






IEEE 2021. [Paper] [Github] [Demo Page]
Songxiang Liu, Yuewen Cao, Dan Su, Helen Meng
Human-Computer Communications Laboratory, The Chinese University of Hong Kong | Tencent AI Lab
28 May 2021
Introduction
Singing voice conversion (SVC)은 content와 멜로디를 그대로 두고 노래의 목소리만 다른 가수의 목소리로 바꾸는 기술이다. 최근의 SVC 모델은 content encoder를 학습시켜 source로부터 content feature를 추출하고 conversion model을 학습시켜 content feature를 다른 feature로 교체한다. 오토인코더처럼 content encoder와 conversion model을 연결하여 학습시키는 경우도 있고 각각 학습시키는 경우도 있다.
각각 학습시키는 경우 자동 음성 인식 모델 (automatic speech recognition, ASR)을 content encoder로 학습시킨다. ASR 모델은 end-to-end 모델이거나 hybrid HMM-DNN model이다.
Conversion model은 GAN이나 regression model을 사용한다. Conversion model로 GAN이 사용되는 경우 content feature로부터 waveform(파형)을 바로 생성하고, regression model이 사용되는 경우 content feature를 mel spectrogram과 같은 spectral feature로 변환한 후 추가로 학습시킨 vocoder로 waveform을 생성한다. 본 논문은 후자의 경우를 사용하며 대신 diffusion model을 conversion model로 사용한다.
Diffusion model은 이미 이미지 생성과 오디오 waveform 생성에서 state-of-the-art를 달성하였다. Diffusion model에는 forward process와 reverse process가 있다. Forward process는 고정된 파라미터의 Markov chain이며, 복잡한 데이터에 점진적으로 약간의 Gaussian nosie를 더하여 완전한 가우시안 분포로 만드는 과정이다. Reverse process도 Markov chain이며, Gaussian noise에서 시작하여 데이터를 복구하는 과정이다.
DiffSVC는 diffusion model에 기반한 SVC 시스템이다. 본 논문은 ASR acousic model로 노래에서 phonetic posteriorgram (PPG)를 추출한다. Diffusion model은 content, 멜로디, loudness(소리 크기)의 feature를 조건으로 받아 Gaussian noise로부터 mel spectrogram을 점진적으로 복구한다.
DiffSVC는 기존의 state-of-the-art SVC보다 목소리의 자연스러움과 유사성에서 우수한 conversion 성능을 보인다. 본 논문은 다음의 2가지의 기여가 있다.
- Diffusion probabilistic model을 사용한 첫 SVC 시스템이며, diffusion model이 SVC task에 효과적으로 적용할 수 있음을 보였다.
- 목소리의 자연스러움과 유사성에서 이전 SVC 시스템보다 우수한 conversion 성능을 보인다.
Diffusion Probabilistic Model
(자세한 내용은 DDPM Paper review 참고)
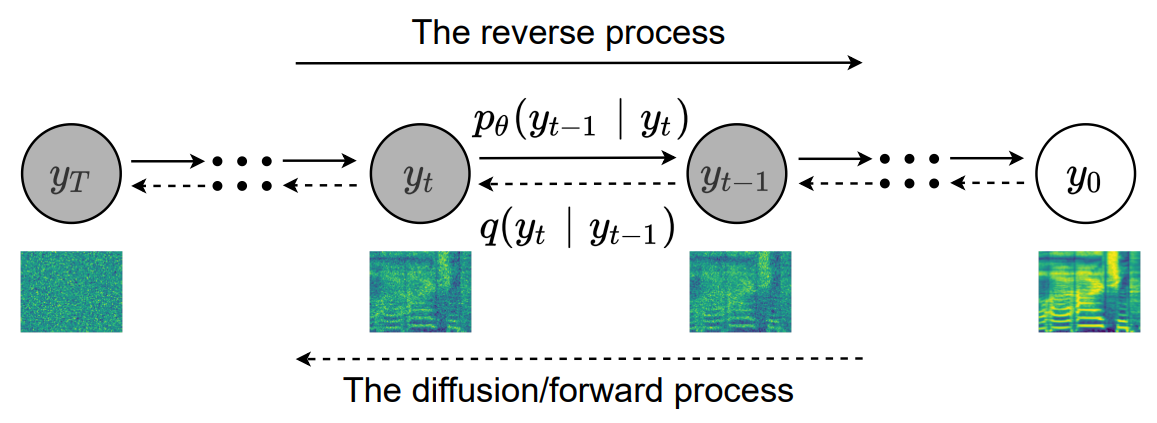
본 논문에서 사용한 diffusion model은 DDPM과 거의 동일하며, 모델의 아키텍처만 SVC를 위하여 수정되었다.
Noise는 timestep에 따라 $\beta_1, \cdots, \beta_T$로 고정되며 $\beta_1 < \beta_2 < \cdots < \beta_T$이다. DDPM 논문에서 데이터를 $x$라고 표기한 것과 달리 본 논문에서는 PPG를 $x$로 표기하기 때문에 mel spectrogram을 $y$로 표기한다. 따라서 forward process는
\[\begin{equation} q(y_{1:T} | y_0) := \sum_{t=1}^T q(y_t | y_{t-1}), \quad \quad q(y_t | y_{t-1}) := \mathcal{N} (y_t; \sqrt{1-\beta_t} y_{t-1}, \beta_t I) \end{equation}\]이다. 따라서 $y_0$에서 임의의 timestep $t$의 $y_t$는 다음과 같이 구할 수 있다.
\[\begin{equation} q(y_t | y_0) = \mathcal{N} (y_t; \sqrt{\vphantom{1} \bar{\alpha}_t} y_0, (1-\bar{\alpha}_t) I), \quad \quad \textrm{where} \quad \alpha_t := 1- \beta_t, \; \bar{\alpha}_t = \prod_{s=1}^t \alpha_s \end{equation}\]Reverse process는 $p(y_T) = \mathcal{N}(y_T; 0,I)$에서 시작하며
\[\begin{equation} p_\theta (y_{0:T}) := p(y_T) \sum_{t=1}^T p_\theta (y_{t-1} | y_t), \quad \quad p_\theta(y_{t-1} | y_t) := \mathcal{N} (y_{t-1}; \mu_\theta, \sigma_\theta^2 I) \end{equation}\]이다. $\mu_\theta$는 noise $\epsilon$에 대응되는 $\epsilon_\theta$로 parameterize되며, $\epsilon_\theta$는 $y_t$, timestep $t$, PPG $x$, Log-F0 $f_0$, loudness $l$을 입력으로 받는다.
학습 과정도 DDPM과 동일하다. 학습 시에는 $q(y_t \vert y_0)$ 식을 이용하여 $\epsilon_\theta$에
\[\begin{equation} y_t = \sqrt{\vphantom{1} \bar{\alpha}_t} y_0 + \sqrt{1-\bar{\alpha}_t}\epsilon \end{equation}\]를 입력으로 주어 추가된 noise를 예측한다. 따라서 학습은 다음 loss를 최소화하는 방향으로 진행된다.
\[\begin{equation} \mathbb{E}_{y_0, t} (\| \epsilon - \epsilon_\theta(\sqrt{\vphantom{1} \bar{\alpha}_t} y_0 + \sqrt{1-\bar{\alpha}_t}\epsilon, t, x, f_0, l)\|_2^2) \end{equation}\]샘플링도 DDPM과 동일하다. $y_T \sim \mathcal{N} (0,I)$에서 시작하여 $t=T$부터 $t=1$까지 reverse transition $p_\theta (y_{t-1} \vert y_t)$ 으로 한 step씩 샘플링하여 최종 이미지 $y_0$가 샘플링된다.
\[\begin{equation} y_{t-1} = \frac{1}{\sqrt{\alpha}_t} (y_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon_\theta (y_t, t, x, f_0, l)) + \sigma_t z, \quad \quad \sigma_t^2 = \frac{1 -\bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \beta_t \end{equation}\]$t > 1$일 때 $z \sim \mathcal{N} (0, I)$이고 $t = 1$일 때 $z = 0$이다.
전체 학습 알고리즘과 샘플링 알고리즘은 다음과 같다.


DiffSVC
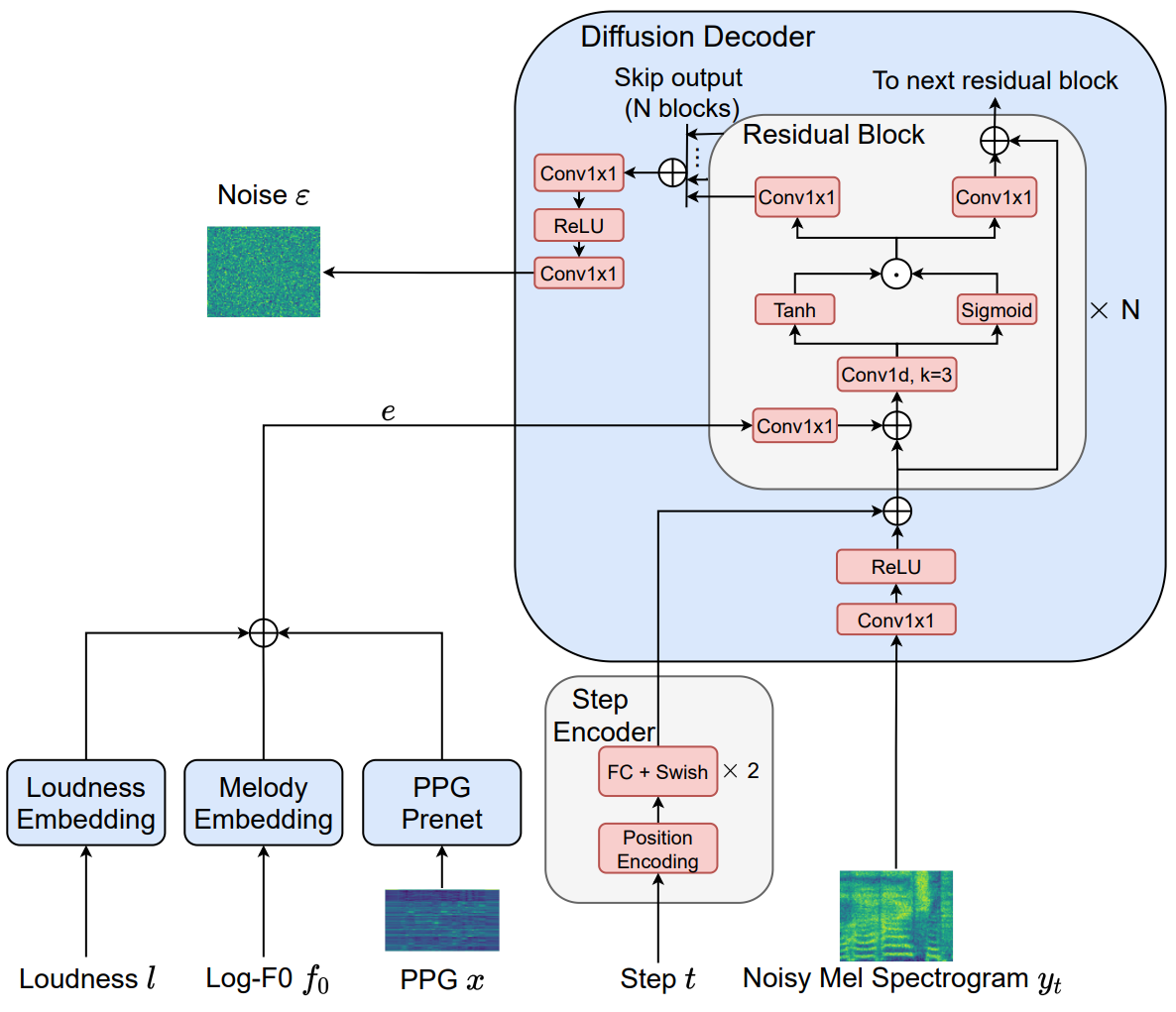
1. PPG, Log-F0 and Loudness
저자들은 content, 멜로디, loudness를 SVC task의 중요한 요소로 보았다. 먼저 Content feature로 PPG $x$를 추출하기 위하여 Deep-FSMN (DFSMN)-based ASR acousic model을 학습시켰다. ASR model은 cross-entropy loss로 학습되었으며, 중국어 SVC를 위한 음소(phonemes)를 ground truth label로 사용하였다.
ASR로 추출한 PPG $x$는 FC layer로 이루어진 PPG prenet에 입력된다. 멜로디는 로그 스케일의 기본 주파수 contour (Log-F0)로 표현된다. Loudness feature은 파워 스펙트럼의 A-weighting 메커니즘으로 계산된다.
Log-F0 feature $f_0$와 loudness feature $l$은 같은 방식으로 처리된다. 먼저 256개의 bin으로 양자화한 후 각각 melody embedding lookup table과 loudness embedding lookup table을 통과시킨다.
PPG prenet을 통과한 PPG $x$와 embedding lookup table을 각각 통과한 Log-F0 $f_0$와 loudness $l$는 elementwise하게 더해져 conditioner $e$가 된다. $e$는 diffusion decoder의 추가 입력으로 주어지는 token으로 사용된다.
2. Diffusion Modeling
Step Encoding
Timestep $t$는 다음과 같은 sinusoidal position encoding으로 128차원 벡터 $t_{emb}$로 변환된다.
\[\begin{equation} t_{emb} (t) = [\sin (10^{\frac{0 \times 4}{63}} t), \cdots, \sin (10^{\frac{63 \times 4}{63}} t), \cos (10^{\frac{0 \times 4}{63}} t), \cdots, \cos (10^{\frac{63 \times 4}{63}} t)] \end{equation}\]그런 다음 $t_{emb}$를 2개의 FC layer와 Swish 활성화 함수로 처리한다.
Diffusion decoder
Wavenet의 bidirectional residual convolutional architecture를 약간 수정하여 diffusion decoder로 사용한다. Waveform 대신 mel spectrogram을 입력을 받기 때문에 dilation rate를 1로 사용했으며, 1을 사용해도 receptive field가 충분하다고 한다.
먼저 mel spectrogram을 Conv1x1 layer와 ReLU에 통과시킨다. 그런 다음 step encoder의 output을 더하고 $N$개의 residual block에 입력으로 넣는다. Conditioner $e$는 각 residual block의 Conv1x1 layer에 입력으로 넣어준 후 그 output을 mel spectrogram feature와 step encoder feature를 더한 값에 더해준다.
그런 다음 feature map에 Wavenet 논문에서 소개된 gated mechanism를 적용한다. 그 결과로 각 residual block은 skip output 1개와 다음 residual block에 입력으로 사용할 output 1개가 나온다. $N$개의 skip output을 모두 더한 다음 Conv1x1 layer, ReLU, Conv1x1 layer를 순서대로 통과시키면 noise가 예측된다.
Experiments
1. Dataset and preprocessing
PPG extractor는 중국어 ASR corpus (내부 데이터셋)로 학습되며, 이 corpus는 수천 명이 녹음한 약 2만 시간 분량의 음성 데이터로 이루어져 있다. PPG features는 218차원이다.
Conversion model은 여성 성우가 녹음한 14시간의 노래로 이루어진 내부 데이터셋을 사용했다. 오디오 포맷은 sample rate가 24kHz인 16비트 PCM이다.
Mel spectrogram은 80개의 주파수 bin으로 구성되며 FFT size는 1024, window size는 1024, hop size는 240 (즉, 10ms)로 계산된다. 또한, [-1, 1] 범위로 min-max normalize되었다. Fundamental frequency (F0) 값은 hop size 240으로 계산된다. F0 계산을 견고하게 하기 위하여 3개의 F0 estimator (DIO, REAPER, SPTK)의 평균을 사용한다. Loudness feature 계산을 위한 FFT size는 2048, window size는 2048, hop size는 240이다.
2. Implementation details
- PPG prenet의 출력 크기, 멜로디 임베딩 크기, loudness 임베딩 크기는 모두 256
- Log-F0와 loudness를 양자화하기 위해 256개의 bin을 사용
- Step encoder는 Diffwave 논문과 같은 hyper-parameter를 사용
- Residual layer 개수 $N = 20$, convolution 채널 수는 256
- 전체 timestep $T = 100$. $\beta$는 0.0001에서 0.06까지 선형 간격
- ADAM optimizer (lr = 0.0002)
Mel spectrogram $y_0$를 waveform으로 변환시킬 vocoder로 Hifi-GAN을 학습시킨다. 공식 implementation의 설정을 약간 수정하여 사용하였다. Sample rate가 24kHz이고 mel spectrogram의 hop size가 240이므로 upsample rate를 $240 = 8 \times 5 \times 3 \times 2$로 인수분해하여 사용하였다. ConvTranspose1d upsampling layer의 사용으로 발생하는 checkerboard artifact를 피하기 위해 temporal nearest interpolation layer와 1D convolutional layer를 순서대로 사용하여 upsampling 하였다. 사용한 커널의 크기는 15, 15, 5, 5이다.
3. Evaluations
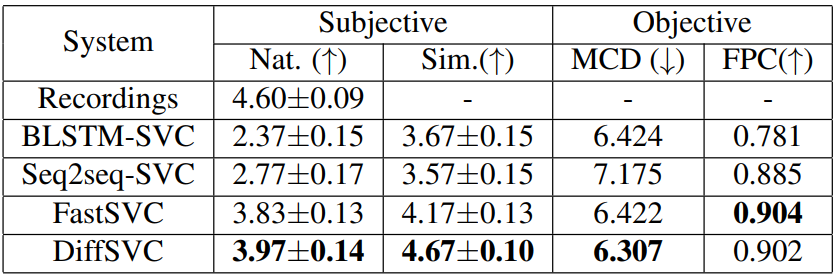
MOS(mean opinion score)는 5점 리커트 척도로 사람이 평가하는 주관적 지표이다. 합성된 노래의 자연스러움과 대상 목소리와의 유사성을 평가하였다. 객관적 지표로는 mel-cepstrum distortion (MCD)와 F0 Pearson correlation (FPC)를 사용하였다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)