






CVPR 2022. [Paper] [Github]
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, Luc Van Gool
Computer Vision Lab, ETH Zurich, Switzerland
24 Jan 2022

Introduction
Image inpainting은 이미지의 빠진 영역을 채우는 것을 목표로 하며, 주변 이미지와 의미론적으로 자연스럽게 채워야 한다. 기존의 state-of-the-art 모델은 GAN 기반이거나 autoregressive 모델이였다.
Inpainting 방법들은 다양한 종류의 mask를 다룰 수 있어야 하며, 심할 경우 대부분의 이미지를 채워야 하는 경우도 존재한다. 기존 방법들은 특정 mask 분포에 대해서 학습되었기 때문에 다양한 mask 종류에 대하여 일반화가 거의 되지 않는다. 본 논문은 diffusion model을 이용하여 특정 mask에 의존하는 학습이 필요 없도록 하는 것이 목표이다.
DDPM은 생성 모델링의 새로운 패러다임을 제시하였다. DDPM은 GAN 기반의 state-of-the-art 방법들보다 이미지 생성 분야에서 더 성능이 우수하다. 또한 다양하면서도 품질이 좋은 이미지를 잘 생성해낸다.
저자들은 unconditional하게 학습된 기존 DDPM만을 활용하는 inpainting 방법인 RePaint를 제안한다. Mask 조건부 생성 모델을 학습하는 대신 reverse diffusion iteration 중에 주어진 픽셀에서 샘플링하여 생성 프로세스를 조절한다. 따라서 RePaint는 inpainting task 자체를 학습하지 않는다. 이러한 방법은 2가지 이점이 있다.
- 신경망이 inference 중에 어떤 mask에 대해서도 일반화가 가능하다.
- 강력한 DDPM 이미지 합성 prior가 있으므로 더 의미론적인 생성을 학습할 수 있게 한다.
표준 DDPM 샘플링 방법은 그럴듯한 이미지를 생성하지만 inpainting의 관점에서 종종 의미상 올바르지 않은 이미지를 생성한다. 따라서 저자들은 이미지를 더 컨디셔닝하기 위하여 resampling하는 개선된 denoising 전략을 도입한다. 물론 이 방법이 diffusion process를 느리게 하지만, forward와 backward를 동시에 진행하여 의미론적으로 알맞은 이미지를 생성한다. 또한 신경망이 효과적으로 생성된 이미지를 조화롭게 만드며 더 효과적인 컨디셔닝을 가능하게 한다.
Method
1. Conditioning on the known Region
Inpainting의 목표는 mask를 조건으로 하여 이미지의 빠진 픽셀을 예측하는 것이다. 앞으로 이미 학습된 unconditional DDPM이 있다고 생각한다. Elementwise product를 $\odot$로 나타내면, mask가 $m$일 때 모르는 픽셀은 $m \odot x$로 표현할 수 있고 아는 픽셀은 $(1-m) \odot x$로 나타낼 수 있다.
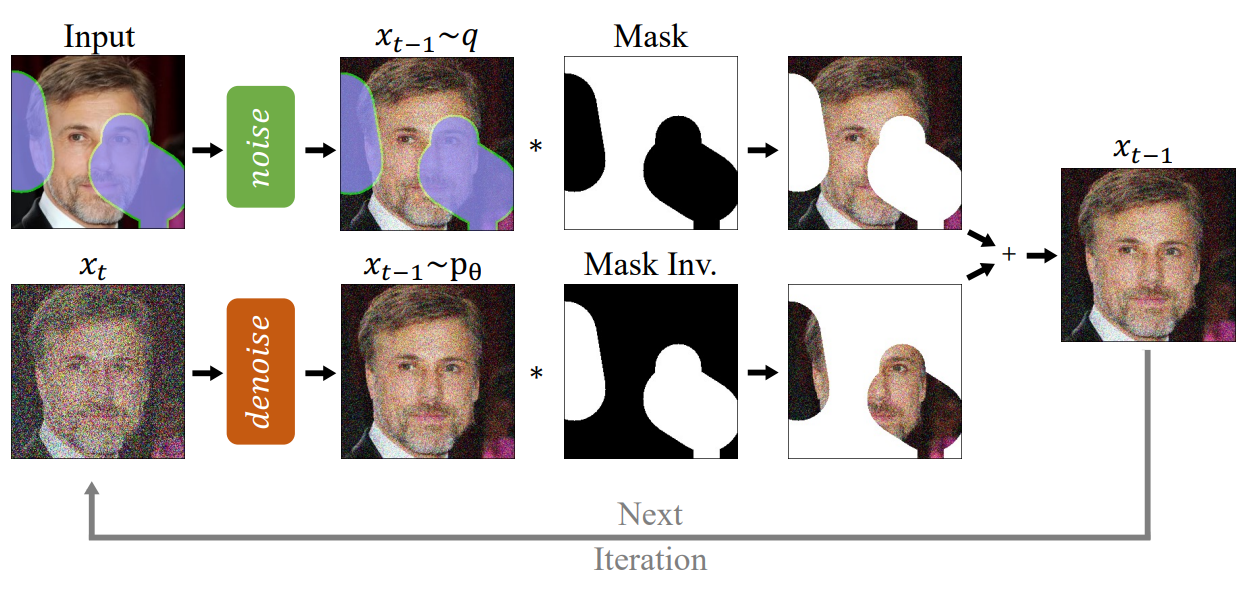
$x_t$에서 $x_{t-1}$로 가는 reverse step에 대하여, 해당 분포의 올바른 속성을 유지하는 한 모르는 영역 $m \odot x_t$를 $m \odot x_{t-1}$로 대체할 수 있다.
또한 임의의 중간 이미지 $x_t$를
\[\begin{equation} q(x_t | x_0) = \mathcal{N} (\sqrt{\vphantom{1} \bar{\alpha}_t} x_0, (1-\bar{\alpha}_t)I) \end{equation}\]로 샘플링할 수 있기 때문에 아는 영역 $(1-m) \odot x_t$를 임의의 시간 $t$에서 샘플링할 수 있다.
즉, 아는 영역은 forward process로 구하고 모르는 영역은 reverse process로 구하는 것이다. 정리하면 다음과 같이 $x_{t-1}$을 구할 수 있다.
\[\begin{aligned} x_{t-1}^\textrm{known} & \sim \mathcal{N} (\sqrt{\vphantom{1} \bar{\alpha}_t} x_0, (1-\bar{\alpha}_t)I) \\ x_{t-1}^\textrm{unknown} & \sim \mathcal{N} (\mu_\theta (x_t, t), \Sigma_\theta (x_t, t)) \\ x_{t-1} &= (1-m) \odot x_{t-1}^\textrm{known} + m \odot x_{t-1}^\textrm{unknown} \end{aligned}\]2. Resampling

만일 위 방법을 바로 적용하면 아는 영역과 매칭되도록만 모르는 영역이 채워진다. 예를 들어 위 그림에서 $n = 1$인 경우 개의 털과 매칭되어 inpainting되었다. 채워진 영역이 주변과 매칭되지만 의미적으로는 부정확하다. 따라서 DDPM은 아는 영역의 컨텍스트를 활용하지만 이미지의 나머지 부분과 잘 조화되지 않는다.
이런 양상이 보이는 가능성 있는 이유는 다음과 같다. 모델은 $x_t$를 이용하여 $x_{t-1}$을 예측하는데, 이는 DDPM의 output으로 구성된다. 하지만 아는 영역을 샘플링하는 것은 생성된 영역을 고려하지 않고 수행된다.
그럼에도 불구하고 모델은 매 step마다 이미지를 조화롭게 만들려고 하며, 다음 step에서도 같은 문제가 발생하기 때문에 이는 절대 충분히 수렴하지 않는다. 또한, 각 reverse step에서 이미지의 최대 변화량은 $\beta_t$에 의해 점점 감소한다.
따라서 이 방법은 제한된 유연성으로 인해 후속 step에서 경계가 조화롭지 못하게 되는 것을 수정할 수 없다. 결과적으로 다음 denoising 단계로 넘어가지 전에 조건 정보 $x_{t-1}^\textrm{known}$과 생성 정보 $x_{t-1}^\textrm{unknown}$을 조화시키는 데 더 많은 시간이 필요하다.
DDPM은 데이터 분포를 따르며 이미지를 생성하도록 학습되기 때문에 자연스럽게 일관된 구조를 생성한다. 저자들은 이러한 DDPM의 특성을 이용하여 입력을 조화롭게 만든다.
이를 위해 $x_{t-1}$를 다시 $x_t$로 diffuse한다. 이 연산은 output을 축소하고 noise를 추가하지만 생성된 영역 $x_{t-1}^\textrm{unknown}$에 통합된 일부 정보는 $x_t^\textrm{unknown}$로 여전히 보존된다. 이를 통해 새로운 $x_t^\textrm{unknown}$는 $x_t^\textrm{known}$에 의해 더 조화로워지고 더 많은 조건 정보를 가지게 된다.
위의 연산은 하나의 step만을 조화롭게 할 수 있기 때문에 전체 denoising process의 의미 정보를 통합하지 못할 수도 있다. 이러한 문제를 해결하기 위하여 이 연산의 반복 횟수를 jump length $j$로 표시하며, 이전 사례의 경우 $j = 1$이다.
Diffusion models beat GANs on image synthesis 논문 (Paper review)의 slowing down과 비슷하게 resampling도 reverse diffusion의 실행시간을 증가시킨다. Slowing down은 각 denoising step에서 추가된 분산을 줄여 더 작지만 더 많은 resampling step을 적용한다. 그러나 diffusion을 늦추면 설명한 대로 여전히 이미지가 조화되지 않는 문제가 있기 때문에 근본적으로 다른 접근 방식이다.
RePaint의 inpainting 알고리즘은 다음과 같다.

Experiments
- 데이터셋: CelebA-HQ, ImageNet
- Diffusion models beat GANs on image synthesis 논문의 ImageNet 모델 사용
- CelebA-HQ의 경우 ImageNet과 동일한 hyper-parameter 사용, 25만 iteration 동안 학습
- Timestep $T = 250$, resampling 횟수 $r = 10$, jumpy size $j = 10$
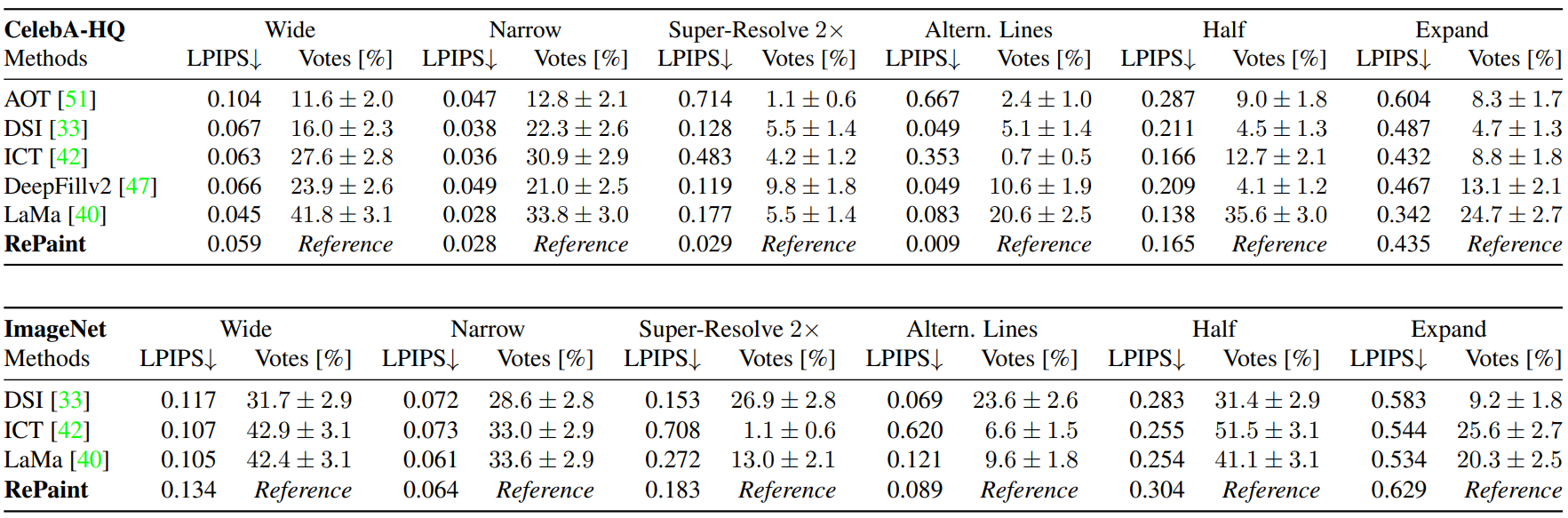
1. Comparison with State-of-the-Art
다음은 state-of-the-art 모델과의 비교이다. 왼쪽 이미지는 CelebA-HQ, 오른쪽 이미지는 ImageNet에 대한 결과이다.


2. Analysis of Diversity
이미지에서 RePaint의 다양성과 유연성을 볼 수 있다.
3. Class conditional Experiment
사전 학습된 ImageNet DDPM은 클래스 조건부 생성이 가능하다. 다음은 “Granny Smith” 클래스에 해당하는 이미지에 “Expand” mask를 적용하여 다른 클래스로 샘플링한 예시이다.

4. Ablation Study
Comparison to slowing down
다음은 같은 연산량에서의 resampling과 slowing down을 비교한 결과이다.


Resampling이 이미지를 조화롭게 만드는 데에 더 많은 연산량을 사용하는 것을 알 수 있으며, slowing down은 시각적인 개선이 없다.
Jumps Length
다음은 jump length $j$와 resampling 횟수 $r$에 대한 ablation study 결과이다.
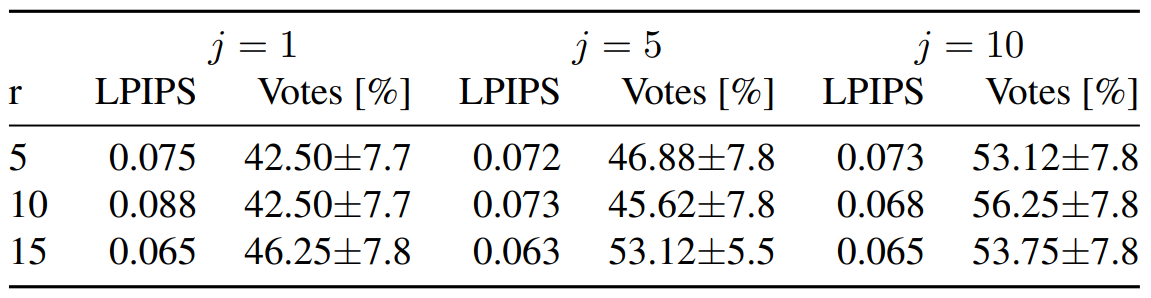
$j = 1$에 대하여 DDPM은 흐릿한 이미지를 출력하며, 여러 $r$에서 이런 결과가 나타난다. 또한 $r$이 증가하면 성능이 증가한다.
Comparison to alternative sampling strategy
다음은 SDEdit 논문에서 제안한 resampling 방법과의 LPIPS 비교이다.

“Expand”를 제외한 모든 mask 종류에 대하여 RePaint가 더 좋은 성능을 보였다. 0.6보다 큰 LPIPS는 의미있는 비교가 가능한 범위 밖이기 때문에 사실상 모든 mask 종류에 대하여 RePaint가 더 좋다고 볼 수 있다. 또한 super-resolution mask의 경우 모든 데이터셋에서 LPIPS를 53% 이상 감소하였으며, RePaint의 resampling의 장점을 잘 보여준다.
Limitations
RePaint는 굉장히 디테일하며 의미론적으로 유의미한 이미지를 생성한다. 하지만 2가지 한계점이 존재한다.
- 다른 diffusion 기반 모델과 마찬가지로 RePaint는 GAN 기반 모델이나 autoregressive 기반 모델보다 느리다는 한계점이 있다. 이는 모델의 실시간 적용을 힘들게 한다. 최근 DDPM의 인기로 다양한 논문에서 diffusion model의 효율성을 개선하려는 시도가 있다.
- 넓은 mask를 사용하는 경우 ground truth와 굉장히 다른 이미지를 생성한다. 이는 두 이미지가 비슷한 정도를 평가하는 LPIPS에 적합하지 않다. 해결책으로는 FID를 사용하는 것이다. 하지만 FID는 적어도 1000장의 이미지가 필요하므로 대부분의 연구 기관에서 실행할 수 없는 실행 시간을 초래한다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)