적으로 보존한다. Expert model이 깨끗한 이미지로 학습되었기 떄문에 각 $x_t$에서 $\hat{x}_0$를 추정하여 사용한다.
\[\begin{equation} \hat{x}_0 = f_\theta (x_t, t, v_\textrm{id}) \end{equation}\]여기서 $f_\theta$는 noise가 모두 제거된 이미지를 추정한 것이다. \(\hat{x}_0\)에 대한 ID \(\hat{v}_\textrm{id}\)를 구한 뒤 $v_\textrm{id}$와 모든 timestep $t$에서 같도록 학습한다. 이를 위하여 다음과 같은 identity loss를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{id} = 1- \cos (v_\textrm{id}, \hat{v}_\textrm{id}) \end{equation}\]ID Conditional DDPM을 위한 전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{total} = \mathcal{L}_\textrm{id} + \lambda \mathcal{L}_\textrm{noise} \end{equation}\]전체 학습 과정에 대한 알고리즘은 아래와 같다.

2. Facial Guidance
생성된 이미지의 얼굴 속성을 조작하기 위하여 diffusion process동안 적용되는 facial guidance를 사용한다. Diffusion model을 사용하는 것의 장점 중 하나는 모델이 한번 학습되면 샘플링 단계에서 guidance를 통해 이미지를 조작할 수 있다는 것이다. 따라서 재학습 없이 목표 이미지를 얻을 수 있다.
이러한 장점을 활용하기 위해서 identity embedder, face parser, gaze estimator와 같은 외부 모델을 사용하여 facial guidance를 준다. 어떤 facial model이라도 사용할 수 있으며, 사용자의 목적에 맞게 선택하면 된다.
Identity Guidance
소스 이미지의 ID 정보를 전달하기 위하여 ID Conditional DDPM을 사용하지만, 이 ID 컨디셔닝만 사용하면 합성된 결과 이미지가 소스 이미지의 ID 정보를 잃는다. 이는 모델이 segmentation이나 gaze와 같은 구조적 정보만을 주목하여 소스 이미지의 ID를 유지하는데 실패하는 것이다.
따라서 저자들은 identity guidance를 주어 diffusion process에서 소스 이미지의 ID를 잃는 것을 막는다. 구체적으로 소스 이미지와 생성된 이미지의 ID 벡터가 ID embedding space에서 가깝도록 강제한다. Facial identity guidance는 다음과 같다.
\[\begin{equation} \mathcal{G}_\textrm{id} = 1 - \cos \bigg( \mathcal{D}_I (x_\textrm{src}), \mathcal{D}_I (\hat{x}_0) \bigg) \end{equation}\]Semantic Guidance
합성 이미지의 facial feature를 타겟 이미지의 facial feature와 매칭하기 위하여 얼굴 요소들의 pixel-wise label을 예측하는 face parsing model (BiSeNet)을 사용한다.
DiffFace는 샘플링의 앞부분에서는 ID expert로 가이드 된 이미지를 생성한다. 그런 다음 semantic guidance가 점진적으로 타겟 이미지의 얼굴 요소를 따르도록 생성 이미지를 유도한다. 결국 생성된 이미지는 타갯 이미지와 비슷한 표정, 포즈, 모양 등을 가지게 된다.
이 과정에서 피부, 눈, 눈썹 같이 필수적인 레이블으로 facial parsing map을 구성하고, 머리카락이나 안경 같은 얼굴과 관련 없는 요소는 제외된다. 그런 다음 두 feature 사이의 거리를 계산한다.
Semantic guidance는 다음과 같다.
\[\begin{equation} \mathcal{G}_\textrm{sem} = \| \mathcal{D}_F (x_\textrm{targ}) - \mathcal{D}_F (\hat{x}_0) \|_2^2 \end{equation}\]Gaze Guidance
시선 정보는 컨텍스트와 감정을 전달하는 데 큰 역할을 하며, face swap 테크닉에서 타겟 이미지의 시선을 보존하는 것은 중요한 문제이다. 그럼에도 불구하고 기존 모델들은 타켓 이미지의 시선을 보존하는 데 실패했는데, 이는 명시적인 시선 모델링이 없어 시선을 충분히 guide하지 못했기 때문이다. 또한, diffusion stochastic process 때문에 합성된 결과는 같은 입력에 대해서도 다른 시선을 갖는다. 따라서, 이 문제를 해결하기 위하여 사전 학습된 gaze estimator로 명시적으로 타겟 이미지와 시선이 다르면 페널티를 준다.
저자들은 먼저 상용 얼굴 랜드마크 감지 도구를 이용하여 두 눈의 좌표를 얻는다. 그런 다음 좌표를 이용하여 합성된 이미지와 타겟 이미지의 눈을 오려낸다. 오려낸 눈 이미지를 사전 학습된 gaze estimator에 넣어 시선 벡터를 얻는다. 마지막으로 두 시선 벡터의 거리를 계산하여 gaze guidance로 사용한다. Gaze guidance는 다음과 같다.
\[\begin{equation} \mathcal{G}_\textrm{gaze} = \| \mathcal{D}_G (x_\textrm{targ}) - \mathcal{D}_G (\hat{x}_0) \|_2^2 \end{equation}\]Incorporationg Guidances
샘플링 프로세스를 목표 이미지로 guide하기 위해서 facial guidance module을 기울기를 통합한다. Classifier의 기울기를 사용하여 guidance를 한 것처럼 facial expert model의 기울기를 사용하여 guidance할 수 있다.
Diffusion model $\epsilon_\theta$와 사전 학습된 expert model들이 주어지면 조건부 샘플링 프로세스를 유도할 수 있다. 통합 guidance를 사용한 전체 샘플링 과정은 다음과 같다.
\[\begin{equation} x_{t-1} \sim \mathcal{N} (\mu - \sigma \nabla_{x_t} \mathcal{G}_\textrm{facial}, \sigma) \\ \mu = \mu_\theta (x_t, t, v_\textrm{id}), \quad \sigma = \sigma_\theta (x_t, t, v_\textrm{id}), \\ \mathcal{G}_\textrm{facial} = \lambda_\textrm{id} \mathcal{G}_\textrm{id} + \lambda_\textrm{sem} \mathcal{G}_\textrm{sem} + \lambda_\textrm{gaze} \mathcal{G}_\textrm{gaze} \end{equation}\]여기서 $\mu_\theta$는 \(p_\theta(x_t \vert x_{t-1}, v_\textrm{id})\)의 예측된 평균이다.
Facial guidance의 전체 프로세스는 다음과 같다.

3DMM이나 face pose estimation과 같은 추가 facial expert model을 샘플링 과정에 사용하면 타겟의 얼굴 속성을 보존하도록 결과를 개선할 수 있다.
3. Target-Preserving Blending
Face swap task에 그냥 diffusion model을 사용하면 타겟 이미지의 배경을 보존하는 데 실패한다. 왜냐하면 모든 영역에 noise가 추가되기 때문이다. 타겟 이미지의 배경을 보존하기 위해서 저자들은 semantic facial mask를 출력하는 face parser (BiSeNet)를 활용한다.
합성된 결과에 target hard mask $M$를 element-wise product하여 타겟 이미지의 배경을 보존하고 소스 이미지의 얼굴 ID를 전달할 수 있다. 기존 방법들은 2개의 noisy한 이미지에 binary mask를 blend한다. 하지만 이러한 방법은 강한 mask 강도 때문에 noise가 타겟 이미지의 구조적 속성을 제거한다.
본 논문에서는 타겟 이미지의 구조적 속성을 더 잘 보존하도록 mask 강도를 변경하는 target-preserving blending 방법을 제안한다. 이 방법은 diffusion process가 진행됨에 따라 mask의 강도를 0에서 1로 점진적으로 증가시킨다. Mask 강도가 1이 되는 지점을 조절하면 타겟 이미지의 구조를 적절하게 유지할 수 있다. 이러한 방법을 통해 효과적으로 ID와 구조적 속성 사이의 trade-off를 조절할 수 있다.
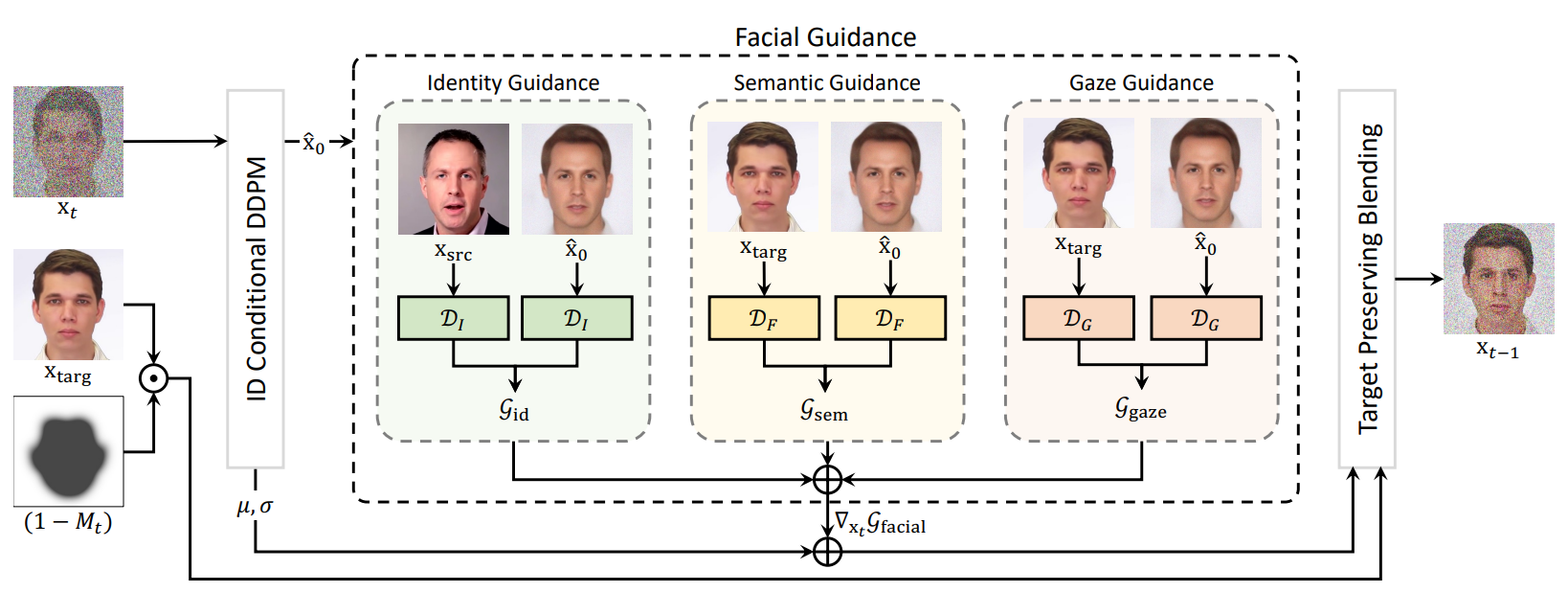
위 그림은 target-preserving blending의 과정을 보여준다. $M$은 face parser로 구한 hard mask이고 $M_t$는 $t$에 따라 강도가 조절되는 soft mask이다. $\hat{T}$는 mask 강도가 1이 되어 hard mask가 되는 지점이다. $M_t$는 다음 식으로 계산할 수 있다.
Reverse process의 중간 예측과 타겟 이미지를 $M_t$로 섞는다. 먼저 \(x_{t-1}\)을 \(\hat{x}_{t-1}\)로 다시 정의한다.
\[\begin{equation} \hat{x}_{t-1} \sim \mathcal{N} (\mu - \sigma \nabla_{x_t} \mathcal{G}_\textrm{facial}, \sigma) \end{equation}\]그런 다음 \(x_\textrm{targ}\)와 \(\hat{x}_{t-1}\) 사이의 noise level을 맞추기 위하여 noisy한 타겟 이미지 \(x_{t-1, \textrm{targ}}\)를 계산한다. 마지막으로 \(\hat{x}_{t-1}\)과 \(x_{t-1, \textrm{targ}}\)를 섞는다.
\[\begin{equation} x_{t-1} = \hat{x}_{t-1} \odot M_t + x_{t-1, \textrm{targ}} \odot (1- M_t) \end{equation}\]\(x_\textrm{swap}\)은 $t = 1$일 때 위 식의 결과로 정의한다.
Experiment
- Training
- ID Conditional DDPM: Wide ResNet 기반의 U-Net
- 데이터셋: FFHQ (7만 장, 256$\times$256)
- $\lambda = 0.5$
- Adam optimizer (learning rate = 0.0001)
- Batch size = 48, 70만 step (NVIDIA A100 PCIe 80GB GPU 8개로 10일)
- Sampling
- 8개의 extending augmentation 사용
- $T = 75$, $\lambda_\textrm{id} = 2000$, $\lambda_\textrm{sem} = 150$, $\lambda_\textrm{gaze} = 200$
다음은 다른 모델들과의 비교이다.

다음은 FaceForensics++ 데이터셋에 대한 성능 평가 비교이다.
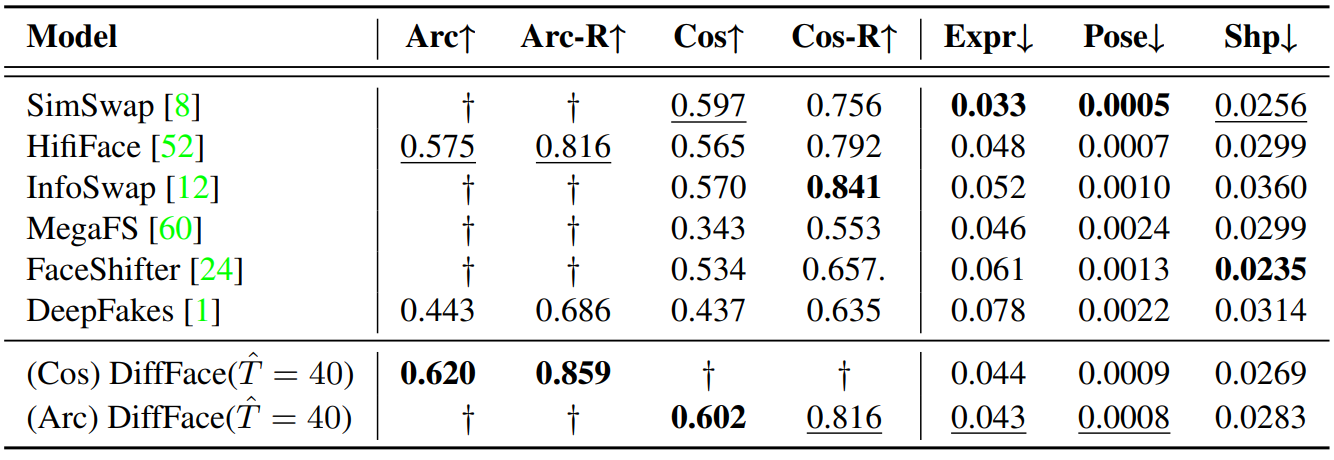
Arc는 ArcFace, Cos는 CosFace를 의미하며 각 embedder로 $x_\textrm{swap}$과 $x_\textrm{src}$에서 각각 추출한 벡터 간의 거리를 지표로 사용하였다. 뒤에 R이 붙는 것은 $x_\textrm{targ}$도 고려하여 다음 식으로 계산한 것이다.
다음은 FaceForensics++ 데이터셋에서 다양한 설정에 대한 성능 평가이다.
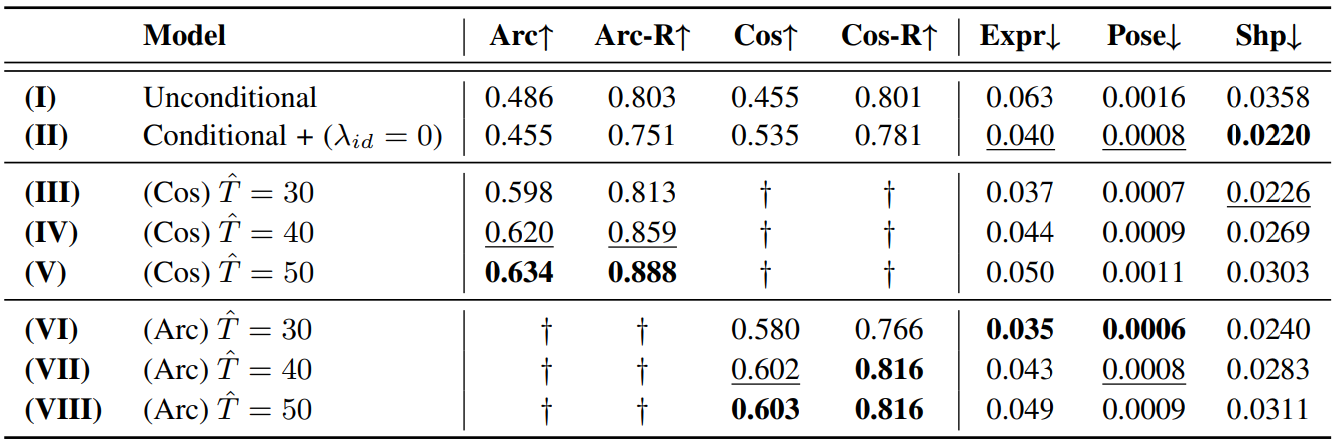
\(\lambda_\textrm{id} = 0\)은 identity guidance를 사용하지 않았다는 의미이다.
다음은 DiffFace의 각 중요 요소에 대한 ablation study 결과이다.

다음은 ID와 얼굴 모양 사이의 trade-off를 나타낸 그림이다.
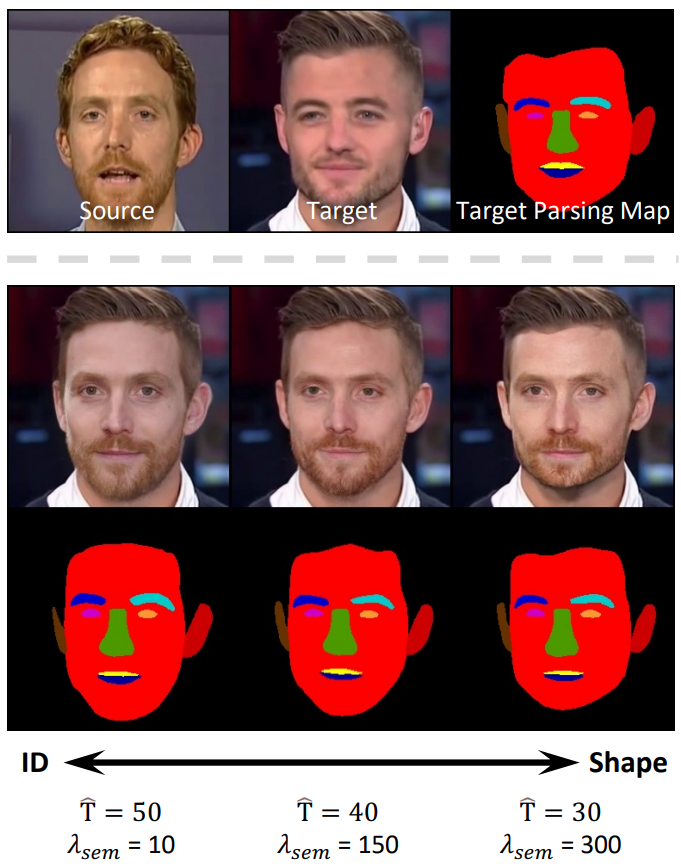
얼굴 모양에 변화를 주려면 $\hat{T}$를 키우고 $\lambda_\textrm{sem}$을 줄이면 된다. 반대로 타겟 이미지의 얼굴 구조를 보존하려면 $\hat{T}$를 줄이고 $\lambda_\textrm{sem}$을 키우면 된다. 위 그림에서는 얼굴 모양 대신 ID에 힘을 줄 수록 턱 모양 점점 둥그렇게 되는 것을 볼 수 있다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)