






CVPR 2022 Oral. [Paper] [Github]
Ming Tao, Hao Tang, Fei Wu, Xiao-Yuan Jing, Bing-Kun Bao, Changsheng Xu
13 Aug 2020
Introduction The two main challenges in text-to-image synthesis using GANs are:
- The authenticity of the generated images.
- The semantic consistency between the given text and the generated image.
Due to the instability of GANs, most existing models have used a stack structure as a backbone for high-resolution image generation (e.g., StackGAN) and cross-model attention between text and image features to enhance their correlation.
However, existing state-of-the-art models still have three major issues, and the paper proposes solutions for each of them.

The stack structure creates entanglement between generators, resulting in a final image that is a simple combination of blurry shapes and details (as each generator creates features at different image scales). → The paper proposes using a one-stage backbone to solve this issue (with only one generator).
During the training process, fixing other networks can make it too easy for the generator to deceive them, leading to weaker semantic consistency. → To increase semantic consistency, the paper proposes using a Target-Aware Discriminator with Matching-Aware Gradient Penalty (MA-GP) and One-Way Output.
Cross-modal attention is computationally expensive and cannot be used at every stage, resulting in text information not being fully utilized. → To solve this issue, the paper proposes using the Deep text-image Fusion Block (DFBlock) to more effectively and deeply combine text information with image features.
DF-GAN’s architecture
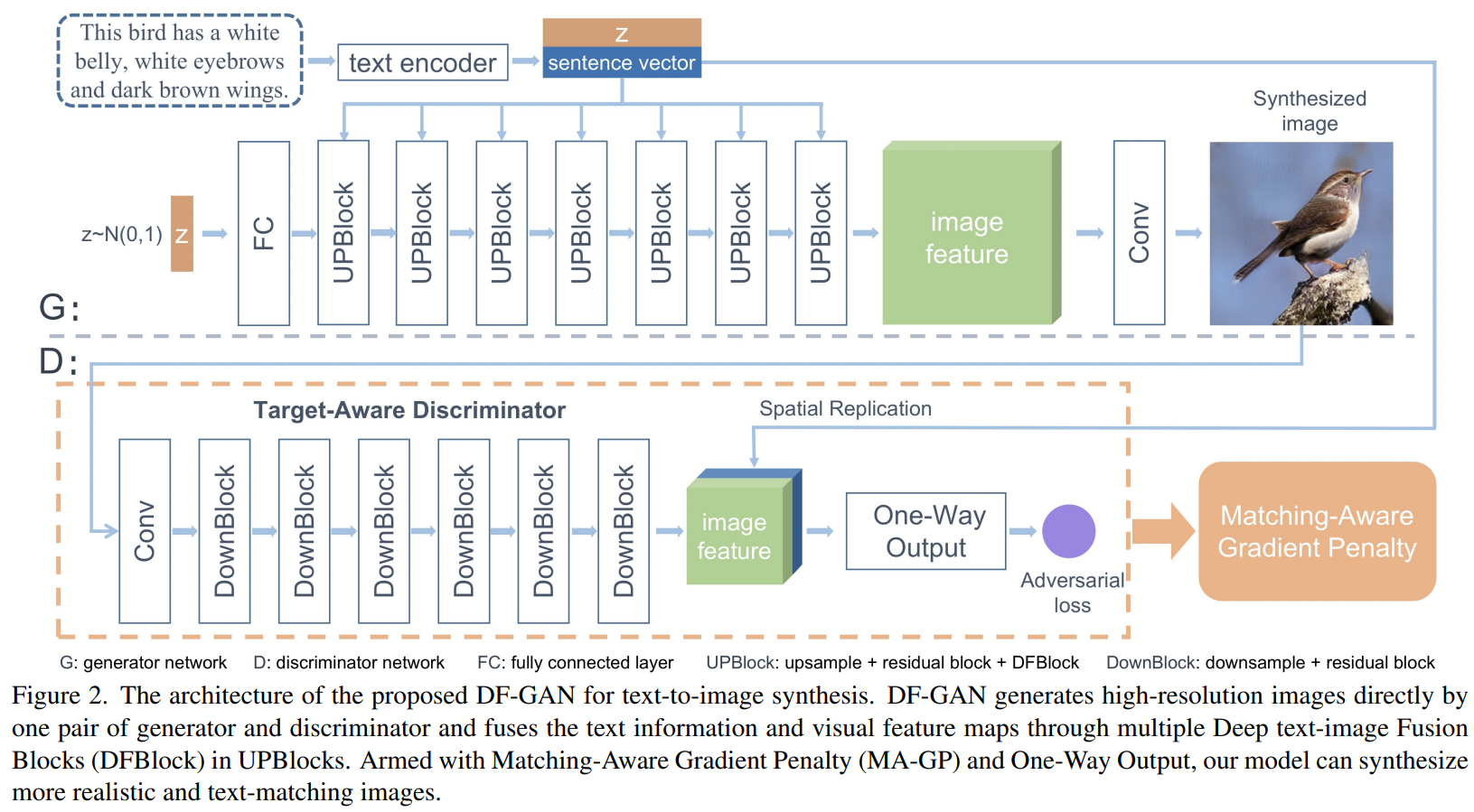
1. One-Stage Text-to-Image Backbone
- A lot of layers are required because high-resolution images must be generated from noise
- → Because the model is deep, it is configured as a residual network for stable learning
Using hinge loss for stable learning
In the equation below, the loss function applying the hinge loss is the distribution of generated data, actual data, and mismatch data)
- Applying the hinge loss to the loss function (\(z\)는 noise vector, \(e\)는 sentence vector, \(\mathbb{P_g}\), \(\mathbb{P_r}\), \(\mathbb{P_{mis}}\) is the distribution of generated data, real data, and mismatch data)
2. Matching-Aware Gradient Penalty (MA-GP)
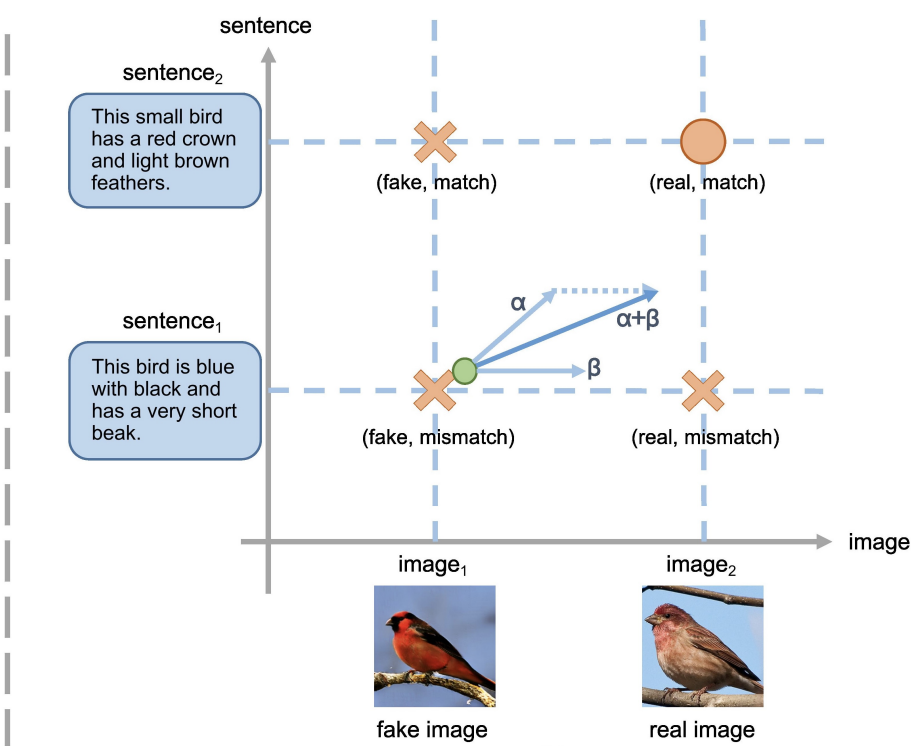
- Using a gradient penalty for real data smooths the loss function around the real data, which makes the synthetic data converge to the real data. In other words, the gradient penalty for the target data helps convergence of the generator.
- In text-to-image generation, there are 4 cases: (fake image, real image) x (match text, mismatch text)
- For semantic consistency, a gradient penalty for (real image, match text) should be used.
- The expression below is the loss function applying MA-GP ($k$ and $p$ are hyper-parameters to control the effect of the gradient penalty)
3. One-Way Output
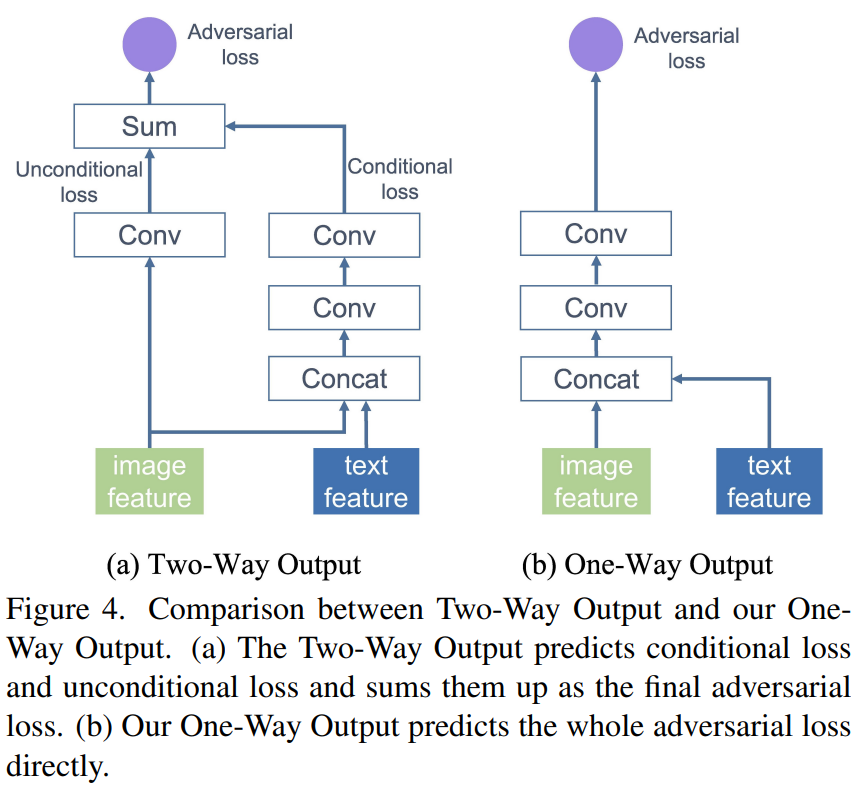
- In the existing model, the image features of the discriminator were used in two ways: real/fake classification (unconditional loss) and text-image semantic consistency evaluation (conditional loss).
- This Two-Way Output reduces the effect of MA-GP and delays the convergence of the generator.
- This is because conditional loss converges in the (real image, match text) direction, and unconditional loss converges only in the real image direction.
- Therefore, one-way output should be used to converge only in the direction (real image, match text).
4. Deep Text-Image Fusion Block (DFBlock)
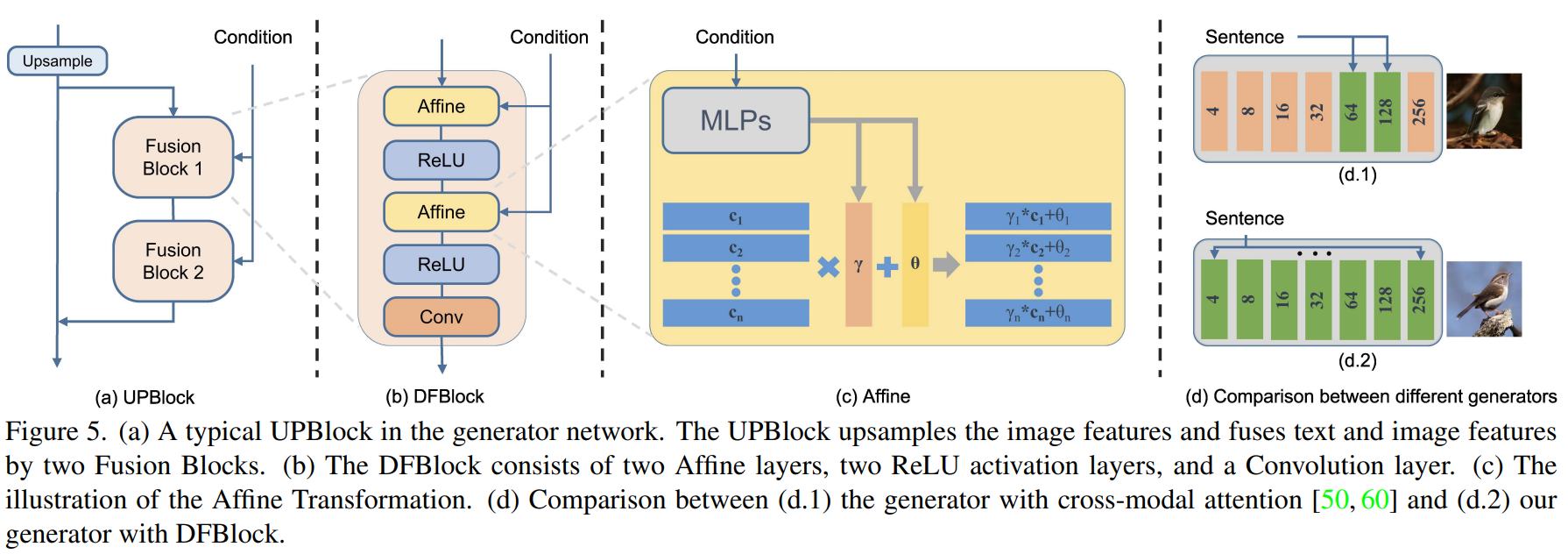
- The affine layer serves to expand the generator’s conditional representation space.
- Affine transformation: Calculate scaling parameter and shifting parameter with two MLPs
- → Since it is a linear transformation, add nonlinearity with ReLU
- Advantages (1) Generator uses more text information (2) As the representation space expands, images with high semantic consistency are created in various texts. (3) The cross-modal attention of the existing model increases the computational cost rapidly when the image size increases, but the affine transformation does not.
Experiments
- Dataset: CUB bird (11,788 images, 200 species), COCO (80k training / 40k testing)
- Adam ($\beta _1 = 0, \beta _2 = 0.9$), $lr_g$ = 1e-4, $lr_d$ = 4e-4, TTUR
- Evaluation: IS, FID for 30,000 256x256 images (text is random)
- COCO dataset was excluded because IS was inappropriate as an evaluation index
- NoP (number of parameters) is also evaluated
Examples

Results

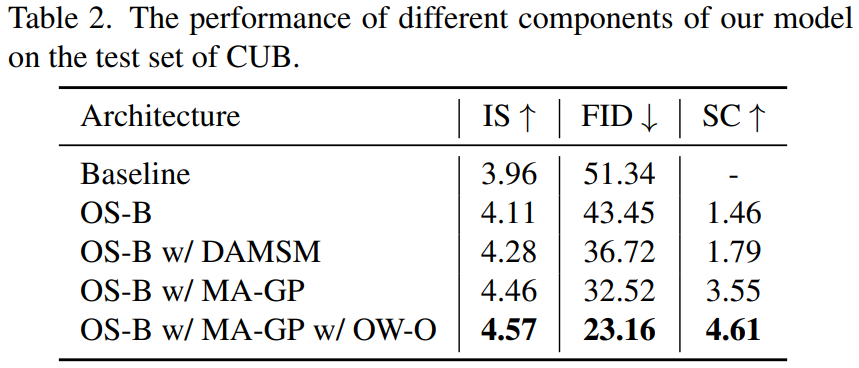
Ablation study

Limitation
- DF-GAN only handles text information at the sentence level. Its ability to synthesize fine-grained visual features is unknown.
- The use of pre-trained large language models may have contributed to the performance improvement.
Personal Thoughts
Compared to recent diffusion-based models, the performance of DF-GAN is not as good. However, at the time this paper was published, it showed state-of-the-art performance and was very fast, with only 19M parameters (NoP).
- One downside is that there is too little explanation about the text encoder. This is disappointing because how well the text encoder represents text information is an important part of text-image semantic consistency.
Looking at the actual implementation code, it seems that RNN was used for the text encoder instead of a Transformer-based model, perhaps to reduce the model’s size. Alternatively, the authors may have thought that pre-trained RNN performance was sufficient. In the future, it would be interesting to see if using a pre-trained Transformer as the text encoder improves performance.
- Another downside is that the paper did not address generating images larger than 256x256. Existing models show poor results when generating images larger than 256x256. DF-GAN used various methods to overcome the limitations of existing models, but it would have been better if there were experiments to see if these methods also work well for generating larger images.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)