






arXiv 2021. [Paper] [Github]
Zhicong Tang, Shuyang Gu, Jianmin Bao, Dong Chen, Fang Wen
Microsoft Research
31 May 2022
Introduction
이 논문은 VQ-Diffusion(Paper review)의 샘플 품질을 개선하는 것을 목표로 한다. VQ-Diffusion의 가장 큰 장점은 각 discrete 토큰의 확률을 추정할 수 있다는 것이고, 이를 통해 고품질의 이미지를 상대적으로 적은 inference step으로 생성할 수 있다는 것이다. 이를 기반으로 저자들은 VQ-Diffusion 개선하기 위한 다음의 2가지 방법을 제안하였다.
1. Discrete classifier-free guidance
조건부 이미지 생성에서 조건 정보가 $y$이고 생성된 이미지가 $x$라고 가정하자. Diffusion 생성 모델은 사전 확률(prior) $p(x \vert y)$를 최대화하려고 시도하고 생성된 이미지 $x$가 사후 확률(posterior) $p(y \vert x)$의 제약 조건(constraint)을 충족한다고 가정한다. 그러나 저자들은 이 가정이 실패할 수 있고 대부분의 경우 사후 확률을 무시할 수 있음을 발견했다. 이것을 posterior issue라고 부른다. 이 문제를 해결하기 위해 저자들은 사전 확률과 사후 확률을 동시에 고려할 것을 제안한다. Posterior constraint에 의해 생성된 이미지는 품질과 입력 조건과의 일관성이 크게 향상된다. 이 접근법은 이전 연구의 classifier-free 기술의 정신을 공유한다. 그러나 모델이 noise 대신 확률을 추정하기 때문에 이 방법은 더 정확하게 공식화된다. 게다가 입력 조건을 0으로 설정하는 대신 학습 가능한 파라미터를 조건으로 사용하여 $p(x)$를 근사화하는 classifier-free guidance보다 일반적이고 효과적인 구현이 가능하다.
2. High-quality inference strategy
각 denoising step에서 일반적으로 여러 토큰을 동시에 샘플링하고 각 토큰은 예상 확률로 독립적으로 샘플링한다. 그러나 서로 다른 위치가 연관되는 경우가 많으므로 독립적으로 샘플링하면 연관성을 무시할 수 있다.
AA와 BB라는 두 개의 샘플만 있는 간단한 데이터 세트를 가정하자. 각 샘플은 나타날 확률이 50%이다. 그러나 각 위치의 추정 확률에 따라 독립적으로 샘플링하면 잘못된 출력(AB, BA)이 학습 중에는 나타나지 않더라도 샘플링 단계에서 나타난다. 이것을 joint distribution issue라고 부른다. 이 문제를 완화하기 위해 고품질 inference 전략을 도입하며, 두 가지 핵심 디자인을 기반으로 한다.
- 샘플링된 토큰이 많을수록 joint distribution issue가 더 심해지기 때문에 각 단계에서 샘플링된 토큰의 수를 줄인다.
- Confidence가 높은 토큰이 더 정확한 경향이 있으므로 confidence가 높은 토큰을 샘플링하기 위해 purity prior를 도입한다.
Background: VQ-Diffusion
(자세한 내용은 Paper review 참고)
VQ-Diffusion은 이미지 $x$를 discrete 토큰 \(x_0 \in \{1, 2, \cdots, K, K+1\}\)으로 변환하는 VQVAE로 시작한다. 여기서 $K$는 코드북의 크기이고 $K+1$은 [MASK] 토큰을 의미한다. Forward process $q(x_t \vert x_{t-1})$는 각 step에서 noise를 추가하는 Markov chain이다. Reverse denoising process는 noise 상태에서부터 샘플을 복원한다. Forward process는 다음과 같다.
\[\begin{equation} q(x_t \vert x_{t-1}) = v^\top (x_t) Q_t v(x_{t-1}) \end{equation}\]$v(x)$는 index $x$만 1인 one-hot 열벡터이고, $Q_t$는 $x_{t-1}$에서 $x_t$로의 probability transition matrix이다.
\[\begin{equation} Q_t = \begin{bmatrix} \alpha_t + \beta_t & \beta_t & \beta_t & \cdots & 0 \\ \beta_t & \alpha_t + \beta_t & \beta_t & \cdots & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \gamma_t & \gamma_t & \gamma_t & \cdots & 1 \end{bmatrix} \end{equation}\]$\alpha_t \in [0,1]$이고 $\beta_t = (1-\alpha_t) / K$이다. $\gamma_t$는 토큰이 [MASK] 토큰으로 교체될 확률이다.
Reverse process는 다음의 사후 확률 분포로 주어진다.
\[\begin{equation} q(x_{t-1} | x_t, x_0) = \frac{(v^\top (x_t) Q_t v(x_{t-1})) (v^\top (x_{t-1}) \overline{Q}_{t-1} v(x_0))}{v^\top (x_t) \overline{Q}_t v(x_0)} \end{equation}\]$\overline{Q}_t = Q_t \cdots Q_1$이다. 누적 transition matrix $\overline{Q}_t$와 확률 $q(x_t \vert x_0)$는 다음과 같이 closed form으로 계산된다.
\[\begin{equation} \overline{Q}_t v(x_0) = \overline{\alpha}_t v(x_0) + (\overline{\gamma}_t - \overline{\beta}_t) v(K+1) + \overline{\beta}_t \\ (\overline{\alpha}_t = \prod_{i=1}^t \alpha_i, \overline{\gamma}_t = 1- \prod_{i=1}^t (1 - \gamma_i), \overline{\beta}_t = \frac{1 - \overline{\alpha}_t - \overline{\gamma}_t}{K}) \end{equation}\]$\overline{\alpha}_t$, $\overline{\gamma}_t$, $\overline{\beta}_t$는 사전에 계산하여 저장해둘 수 있다.
Inference를 할 때 denoising network $p_\theta$는 고정된 Markov chain을 통해 손상된 입력을 점진적으로 복구한다. 또한 학습을 안정적으로 유지하고 빠른 inference가 가능하도록 denoising network가 각 step에서 denoising 토큰 분포 $p_\theta (\tilde{x}_0 \vert x_t)$를 예측하는 reparameterization trick을 사용한다. 따라서 다음과 같이 reverse transition distribution을 계산할 수 있다.
\[\begin{equation} p_\theta (x_{t-1} | x_t, y) = \sum_{\tilde{x}_0 = 1}^K q(x_{t-1} | x_t, \tilde{x}_0) p_\theta (\tilde{x}_0 | x_t, y) \end{equation}\]VQ-Diffusion은 다음 두 가지 문제를 겪을 수 있다.
- 조건부 이미지 생성의 경우 조건 정보 $y$가 denoising network $p_\theta (x_{t−1} \vert x_t, y)$에 직접 주입된다. 그런 다음 네트워크는 $x_{x=1}$을 복구하기 위해 $x_t$와 $y$를 모두 사용하기를 원한다. 그러나 네트워크는 $x_t$에 이미 충분한 정보가 포함되어 있으므로 $y$를 무시할 수 있다. 따라서 생성된 이미지는 입력 $y$와 잘 연관되지 않아 posterior issue가 발생할 수 있다.
- $t$번째 timestep에서 $x_{t-1}$의 각 위치는 $p_\theta (x_{t-1} \vert x_t)$에서 독립적으로 샘플링된다. 따라서 서로 다른 위치 간의 대응 관계를 모델링할 수 없다. 따라서 서로 독립적인 분포에서 샘플링하는 것이 합당하지 않아 joint distribution issue가 발생할 수 있다.
Methods
1. Discrete Classifier-free Guidance
text-to-image 합성과 같은 조건부 이미지 생성 task의 경우 생성된 이미지가 조건 입력과 일치해야 한다. VQ-Diffusion은 단순히 조건 정보를 denoising network에 주입하고 네트워크가 손상된 입력과 텍스트를 모두 사용하여 원본 이미지를 복구한다고 가정한다. 그러나 손상된 입력에는 일반적으로 텍스트보다 훨씬 많은 정보가 포함되어 있으므로 네트워크는 훈련 단계에서 텍스트를 무시할 수 있다. 따라서 VQ-Diffusion은 CLIP 점수를 계산했을 때 입력 텍스트와의 상관관계가 낮은 이미지를 쉽게 생성할 수 있다는 것을 알 수 있다.
Diffusion model은 $p(x \vert y)$를 최대화하기 위해 $x$를 찾는 것을 목표로 한다. CLIP 점수가 높으려면 $p(y \vert x)$가 최대한 커야 한다. 따라서 간단한 해결책은 $\log p(x \vert y) + s \log p(y \vert x)$를 최적화하는 것입니다. 여기서 $s$는 posterior constraint의 정도를 제어하는 hyper-parameter이다. 베이즈 정리를 사용하여 다음과 같이 이 최적화 목표를 도출할 수 있다.
\[\begin{aligned} & \underset{x}{\arg \max} [\log p(x|y) + s \log p(y|x)] \\ =& \underset{x}{\arg \max} [(s+1) \log p(x|y) - s \log \frac{p(x|y)}{p(y|x)}] \\ =& \underset{x}{\arg \max} [(s+1) \log p(x|y) - s \log \frac{p(x|y)p(y)}{p(y|x)}] \\ =& \underset{x}{\arg \max} [(s+1) \log p(x|y) - s \log p(x)] \\ =& \underset{x}{\arg \max} [\log p(x) + (s+1) (\log p(x|y) - \log p(x))] \\ \end{aligned}\]Unconditional image logits $p(x)$를 예측하기 위한 직접적인 방법은 특정 비율의 empty condition 입력으로 모델을 fine-tune하는 것이다. 이는 입력 조건을 “null” 텍스트로 설정하여 모델을 fine-tune하는 GLIDE와 비슷하다. 그러나 “null”의 텍스트 임베딩 대신 학습 가능한 벡터를 사용하면 p(x)의 logit에 더 잘 맞을 수 있다. Inference 단계에서 먼저 conditional image logits $p_\theta (x_{t−1} \vert x_t, y)$를 생성한 다음 조건부 입력을 학습 가능한 벡터로 설정하여 unconditional image logits $p_\theta (x_{t−1} \vert x_t)$를 예측한다. 다음 denoising step은 다음 식으로 샘플링된다.
\[\begin{equation} \log p_\theta (x_{t-1} | x_t, y) = \log p_\theta (x_{t-1} | x_t) + (s+1) (\log p_\theta (x_{t-1} | x_t, y) - \log p_\theta (x_{t-1} | x_t)) \end{equation}\]연속 도메인에서의 classifier-free 샘플링과 비교할 때 discrete 도메인의 posterior constraint에는 세 가지 주요 차이점이 있다.
- VQ-Diffusion은 reparameterization trick을 사용하여 noise가 없는 상태에서 $p(x \vert y)$를 예측하므로 noise가 없는 상태에 최적화 목표 식을 적용할 수 있고, 이로 인해 다른 inference 전략과 호환된다.
- 연속 도메인에서의 diffusion model은 확률 $p(x \vert y)$를 직접 예측하지 않고 gradient를 사용하여 근사한다. 그러나 discrete diffusion model은 확률 분포를 직접 추정한다.
- 연속 모델은 조건을 null 벡터로 설정하여 $p(x)$를 예측하지만, null 벡터 대신 학습 가능한 벡터를 사용하면 성능이 더욱 향상될 수 있다.
2. High-quality Inference Strategy
VQ-Diffusion의 또 다른 중요한 문제는 서로 다른 위치의 토큰을 독립적으로 샘플링하여 발생하는 joint distribution issue이다. 이 문제는 서로 다른 위치 간의 상관 관계를 무시할 수 있다. 저자들은 이 문제를 완화하기 위해 두 가지 key technique을 포함하는 고품질 inference 전략을 제안한다.
Fewer tokens sampling
첫번째 technique은 각 step에서 더 적은 수의 토큰을 샘플링하는 것이다. 이 방식으로 반복적인 denoising process를 통해 서로 다른 위치 간의 상관 관계를 모델링한다. 구체적으로 VQ-Diffusion의 각 step에서 변경된 토큰의 수는 불확실하다. 단순화를 위해 각 step에서 변경된 토큰의 수을 특정 수로 설정한다.
각 step의 state에 대해 마스크 수를 계산하고 적절한 timestep을 timestep embedding으로 선택할 수 있다. 입력을 $x_t$라 가정할 때 두 집합 \(A_t := \{ i \vert x_t^i = [\text{MASK}]\}\)와 \(B_t := \{ i \vert x_t^i \ne [\text{MASK}]\}\)가 있다. 각 step에서 $\Delta_z$개의 [MASK] 토큰을 $A_t$로부터 복구하는 것을 목표로 한다. 따라서 전체 inference step은 $T’ = (H \times W)/\Delta_z$가 되며, 여기서 $H$와 $W$는 토큰의 공간 해상도이다.
현재 timestep $t$는
\[\begin{equation} \underset{t}{\arg \min} \| \frac{| A_t |}{H \times W} - \overline{\gamma}_t \|_2 \end{equation}\]로 계산할 수 있으며, $\vert A \vert$는 집합 $A$의 원소의 개수이다. $\Delta_z = 1$이면 autoregressive 모델과 inference 속도가 동일해진다. Fewer tokens sampling은 이전에 광범위하게 연구된 빠른 샘플링 전략과 반대로 inference 시간을 희생하여 높은 샘플링 품질을 달성하고자 한다.
Fewer tokens sampling의 자세한 알고리즘은 다음과 같다.

각 timestep $t$에 대하여 먼저 [MASK] 토큰의 위치 $i$를 모두 찾아 $A_t$에 넣는다. $A_t$의 원소 중 $\Delta_z$개의 원소를 랜덤하게 뽑아 $C_t$에 넣는다. 그런 다음 \(p_\theta (\tilde{x}_0 \vert x_t, y)\)에서 \(x_{0,t}\)를 샘플링하며, 이는 \(p_\theta (x_{t-1} \vert x_t, y)\)에서 샘플링하는 것과 효과가 같다. 그리고 $C_t$의 원소에 대하서만 토큰을 교체한다. 즉, 총 $\Delta_z$개의 토큰만 교체되는 것이다. 그런 다음 알맞은 timestep $t$를 계산하다.
Purity prior sampling
Posterior distribution 식으로부터 다음 보조정리를 도출할 수 있다.
Lemma 1. $x_t^i = [\text{MASK}]$인 임의의 위치 $i$에 대하여 $q(x_{t-1}^i = \text{[MASK]} \, \vert \, x_t^i = \text{MASK}, x_0^i) = \overline{\gamma}_{t-1} / \overline{\gamma}_t$이다.
증명)
$x_t^i = [\text{MASK}]$를 만족하는 위치 $i$에 대하여, $$ \begin{aligned} & q(x_{t-1}^i = [\text{MASK}] \, | \, x_t^i = [\text{MASK}], x_0^i) \\ =& q(x_{t-1}^i = K+1 \, | \, x_t^i = K+1, x_0^i) \\ =& \frac{(v^\top (x_t^i) Q_t v(x_{t-1}^i))(v^\top (x_{t-1}^i) \overline{Q}_{t-1} v(x_0^i))}{v^\top (x_t^i) \overline{Q}_t v(x_0^i)} \\ =& \frac{(v^\top (K+1) Q_t v(K+1))(v^\top (K+1) \overline{Q}_{t-1} v(x_0^i))}{v^\top (K+1) \overline{Q}_t v(x_0^i)} \\ =& \frac{1 \cdot (v^\top (K+1) \overline{Q}_{t-1} v(x_0^i))}{v^\top (K+1) \overline{Q}_t v(x_0^i)} \\ =& \frac{v^\top (K+1) \overline{Q}_{t-1} v(x_0^i)}{v^\top (K+1) \overline{Q}_t v(x_0^i)} \end{aligned} $$ $x_0$가 noise가 없는 상태이기 때문에 $x_0^i \ne [\text{MASK}]$임을 알 수 있다. 따라서 식을 정리하면 다음과 같다. $$ \begin{aligned} & q(x_{t-1}^i = [\text{MASK}] \, | \, x_t^i = [\text{MASK}], x_0^i) \\ =& \frac{v^\top (K+1) \overline{Q}_{t-1} v(x_0^i)}{v^\top (K+1) \overline{Q}_t v(x_0^i)} \\ =& \frac{\overline{\gamma}_{t-1}}{\overline{\gamma}_t} \end{aligned} $$
이 보조정리는 각 위치가 [MASK] 상태를 떠날 확률이 동일함을 보여준다. 즉, [MASK] 상태에서 [MASK]가 아닌 상태로의 변환은 위치 독립적이다. 그러나 위치에 따라 [MASK] 상태를 떠나는 confidence가 다를 수 있다. 특히 purity가 높은 위치는 일반적으로 confidence가 높다.
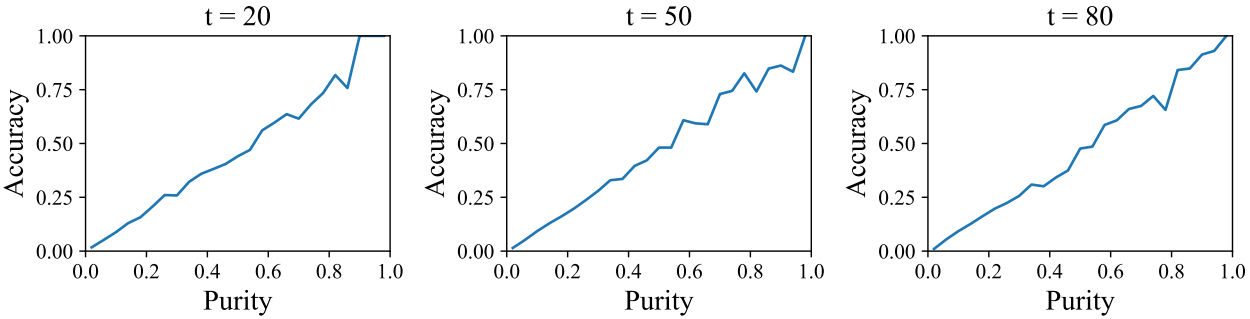
위 그림은 purity와 정확도 사이의 상관 관계를 보여준다. 일반적으로 purity 점수가 높을수록 토큰이 더 정확하다는 것을 나타낸다. 따라서 핵심 아이디어는 무작위 샘플링 대신 purity 점수에 의존하는 중요도 샘플링을 수행하는 것이다. 이 purity prior를 활용함으로써 각 step은 보다 신뢰할 수 있는 지역에서 토큰을 샘플링하여 샘플링 품질을 향상시킬 수 있다. 위치 $i$와 timestep $t$에서의 purity의 정의는 다음과 같습니다.
\[\begin{equation} purity(i, t) = \max_{j = 1 \cdots K} p(x_0^i = j | x_t^i) \end{equation}\]Purity prior sampling의 자세한 알고리즘은 다음과 같다.

Fewer tokens sampling과 알고리즘이 비슷하지만 $\Delta_z$를 일반적인 inference timestep으로 둘 수 있으므로 inference 시간을 희생할 필요가 없다. Fewer tokens sampling과 2가지 차이점이 있다.
- 각 위치에 대하여 purity를 계산하고, 위치를 랜덤하게 뽑는 대신 purity를 이용하여 중요도 샘플링으로 위치를 뽑는다.
- Purity가 높은 위치에서의 확률을 더 sharp하게 만드는 것이 품질 향상에 도움이 되기 때문에 softmax 함수를 사용하여 다음과 같이 $\tilde{x}_0$을 변경한다.
$r$은 hyper-parameter이고 실험에서는 0.5와 2 사이의 값을 사용하였다.
Experiments
- 데이터셋: CUB-200, MSCOCO, CC (균형있는 700만개 사용), ITHQ (2억개의 고품질 text-image 쌍을 인터넷에서 수집)
- Backbone:
- Improved VQ-Diffusion-B는 파라미터 약 3.7억개 (VQ-Diffusion-B와 동일한 구조)
- Improved VQ-Diffusion-L은 1408 차원의 36개의 transformer block (파라미터 약 12.7억개)
- Evaluation metrics: FID, Clip 점수, Quality Score (QS), Diversity Score (DS)
- DS = 1 - DDS (Diversity Difference Score)
1. Ablation Studies
Discrete classifier-free guidance
다음 표는 MSCOCO와 CC 데이터셋에 대하여 discrete classifier-free guidance가 얼마나 성능을 향상시키는 지에 대한 결과이다.
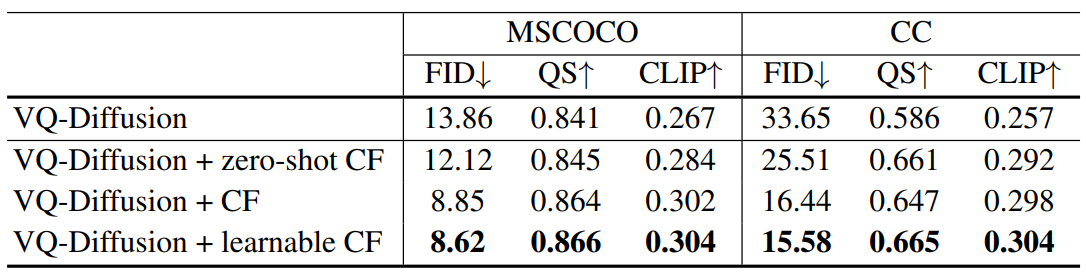
위와 같이 4가지 모델을 비교했다.
- 오리지널 VQ-Diffusion 모델
- Null vector를 조건부 입력으로 주고 classifier-free guidance를 사용한 경우
- Fine-tuning 단계에서 10%의 조건부 입력을 null vector로 주고 classifier-free guidance를 사용한 경우
- 10%의 조건부 입력을 null vector 대신 learnable vector로 주고 classifier-free guidance를 사용한 경우
다음은 guidance scale $s$가 결과에 미치는 영향을 나타낸 그래프다.
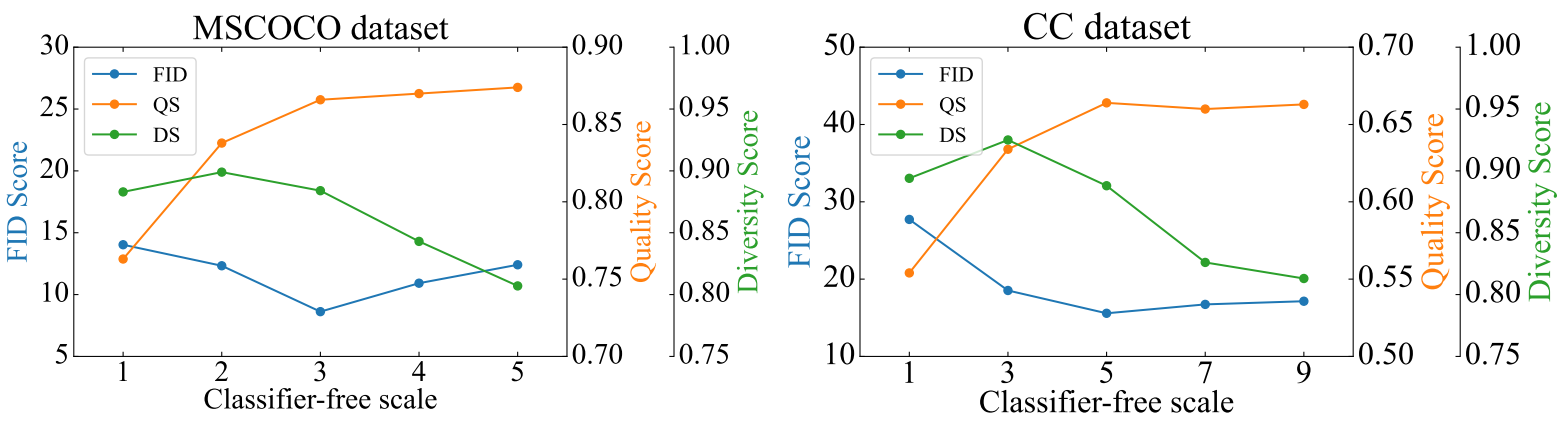
$s$가 증가하면 QS가 증가하고 DS가 감소하는 것을 확인할 수 있다. 이는 classifier-free 샘플링이 품질과 다양성 사이의 균형임을 보여준다.
다음은 CC 데이터셋의 learnable classifier-free 샘플링 결과이다.
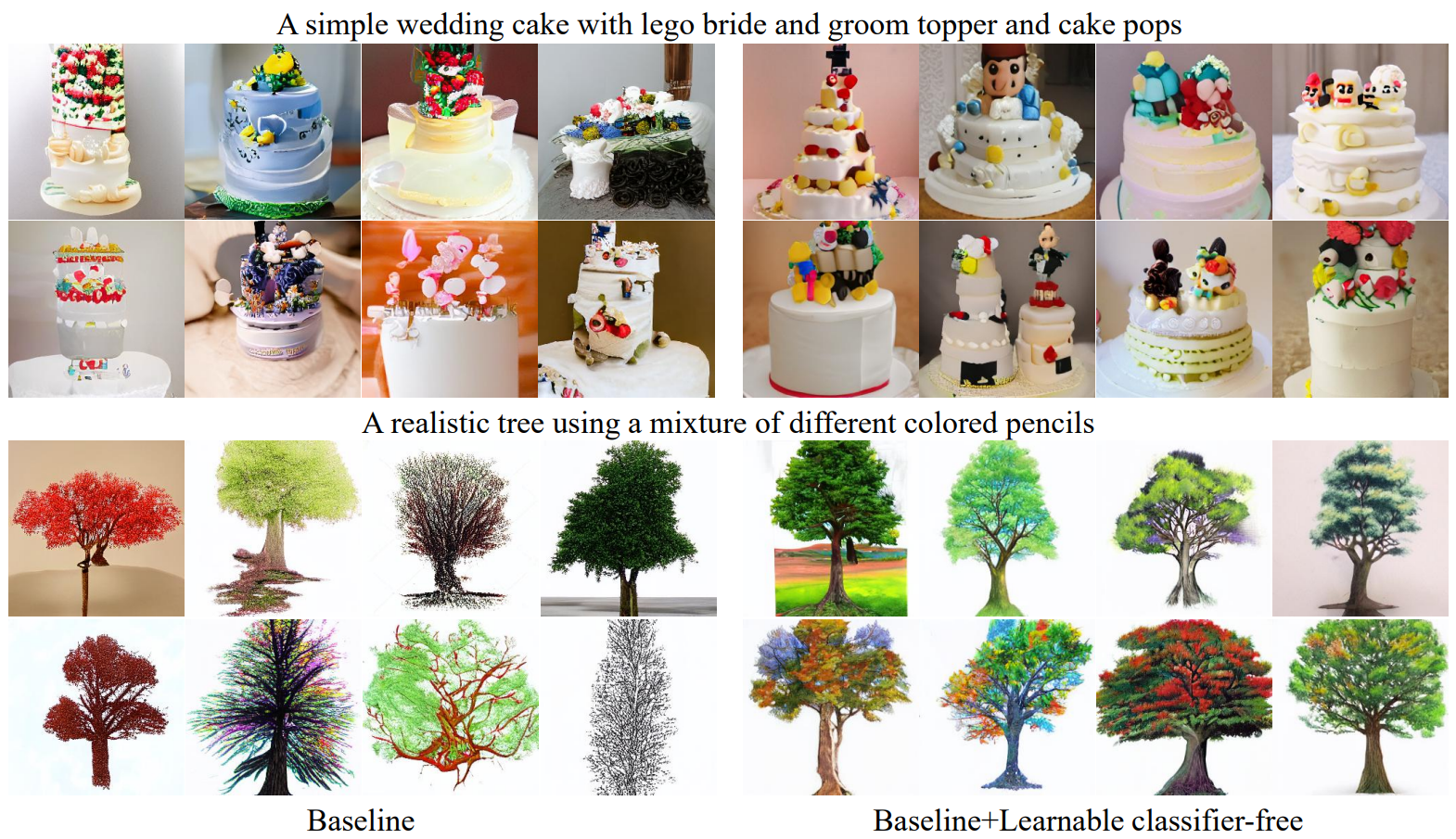
High-quality inference strategy
VQ-Diffusion 논문은 학습에 사용한 step보다 적은 step으로 inference하는 빠른 샘플링 전략을 사용하였다. 다음은 이 논문에서 사용한 고품질 inference 전략을 빠른 샘플링 전략과 비교한 결과이다. 실험은 CUB-200으로 진행되었다.
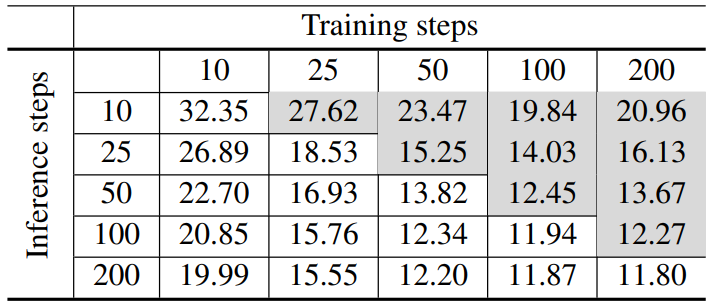
Purity prior sampling
다음은 purity prior sampling에 대한 비교 결과이다.

높은 purity의 토큰은 [MASK] 상태를 벗어날 확률이 높다는 것을 의미한다.
3. Compare with state-of-the-art methods
다음은 여러 state-of-the-art 모델과의 FID 비교 결과이다.
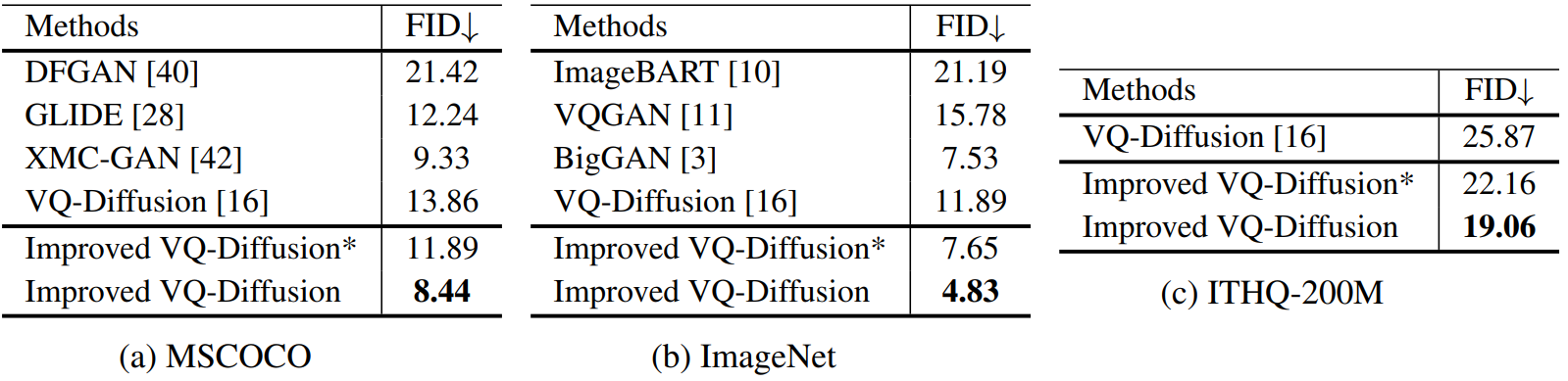
표의 “Improved VQ-Diffusion*“는 well-trained VQ-Diffusion 모델에 fine-tune 없이 zero-shot classifier-free 샘플링 전략과 고품질 inference 전략만 사용한 모델이다. Fine-tune 없이 두 전략을 사용하는 것만으로도 성능이 개선되었다.
4. Text-to-Image Synthesis
다음은 MSCOCO에서 이전 연구들과의 정성적 비교 결과이다.

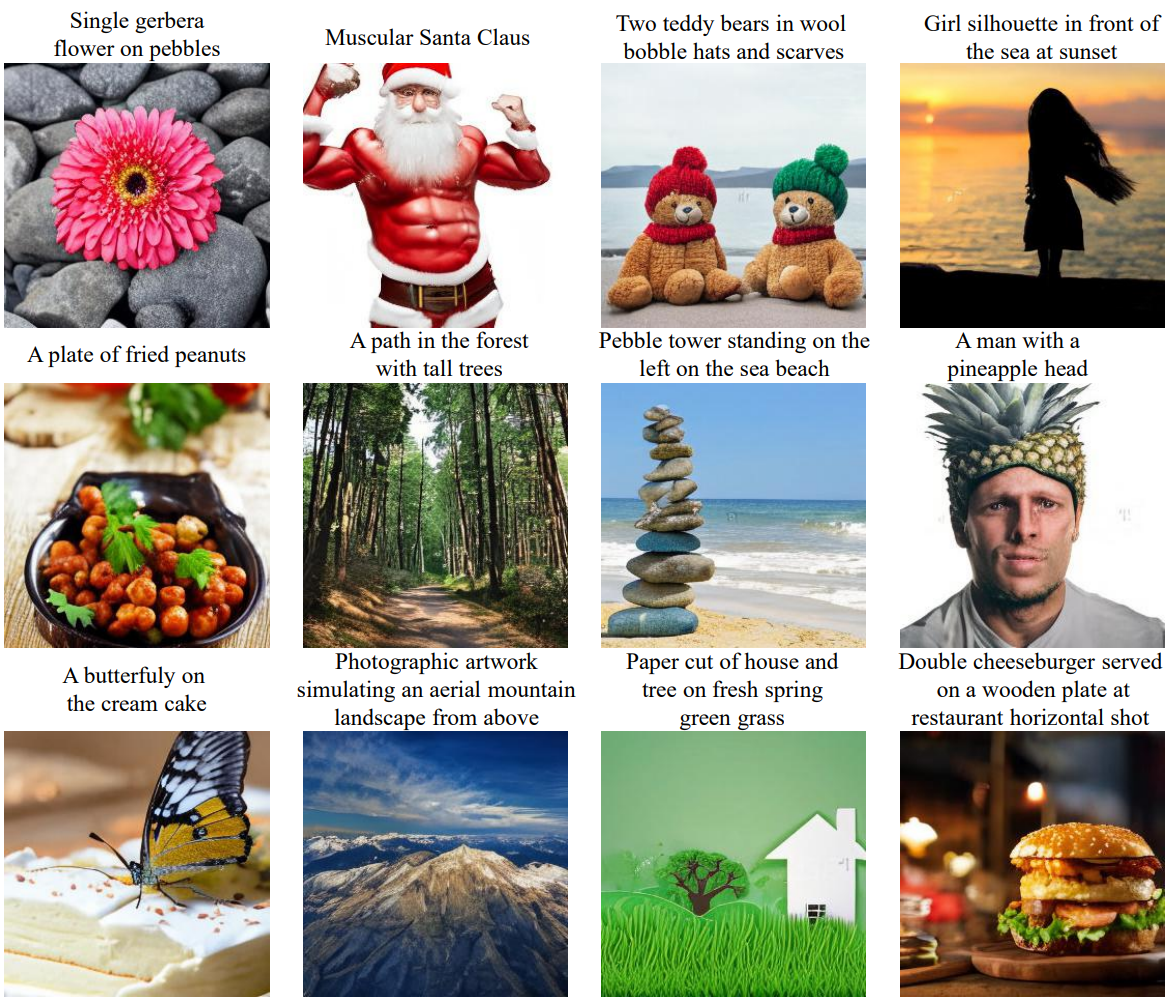
다음은 Improved VQ-Diffusion의 in-the-wild text-to-image 합성 결과이다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)