






arXiv 2022. [Paper] [Github] [Page]
Songxiang Liu, Dan Su, Dong Yu
Tencent AI Lab
28 Jan 2022
Introduction
Text-to-speech (TTS)는 주어진 텍스트 입력에 대하여 다양한 음성을 출력할 수 있는 multimodal 생성 task이다. 일반적인 TTS는 텍스트를 분석하는 프론트엔트, 음향 모델 (acoustic model), vocoder의 3가지 요소로 구성된다.
텍스트를 분석하는 프론트엔드는 입력 텍스트를 정규화하고 언어적 표현으로 변환한다. 음향 모델은 언어적 표현을 mel spectrogram과 같은 시간-주파수 도메인의 음향 feature로 변환한다. 마지막으로 vocoder가 음향 feature로 시간 도메인의 waveform을 생성한다.
합성 음성의 표현력과 fidelity를 향상시키기 위한 음향 변화 정보 모델링을 위해 다양한 유형의 생성 모델이 음향 모델로 사용되어 왔다.
신경망 기반의 autoregressive (AR) 모델이 TTS로 많이 사용되었으며 프레임별로 음향 feature를 생성하여 굉장히 자연스러운 음성을 생성할 수 있는 가능성을 보여주었다. 그럼에도 불구하고 AR TTS 모델은 단어를 스킵하거나 같은 말을 반복하는 등의 발음 문제가 자주 발생하며, 이는 inference 시의 누적된 예측 오차에 의한 것이다. 또한 순차적으로 생성되기 때문에 합성 속도에 한계가 있다. 이러한 한계점을 해결하기 위해 Flow 기반 모델, VAE 기반 모델, GAN 기반 모델 등 다양한 non-AR TTS 모델이 제안되었다.
또다른 생성 모델의 한 종류는 diffusion model이다. Diffusion model은 이미지 합성과 오디오 합성 등에서 state-of-the-art를 달성했다. 본 논문은 diffusion 모델 기반의 DiffGAN-TTS를 제안하며 fidelity가 높고 효율적인 TTS를 달성하였다고 한다. DiffGAN-TTS는 diffusion model의 강력한 모델링 능력으로 복잡한 일대다 text-to-spectrogram 매핑 문제를 해결하였다.
Denoising diffusion GAN model에서 부분적으로 영감을 받아 실제 denoising 분포와 일치하도록 적대적으로 학습된 표현력 있는 음향 generator로 denoising 분포를 모델링한다. DiffGAN-TTS는 inference에서 크게 denoising step의 수를 줄여 샘플링을 가속화할 수 있다.
학습은 총 2단계로 구성된다. 먼저 기본 음향 모델이 1단계에서 학습되며 강한 사전 정보를 2단계에서 학습되는 denoising model에 제공한다.
DiffGAN-TTS
DDPM이 복잡한 데이터 분포를 모델링하는 능력을 잘 보여주었지만 느린 inference 시간이 실시간 적용을 어렵게 한다. 이는 DDPM의 2가지 가정에 의한 것이다.
- Denoising 분포 $p_\theta (x_{t-1} \vert x_t)$가 가우시안 분포로 모델링되었다.
- $\beta_t$가 작은 것에 비해 denoising step $T$가 충분히 크게 가정된다.
Denoising step이 더 커지고 데이터 분포가 가우시안이 아니라면 실제 denoising 분포는 더 복잡하고 multimodal해지며, 몇몇 경우에는 denoising 분포를 parameterize된 가우시안 분포로 근사하는 것이 충분하지 않다.
다음은 이러한 아이디어를 적용한 효율적이고 fidelity가 높은 multi-speaker TTS에 대한 자세한 내용들이다.
1. Acoustic generator and Discriminator
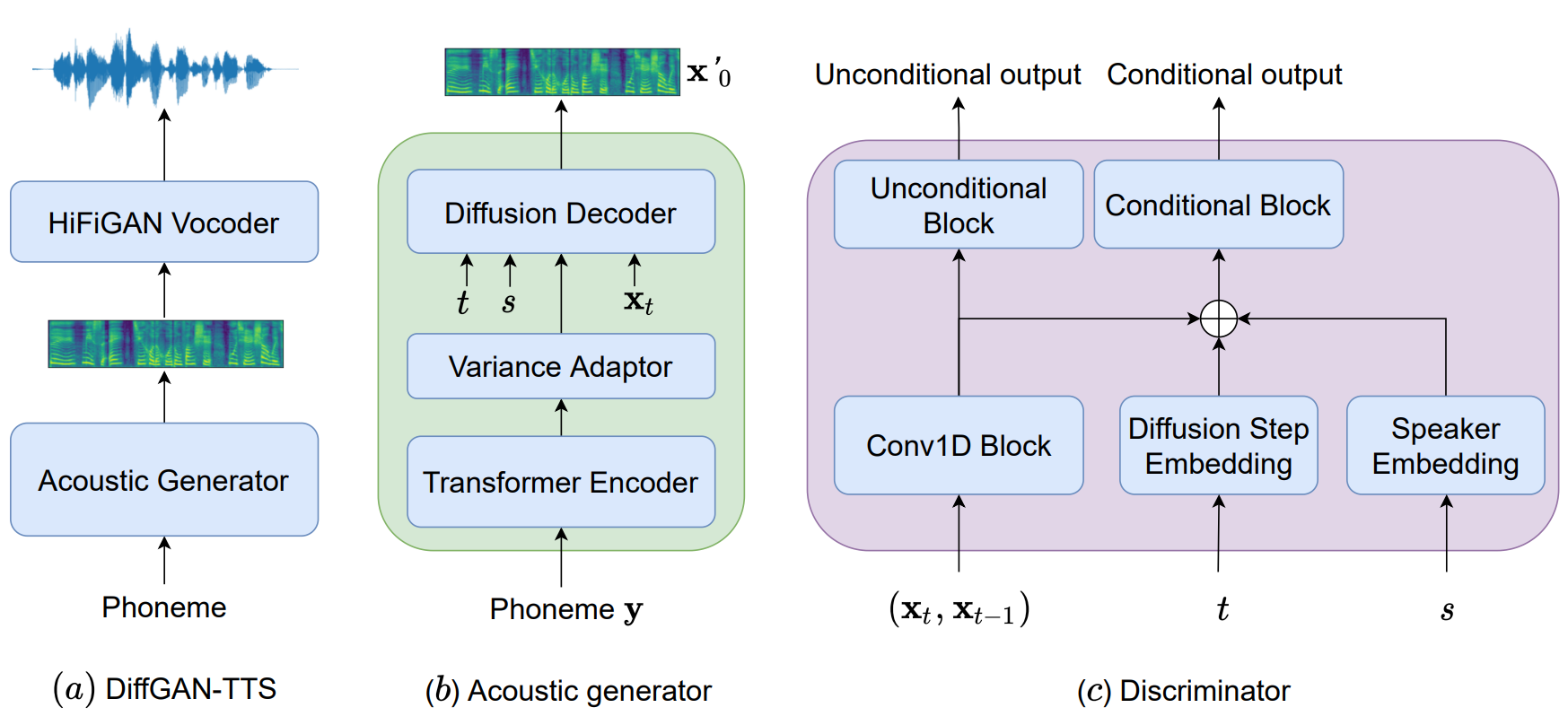
위 그림의 (a)와 같이 DiffGAN-TTS는 음소(phoneme) 시퀀스 $y$를 텍스트 분석 도구를로부터 얻어 multi-speaker acoustic generator의 입력을 준다. Acoustic generator는 mel-spectrogram feature $x_0$를 생성하고 이를 HiFi-GAN 기반의 신경망 vocoder에 입력하여 시간 도메인의 waveform을 생성한다. DDPM은 acoustic generator에 사용되어 음소에서 mel-spectrogram으로의 multimodal한 매핑애서의 무수히 해가 많은 문제(ill-posed problem)을 해결한다.
DiffGAN-TTS의 학습 과정은 다음과 같다.

본 논문의 목표는 denoising step 수 $T$를 줄여 (ex. $T \le 4$) inference 과정을 효율적이고 품질 저하 없이 실시간 음성 합성에 적합하도록 하는 것이다. 저자들은 denoising step이 큰 discrete-time diffusion model에 주목하며 conditional GAN을 사용하여 denoising 분포를 모델링한다.
Conditional GAN 기반의 acoustic generator $p_\theta (x_{t-1} \vert x_t)$를 학습시켜 실제 denoising 분포 $q(x_{t-1} \vert x_t)$를 근사하며, 이 때 각 denoising step에 대한 divergence $D_\textrm{adv}$를 최소화하는 adversarial loss가 사용된다.
\[\begin{equation} \min_\theta \sum_{t \ge 1} \mathbb{E}_{q(x_t)} [D_\textrm{adv} (q(x_{t-1} \vert x_t) \| p_\theta (x_{t-1} \vert x_t))] \end{equation}\]저자들은 오디오 생성에서 좋은 결과를 보인 LS-GAN의 방법을 사용하여 $D_\textrm{adv}$를 최소화시킨다.
모델 구조 그림의 (c)와 같이 discriminator는 diffusion step에 의존하고 말하는 사람을 인식하도록 설계되어 generator의 fidelity 높은 multi-speaker 음성 생성을 돕는다. Speaker-ID를 $s$로 표기할 때, discriminator $D_\phi(x_{t-1}, x_t, t, s)$는 joint conditional and unconditional (JCU)로 모델링되었다. 즉, unconditional logit뿐만 아니라 conditional logit도 출력하며, diffusion step embedding과 speaker embedding이 조건으로 주어진다.
저자들은 denoising diffusion GAN model 논문과 동일한 방법으로 denoising 함수를 implicit denoising model로 parameterize하였다. 특히 $x_t$에서 바로 $x_{t-1}$을 예측하지 않고 다음과 같이 $x_t$에서 예측된 $x_0$를 함께 사용하여 $x_{t-1}$을 예측한다.
\[\begin{equation} p_\theta (x_{t-1} \vert x_t) := q(x_{t-1} \vert x_t, x_0 = f_\theta (x_t, t)) \end{equation}\]Diffusion 함수 $f_\theta$는 $\theta$로 parameterize되었다. 학습 중에는 posterior 분포 \(q(x'_{t-1} \vert x'_0, x_t)\)로 샘플링하며 여기서 \(x'_0\)는 $x_0$를 예측한 것이다. 그런 다음 예측된 tuple \((x'_{t-1}, x_t)\)가 JCU discriminator에 입력으로 주어져 대응되는 실제 tuple (x_{t-1}, x_t)에 대한 $D_\textrm{adv}$이 계산된다.
Denoising diffusion GAN model 논문과는 다르게 latent variable $z \sim \mathcal{N} (0,I)$를 acoustic generator의 입력으로 넣지 않고 variance-adapted 텍스트 인코딩과 speaker-ID를 입력으로 넣는다.
정리하면, implicit 분포 $f_\theta (x_t, t)$는 acoustic generator $G_\theta (x_t, y, t, s)$로 모델링되며, $G_\theta$는 음소 $y$, diffusion step index $t$, speaker-ID $s$를 조건으로 하여 $x_t$로부터 $x_0$를 예측한다.
2. Training loss
Discriminator는 다음 loss를 최소화하도록 학습된다.
\[\begin{equation} \mathcal{L}_D = \sum_{t \ge 1} \mathbb{E}_{q(x_t) q(x_{t-1} \vert x_t)} [(D_\phi (x_{t-1}, x_t, t, s) - 1)^2] + \mathbb{E}_{p_\theta (x_{t-1} \vert x_t)} [D_\phi (x_{t-1}, x_t, t, s)^2] \end{equation}\]Acoustic generator를 학습시키기 위하여 feature space에서 진짜 데이터와 가짜 데이터를 판별하는 feature matching loss \(\mathcal{L}_{fm}\)을 사용한다. \(\mathcal{L}_{fm}\)은 진짜 데이터와 가짜 데이터에 대한 모든 discriminator feature map의 L1 거리를 더하여 계산한다.
\[\begin{equation} \mathcal{L}_{fm} = \mathbb{E}_{q(x_t)} \bigg[\sum_{i=1}^N \| D_\phi^i (x_{t-1}, x_t, t, s) - D_\phi^i (x'_{t-1}, x_t, t, s) \|_1 \bigg] \end{equation}\]여기서 $N$은 discriminator의 hidden layer 개수이다.
추가로 FastSpeech2와 같이 acoustic reconstruction loss를 사용하여 acoustic generator를 학습시킨다.
\[\begin{equation} \mathcal{L}_{recon} = \mathcal{L}_{mel} (x_0, x'_0) + \lambda_d \mathcal{L}_{duration} (d, \hat{d}) + \lambda_p \mathcal{L}_{pitch} (p, \hat{p}) + \lambda_e \mathcal{L}_{energy} (e, \hat{e}) \end{equation}\]여기서 $d$, $p$, $e$는 target duration, pitch, energy이며 $\hat{d}$, $\hat{p}$, $\hat{e}$는 예측된 값이다. $\lambda_d$, $\lambda_p$, $\lambda_e$는 각각에 대한 가중치이며 0.1로 둔다. \(\mathcal{L}_{mel}\)은 MAE loss를 사용하고 나머지는 MSE loss를 사용한다.
전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_G = \mathcal{L}_{adv} + \mathcal{L}_{recon} + \lambda_{fm} \mathcal{L}_{fm} \end{equation}\]여기서 \(\mathcal{L}_{adv}\)는
\[\begin{equation} \mathcal{L}_{adv} = \sum_{t \ge 1} \mathbb{E}_{q(x_t)} \mathbb{E}_{p_\theta (x_{t-1} \vert x_t)} [(D_\phi (x_{t-1}, x_t, t, s) - 1)^2] \end{equation}\]이고, \(\lambda_{fm}\)은 \(\lambda_{fm} = \mathcal{L}_{recon} / \mathcal{L}_{fm}\)으로 동적으로 계산된다.
3. Active shallow diffusion mechanism
기존의 많은 음향 모델이 MAE loss나 MSE loss와 같은 간단한 loss로 학습되었다. 이러한 음향 모델이 생성한 acoustic feature는 데이터에 대한 부정확한 uni-modal 분포 가정 때문에 over-smoothing (지나친 획일화) 문제를 겪으며, 이는 의도한 합성 성능에 도달하지 못하게 한다.
그럼에도 불구하고 간단한 loss가 사용되지 않는 것은 아니다. MSE loss나 MAE loss로 학습된 음향 모델의 출력은 acoustic feature에 대한 강한 사전 지식을 제공할 수 있으며, DDPM에서 추가로 활용하여 정제된 feature를 생성하고 합성 성능을 향상시킬 수 있다.
DiffGAN-TTS의 inference를 가속화하기 위하여 본 논문은 active shallow diffusion mechanism을 제안한다.
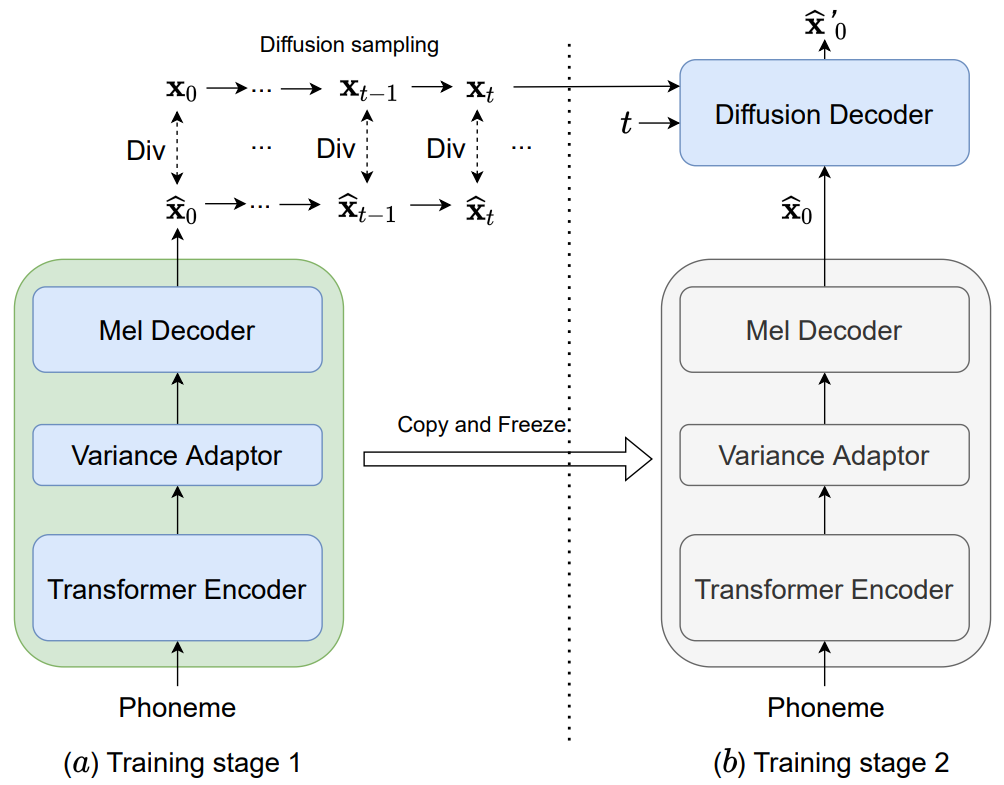
위 그림과 같이 2단계 학습으로 설계되었다. 1단계에서는 기본 음향 모델 $G_\psi^{\textrm{base}} (y, s)$가
로 학습된다. 여기서 $\textrm{Div}()$는 예측 값과 ground-truth 사이의 divergence를 측정하는 거리 함수이고, $q_\textrm{diff}^t$는 $t$에서의 diffusion sampling function이다. 즉, $x_t = q_\textrm{diff}^t (x_0)$이고 $q_\textrm{diff}^0$은 항등 함수이다. 목표 함수는 기본 음향 모델이 ground-truth acoustic feature로부터 diffused sample을 만들도록 한다.
2단계에서는 위 그림과 같이 사전 학습된 기본 음향 모델의 가중치가 DiffGAN-TTS의 acoustic generator의 가중치에 복사된 후 freeze한다. 기본 음향 모델은 coarse한 mel spectrogram $\hat{x}_0$를 생성하고 이는 diffusion decoder에서 조건으로 주어진다. 위 식의 divergence는 다음과 같이 근사된다.
\[\begin{aligned} \textrm{Div} &= D_\textrm{adv} (q(x_{t-1} \vert x_t) \| p_\theta (x_{t-1} \vert x_t)) \\ & \approx D_\textrm{adv} (q(x_{t-1} \vert x_t) \| p_\theta (x_{t-1} \vert x_t, \hat{x}_0)) \end{aligned}\]경험적으로 diffusion decoder는 기본 음향 모델의 coarse한 예측에 super-resolution을 수행하는 post filter로 생각할 수 있다. 본 논문은 denoising step의 수를 1로 줄이는 것에 주목한다. Inference 시에 기본 음향 모델은 먼저 coarse한 mel spectrogram $\hat{x}_0$를 생성한 후 diffusion step 1에서 diffused sample $\hat{x}_1$이 계산된다. 그런 다음 DiffGAN-TTS는 $\hat{x}_1$를 prior로 하여 denoising step 하나를 진행하여 최종 출력을 얻는다. 이러한 변형 모델을 “DiffGAN-TTS (two-stage)”로 표기한다.
4. Model architecture

- Transformer encoder: FastSpeech2와 같이 4개의 FFT로 구성된 아키텍처
- hidden size: 256
- attention head 개수: 2
- kernel size: 9
- filter size: 1024
- Variance adaptor: FastSpeech2와 같은 구조와 hyper-parameter 사용
- pitch predictor와 energy predictor는 각각 음소 level의 기본 주파수(F0) contour와 에너지 countour을 출력
- hidden-Markov-model (HMM) 기반의 forced aligner 에서 얻은 음소-오디오 정렬 정보에 따라 프레임 level의 F0과 에너지 값을 평균하여 label을 얻음
- Diffusion decoder: non-causal WaveNet 아키텍처를 약간 수정하여 사용
- waveform이 아닌 mel spectrogram을 다루기 때문에 dilation rate = 1
- WaveNet residual blocks의 수 $N$ = 20, hidden dimension = 256
- JCU discriminator: CNN으로 구성
- Conv1D block: 3개의 1D conv layer + LeakyReLU (기울기 0.2)
(채널 = 64, 128, 256 / kernel size = 3, 5, 5 / stride = 1, 2, 2) - diffusion step embedding은 diffusion decoder와 동일
- unconditional block과 conditional block은 동일한 구조, 2개의 1D conv layer로 구성
(채널 = 128, 1 / kernel size = 5, 3 / stride = 1, 1)
- Conv1D block: 3개의 1D conv layer + LeakyReLU (기울기 0.2)
Experiments
1. Data and Preprocessing
- 성별이 균등한 내부 corpus 데이터셋, 228명의 중국어 음성, 총 200시간
- 랜덤하게 1024개의 발화를 validation, 1024개의 발화를 testing을 위해 사용
- 24kHz, 16-bit quantization
- Mel spectrogram: 80개의 주파수 bin, STFT 사용 (1024 window size, 10ms frame-shift)
- PyWorld toolkit으로 F0 값 계산
- STFT 크기에서 주파수 bin의 L2-norm을 계산하여 에너지 feature로 사용
2. Training
- $T = 1, 2, 4$에 대하여 Adam optimizer로 학습 ($G$, $D$ 모두 $\beta_1 = 0.5, \beta_2 = 0.9$)
- Variance schedule: \(\begin{equation} \beta_t = 1 - \exp(- \frac{\beta_\textrm{min}}{T} - 0.5 (\beta_\textrm{max} - \beta_\textrm{min}) \frac{2t - 1}{T^2}), \quad (\beta_\textrm{min} = 0.1, \beta_\textrm{max} = 40) \end{equation}\)
- exponential learning rate decay = 0.999 ($G$, $D$ 모두)
- 초기 learning rate: $G$는 $10^{-4}$, $D$는 $2 \times 10^{-4}$
- NVIDIA V100 GPU 1개로 학습
- batch size 64, 300k step
- two-stage 학습의 경우 기본 음향 모델은 200k step, Adam optimizer ($\beta_1 = 0.9, \beta_2 = 0.98$)
Attention is all you need 논문과 동일한 learning rate schedule 사용
거리 함수로 간단한 MAE loss 사용
Results
다음은 DiffGAN-TTS와 ground truth, 다른 TTS 모델을 비교한 결과이다.

1. Objective Evaluation
객관적 평가 지표로는 SSIM (structural similarity index measure), MCD (mel-cepstral distortion), $F_0$ RMSE (root mean squared error), voice cosine similarity가 사용되었다.
MCD와 $F_0$ 계산 시 생성된 음성과 ground-truth 음성을 정렬하기 위하여 dynamic time warping (DTW)가 사용되었다. Mel-cepstral 계산에는 처음 24개의 계수가 사용되었다. Cosine similarity 측정은 사전 학습된 speaker classifier로 추출한 임베딩 벡터를 대상으로 진행되었다.
2. Subjective Evaluation
주관적 평가 지표로는 MOS (mean opinion score)가 사용되었으며, 각 오디오 샘플은 최소 20명의 테스터에게 1부터 5점까지 0.5점 간격으로 평가받았다.
다음은 step 1에서의 diffused sample을 비교한 것이다.
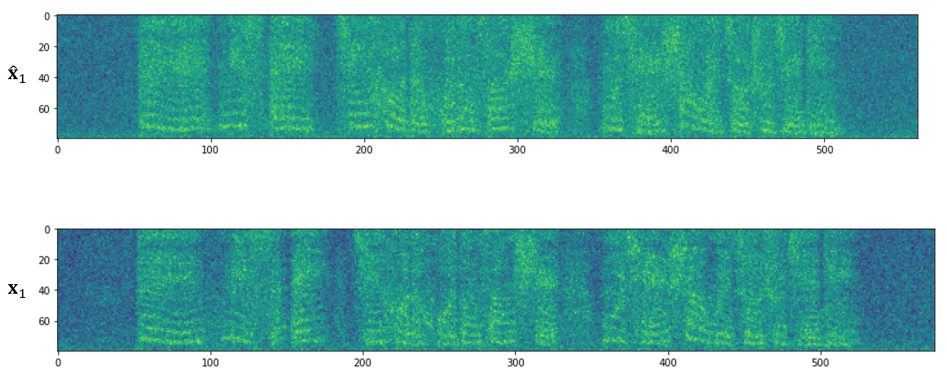
$\hat{x}_1$은 예측된 mel spectrogram에서 샘플링한 것이고 $x_1$은 ground truth에서 샘플링한 것이다. 두 샘플의 구조가 비슷한 것을 알 수 있으며, 이는 $\hat{x}_1$을 강한 prior로 사용할 수 있음을 의미한다.
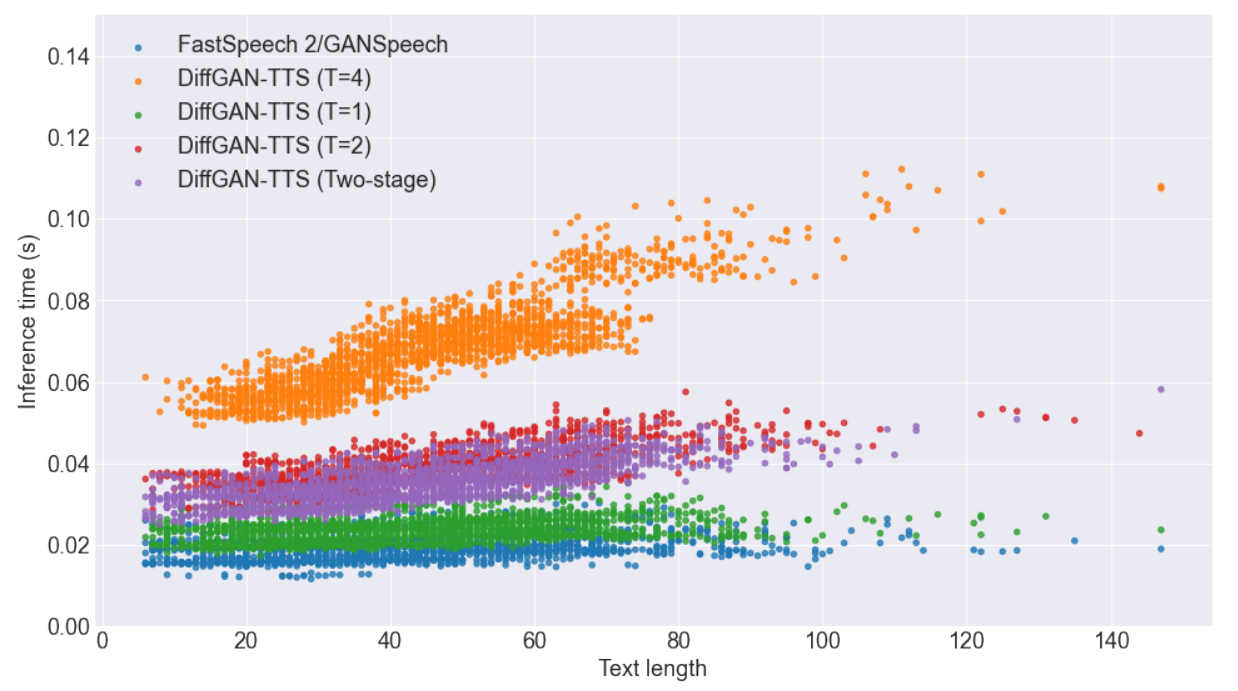
3. Synthesis Speed
RTF (Real-Time factor)는 NVIDIA T4 GPU를 사용하여 측정하였으며, 1초의 오디오를 생성하는 데 몇 초가 걸리는 지를 나타낸다.
다음은 텍스트 길이에 대한 inference 시간에 대한 그래프이다.
4. Ablation studies
다음은 DiffGAN-TTS ($T = 4$) 모델에 대한 ablation studies를 수행한 결과이다.

Latent variable $z$를 diffusion decoder에 추가한 모델은 다음과 같다.

StyleGAN과 비슷하게 $z \sim \mathcal{N}(0,I)$을 mapping network로 매핑한 후 FC layer로 $\gamma$와 $\beta$를 계산하여 AdaIN 연산에 사용하는 방식이다.
Latent variable을 추가하는 것이 오히려 성능을 하락시켰으며, 이는 variance adaptor와 speaker conditioning이 음향의 변화를 조절하고 있음을 의미한다.
5. Synthesis Variation
FastSpeech2와 GANSpeech와는 다르게 DiffGAN-TTS의 출력은 입력 텍스트와 speaker conditioning에 따라 달라진다.
다음은 DiffGAN-TTS ($T = 4$) 모델에서 얻은 샘플들을 $F_0$ contour에 나타낸 것이다.
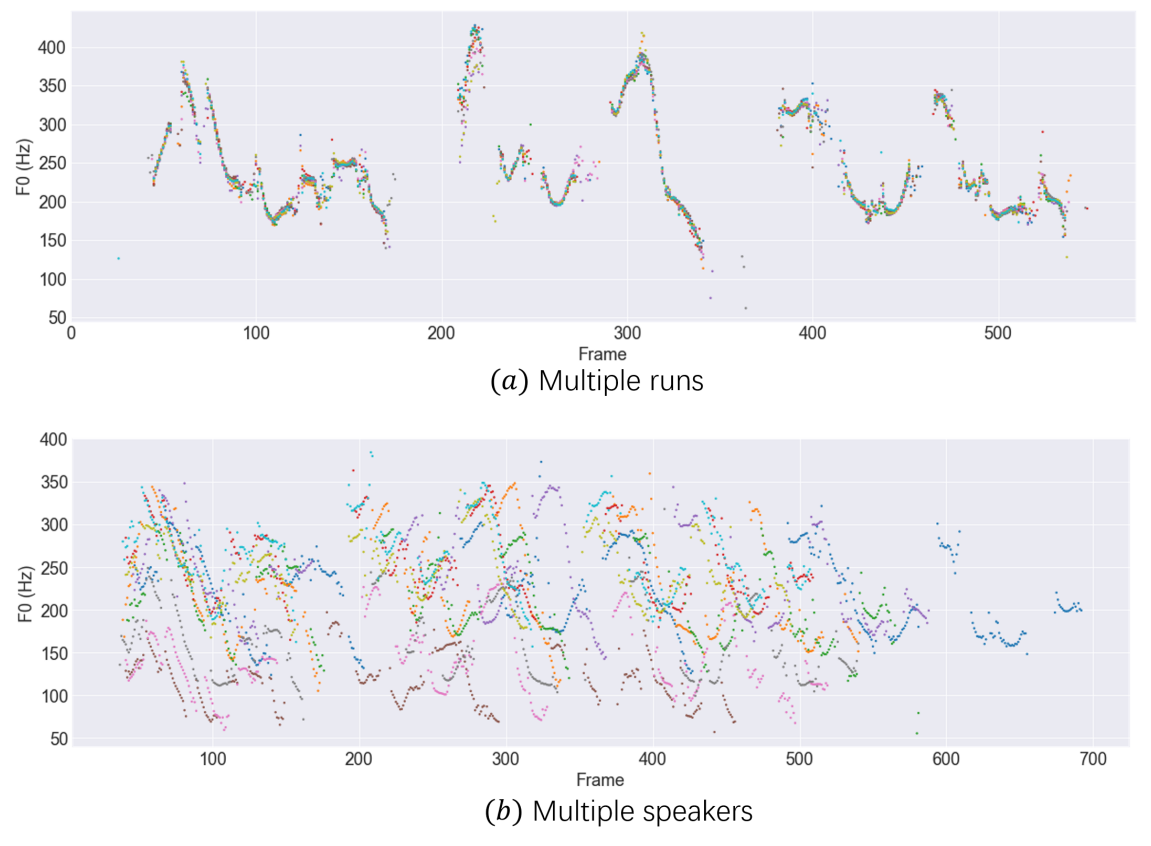
위는 특정 입력 텍스트와 화자에 대하여 10번 실행한 결과이며 다양한 pitch의 음성이 생성되었다. 아래는 서로 다른 10명의 화자에 대하여 실행한 결과이며 각 화자마다 서로 굉장히 다른 운율이 나타났다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)