






arXiv 2023. [Paper] [Github]
Jiamian Wang, Guohao Sun, Pichao Wang, Dongfang Liu, Sohail Dianat, Majid Rabbani, Raghuveer Rao, Zhiqiang Tao
Rochester Institute of Technology | Amazon Prime Video | Army Research Laboratory
CVPR 2024
0. Overview
- 기존 text-video retrieval 방식에서 단일 텍스트 embedding이 비디오의 복잡한 의미를 충분히 표현하기 어려운 문제를 해결하기 위해 새로운 확률적 텍스트 모델링 기법(T-MASS) 제안
- T-MASS는 텍스트를 단일 포인트가 아닌 확률적 text mass로 모델링하여 보다 유연하고 풍부한 의미 표현이 가능하도록 함
- Similarity-aware radius module 도입으로 text-video pair에 맞춰 text mass의 크기를 동적으로 조절
- Support text regularization을 통해 학습 시 text mass를 효과적으로 제어
- T-MASS는 기존 방식 대비 R@1에서 3~6% 성능향상 및 MSRVTT, LSMDC, DiDeMo, Charades, VATEX 데이터셋에서 SOTA 달성
1. Introduction

영상 데이터의 폭발적인 증가로 인해 text-video retrieval 연구가 활발히 진행되고 있다. 기존 접근 방식은 텍스트와 비디오를 동일한 embedding 공간에 매핑하여 유사도를 계산하는 방식이 주류를 이루고 있다. 하지만 기존 데이터셋의 텍스트는 짧고 간결하여 비디오의 다양한 의미를 온전히 반영하기 어려운 문제가 있다.
이러한 한계를 극복하기 위해 본 연구에서는 텍스트 embedding을 단일 포인트가 아닌 확률적 질량(probabilistic mass)으로 모델링하는 T-MASS (Text Modeled As a Stochastic embedding) 방법을 제안한다
- 비디오의 다양한 의미를 보다 유연하게 표현 가능
- 텍스트-비디오 embedding 간의 alignment 문제 완화
- 불확실성까지 반영하는 효과적인 검색 가능
기존 방법과의 차별점으로, T-MASS는 단순한 텍스트 포인트가 아닌 분포(distribution) 형태로 텍스트를 모델링하며, 유사도 기반 반경 조절 모듈(similarity-aware radius module)과 support text vector를 활용하여 효과적인 학습 및 추론을 수행한다.
2. Method
2.1. Preliminaries
- 텍스트를 $t$, 원본 비디오 클립을 $v$라고 정의
- Text-video retrieval은 $t, v \in \mathbb{R}^d$의 공통 embedding 공간을 학습하는 과정
- Cosine similarity 등 similarity 측정 함수 $s(t, v)$를 사용하여 텍스트-비디오 간 연관성을 평가
- 손실 함수는 Symmetric Cross Entropy를 사용하여 관련된 쌍은 가깝게, 무관한 쌍은 멀어지도록 학습
- 손실 함수는 모든 관련 텍스트-비디오 쌍의 유사도가 1, 무관한 쌍의 유사도가 0이 되는 이상적인 상태를 목표로 함
2.2. Text-Video Representations
Feature Extraction
- 최근 연구들은 CLIP의 강력한 표현력을 활용하여 텍스트와 비디오 간의 검색 성능을 향상시키고 있음
- 비디오는 $T$ 개의 프레임으로 구성되며, 일부 프레임 $T’$ 만을 샘플링하여 CLIP에 입력
- CLIP의 이미지 인코더 $\phi_v$ 와 텍스트 인코더 $\phi_t$ 를 사용하여 특징을 추출 \(\mathbf{f}_i = \phi_v(f_i), \quad i = 1, ..., T' \quad \mathbf{t} = \phi_t(t)\)
- 기존 연구들은 프레임 특징들을 다양한 방식으로 결합하여 최종 비디오 임베딩을 생성 \(\mathbf{v} = \psi([\mathbf{f}_1, ..., \mathbf{f}_{T'}], \mathbf{t})\)
- $\psi(\cdot)$ : 프레임-텍스트 상호작용을 활용하는 융합 모듈
Motivation
- 기존 연구들은 비디오 임베딩 학습($\mathbf{v}$ including frame sampling protocol, $\phi_v(\cdot)$, $\psi(\cdot)$) 에 집중했으며, 텍스트 표현력 부족 문제를 충분히 해결하지 못함
- 텍스트 $\mathbf{t}$는 비디오 $\mathbf{v}$에 비해 표현력이 낮으며, 비디오가 제공하는 풍부한 단서를 온전히 반영하기 어려움
- 이를 해결하기 위해 텍스트를 단일 포인트가 아닌 확률적 질량(text mass)으로 모델링하는 방법을 제안
2.3. Proposed Method: T-MASS
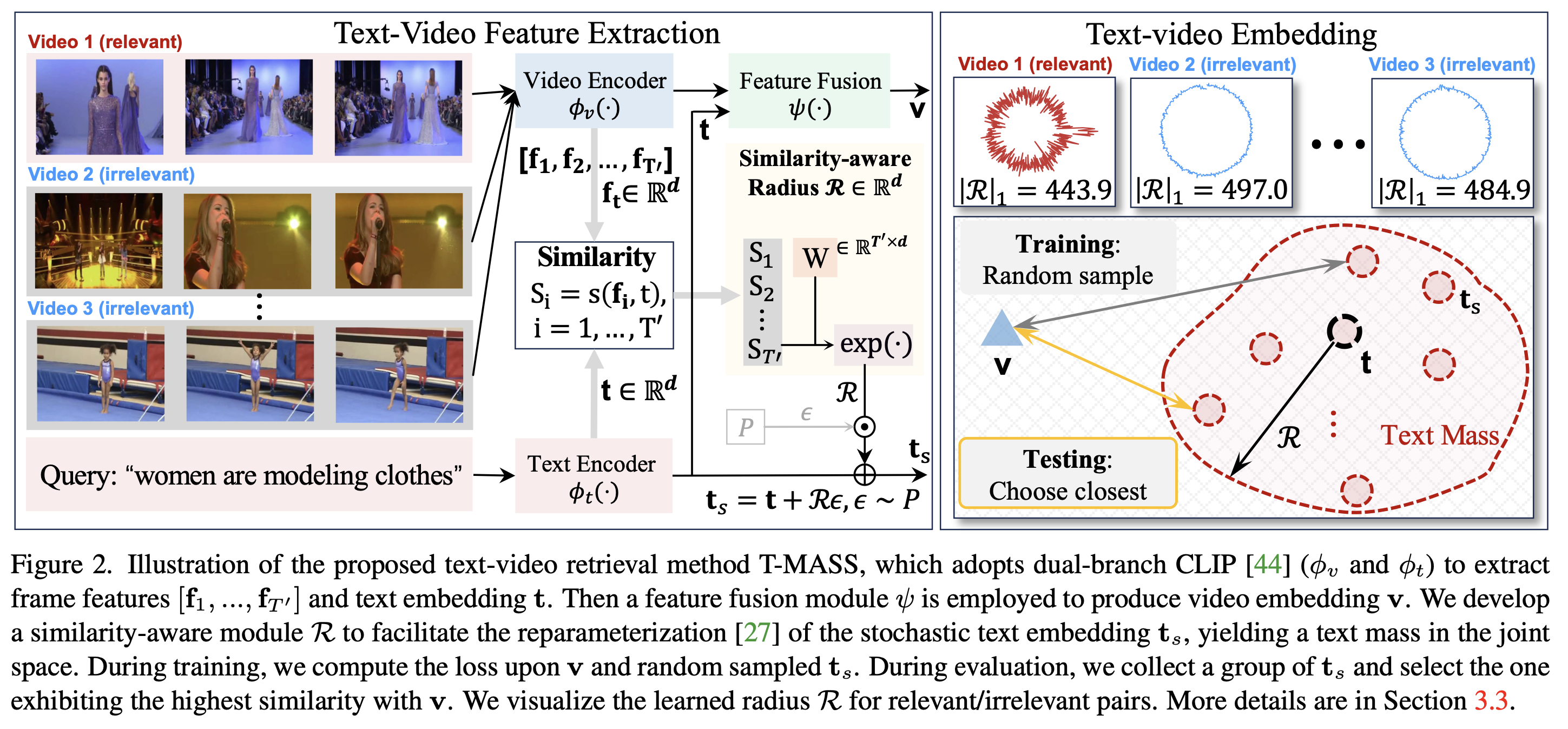
Stochastic Text Modeling
- 기존의 텍스트 임베딩 방식과 달리, 텍스트를 단일 점이 아니라 확률적 질량으로 간주
- 텍스트의 확장된 표현력 확보를 위해 확률적 변형 적용 \(\mathbf{t}_s = \mathbf{t} + R \cdot \epsilon, \quad \epsilon \sim P\)
- $\epsilon$: 정규 분포 $P = \mathcal{N}(0,1)$ 에서 샘플링된 노이즈 변수
- $R$: 텍스트 질량의 반경을 정의하며 학습 가능
- 기존 방법과 차별점
- 일반적인 CLIP 기반 접근법은 고정된 점(point embedding)을 사용하여 비디오와 매칭
- T-MASS는 확률적 분포를 통해 텍스트 표현의 유연성을 높이고, 의미적으로 더 강건한 매칭을 수행
Similarity-Aware Radius Modeling
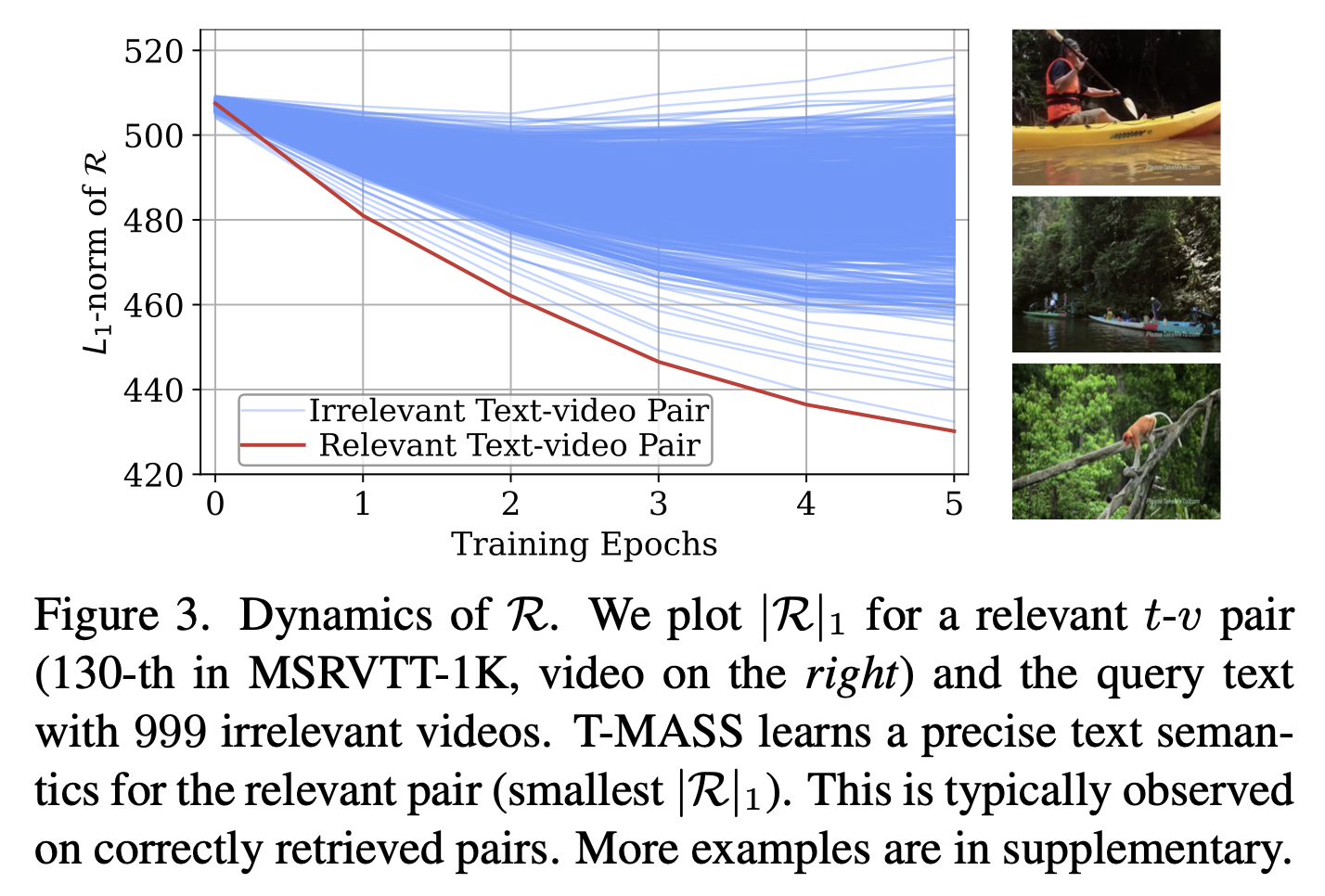
- 텍스트 질량의 반경 $R$을 동적으로 조절하는 모듈 도입
- 비디오-텍스트의 cosine similarity를 기반으로 반경을 학습: \(S_i = s(\mathbf{t}, \mathbf{f}_i), \quad i = 1, ..., T', \quad\) \(R = \exp\left( \frac{\theta}{T'} \sum_{i=1}^{T'} S_i \right)\)
- $\theta$: 학습 가능한 스칼라 파라미터
- 다양한 반경 조절 기법 실험
- 선형 변환을 추가하여 반경을 더욱 유연하게 학습: \(R = \exp(\mathbf{S} \mathbf{W}), \quad \mathbf{S} = [S_1, ..., S_{T'}]\)
- $\mathbf{W} \in \mathbb{R}^{T’ \times d}$: 학습 가능한 가중치 행렬
- 선형 변환을 추가하여 반경을 더욱 유연하게 학습: \(R = \exp(\mathbf{S} \mathbf{W}), \quad \mathbf{S} = [S_1, ..., S_{T'}]\)
Learning Text Mass in Joint Space
- 기존 Loss Function의 한계
- 기존 symmetric cross-entropy loss $\mathcal{L}_{ce}$ 는 text mass의 크기 조절이 어려움
- 단일 텍스트 임베딩 $\mathbf{t}$ 만 학습하여 텍스트-비디오 정렬이 제한적
- 확률적 텍스트 임베딩 $\mathbf{t}_s$ 를 샘플링하여 다양한 표현을 학습할 필요가 있음
- 확률적 텍스트 임베딩 학습
- 확률적 샘플링을 적용하여 기존 손실 함수 개선: \(\mathbf{t}_s = \mathbf{t} + R \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0,1)\)
- 새로운 손실 함수: \(\mathcal{L}_{\text{total}} = \mathcal{L}_{ce} + \mathcal{L}_s\)
- $\mathcal{L}_s$: 확률적 텍스트 임베딩 $\mathbf{t}_s$ 를 활용한 손실
텍스트 표현 다양성 증가 → 일반화 성능 향상 단일 $\mathbf{t}$ 가 아닌 다양한 표현을 학습 → 비디오와 정렬 문제 완화
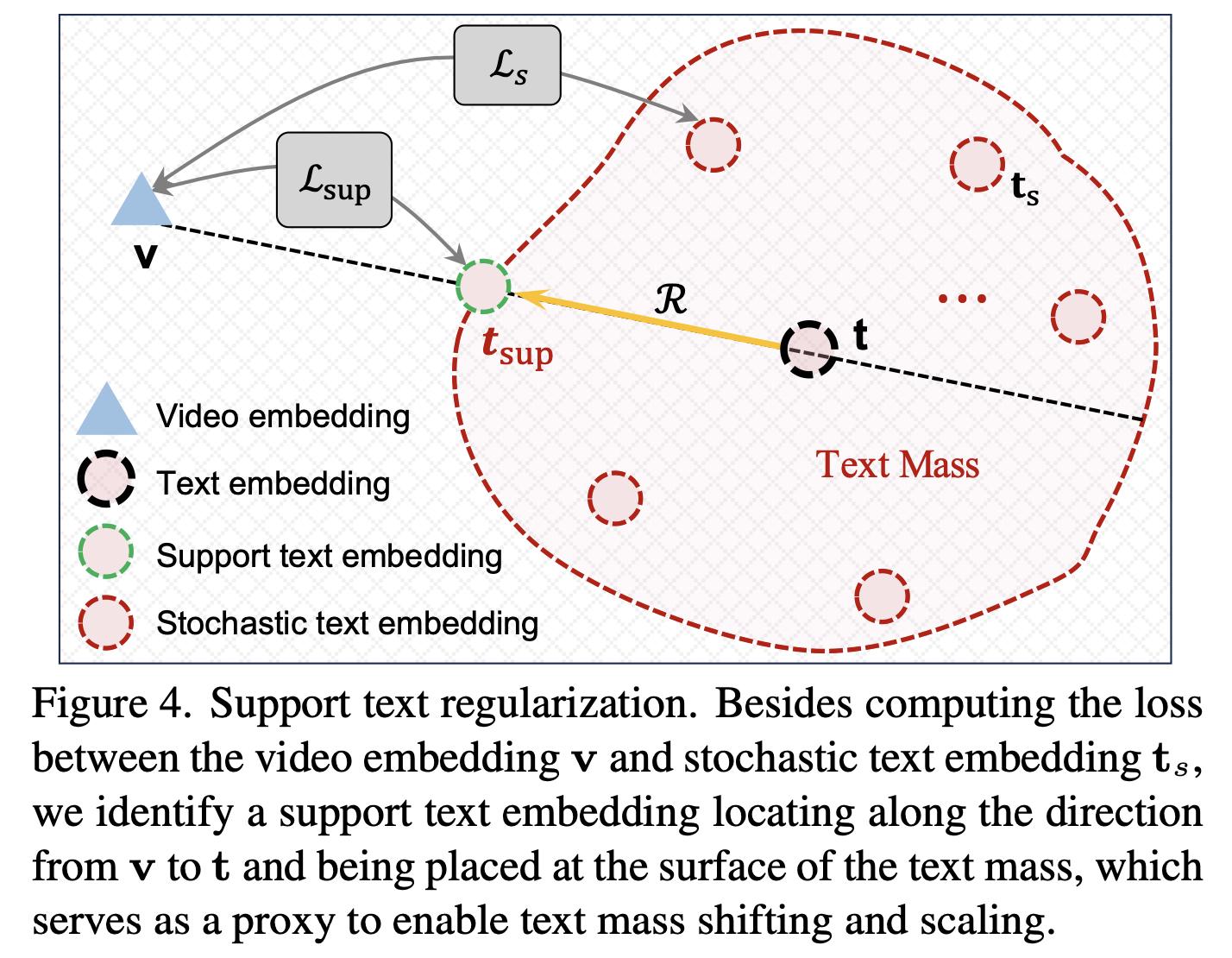
- Support Text Regularization 추가
- Support Text Embedding ($\mathbf{t}_{\text{sup}}$) 도입: \(\mathbf{t}_{\text{sup}} = \mathbf{t} + \frac{\mathbf{v} - \mathbf{t}}{|\mathbf{v} - \mathbf{t}|} R\)
- 추가 손실 함수 적용: \(\mathcal{L}_{\text{total}} = \mathcal{L}_s + \alpha \mathcal{L}_{\text{sup}}\)
- 텍스트 질량의 크기 및 이동 조절 → 학습 안정성 향상
Inference Pipeline
- T-MASS의 확률적 텍스트 표현을 활용하여 inference pipeline을 개선
- 기존 방법은 고정된 텍스트 임베딩 $\mathbf{t}$ 를 사용했지만, T-MASS는 확률적 샘플링을 통해 최적의 표현을 동적으로 선택
- 텍스트 및 비디오 특징 추출
- 주어진 텍스트-비디오 쌍 ${t, v}$ 에 대해 features인 $\mathbf{v}$을 추출 \(\mathbf{f}_i = \phi_v(f_i), \quad i = 1, ..., T'\) \(\mathbf{t} = \phi_t(t)\)
- 이후, 비디오 임베딩을 생성: \(\mathbf{v} = \psi([\mathbf{f}_1, ..., \mathbf{f}_{T'}], \mathbf{t})\)
- 확률적 텍스트 임베딩 샘플링
- 기존 단일 텍스트 임베딩 대신, 확률적 샘플링을 적용하여 $M$ 개의 텍스트 임베딩 생성
- $\mathbf{t}_s = \mathbf{t} + R \cdot \epsilon$ 에 따라 $M$번의 stochastic sampling을 진행함
\(\{\mathbf{t}_1^s, ..., \mathbf{t}_M^s\}, \quad \mathbf{t}_i^s = \mathbf{t} + R \cdot \epsilon_i, \quad \epsilon_i \sim \mathcal{N}(0,1)\)
- 다양한 표현을 탐색하여 최적의 텍스트-비디오 정렬을 수행
- 최적의 텍스트 임베딩 선택
- Video와 가장 similarity가 높은 text embedding을 선택: \(\hat{\mathbf{t}}_s = \arg \max_{\mathbf{t}_s} s(\mathbf{t}^i_s, \mathbf{v}), \quad i = 1, ..., M\)
- Feature fusion module $\psi(\cdot)$을 통해 video feature $\mathbf{v}$ 계산
- Final text embedding $\hat{\mathbf{t}}_s$는 확률적 샘플링된 임베딩 집합에서 선택됨
- Video에 따라 adaptive 변화하는 임베딩 생성
- 기존 고정된 텍스트 임베딩보다 더 유연한 표현 가능
- 비디오와 더 유사한 텍스트 임베딩 탐색
- 텍스트-비디오 및 비디오-텍스트 검색 모두 적용 가능
- T-MASS를 활용한 향상된 정렬 및 의미 적응
- 텍스트-비디오 정렬(text-video alignment) 개선
- 텍스트 의미 적응(text semantics adaptation) 지원
3. Experiment
3.1 Experimental Settings
Datasetss
- MSRVTT: 10K 비디오 클립, 각 클립당 20개의 캡션 제공. 1K-A 테스트 세트 사용
- LSMDC: 202개 영화에서 118,081개의 클립 포함. 1,000개 비디오를 테스트 데이터로 사용
- DiDeMo: 10,642개의 클립과 40,543개의 캡션 포함. 기존 연구와 동일한 데이터 분할 적용
- Charades: 9,848개의 비디오 클립 포함. 기존 연구와 동일한 분할 방식 사용
- VATEX: 34,991개의 비디오 클립 포함. 각 클립에 여러 개의 텍스트 설명 제공
- Evaluation Metrics
- Recall at Rank: R@1, R@5, R@10
- Median Rank (MdR), Mean Rank (MnR) 사용하여 검색 성능 평가
Implementation Details
- X-Pool 기본 모델로 사용
- CLIP (ViT-B/32 및 ViT-B/16) Backbone model 활용
- Hyperparameter
- Embedding dimension $d = 512$
- Weight decay = 0.2, Dropout = 0.3
- Batch size = 32 (모든 데이터셋에서 동일 적용)
- Learning rate: Feature fusion module $\psi(\cdot)$ 과 radius module $R$ 은 3e-5, CLIP은 1e-6으로 미세 조정
- AdamW 옵티마이저 사용, cosine scheduler 적용 (warm-up 비율 0.1)
- 비디오 샘플링
- 모든 데이터셋에서 12개 프레임을 균일하게 샘플링
- 프레임 크기 224 × 224 로 조정
- Inference 설정
- 샘플링 횟수 $T’ = 20$
- NVIDIA A6000 GPU 사용
3.2 Performance Comparison
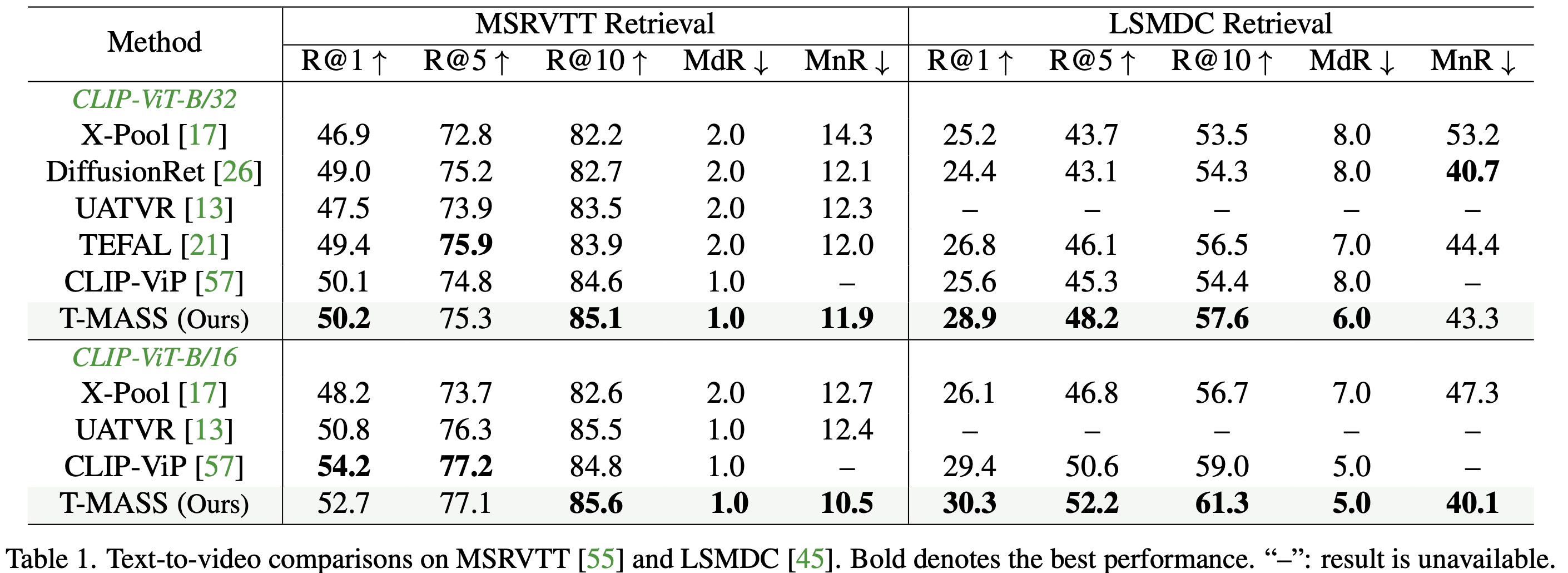
- T-MASS는 X-Pool을 크게 향상시키며, 최신 연구와 비교하여 SOTA 성능을 달성
- LSMDC에서 ViT-B/32 모델 기준 CLIP-ViP 대비 R@1 성능 3.3% 향상
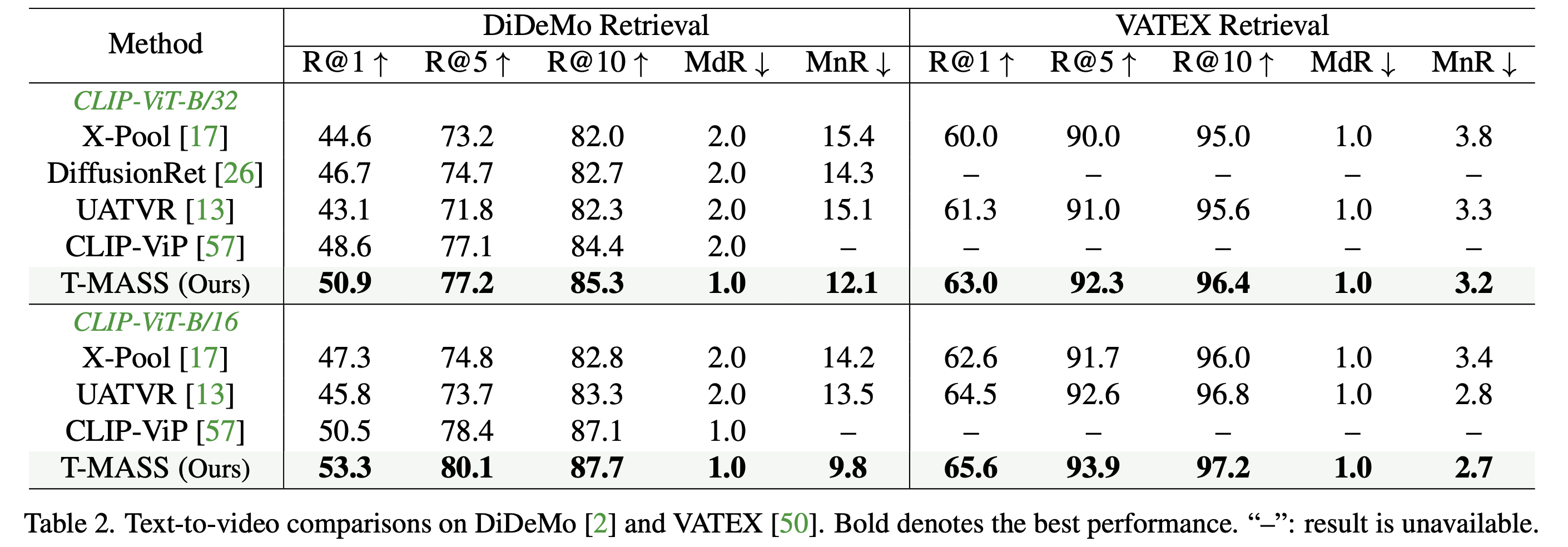
- DiDeMo에서 X-Pool 대비 R@1 성능 6.0% 향상 (ViT-B/16 기준)
- 일관된 성능 향상
- 다양한 데이터셋과 모델 크기에서 지속적인 성능 개선 확인됨
- 일부 MSRVTT 및 ViT-B/16 조합에서 CLIP-ViT가 더 높은 성능을 보임
- CLIP-ViP는 WebVid-2.5M, HD-VILA-100M등 추가 데이터셋을 활용하여 사전 학습된 모델
- 추가 데이터 없이도 T-MASS가 대다수 데이터셋에서 우수한 성능을 달성
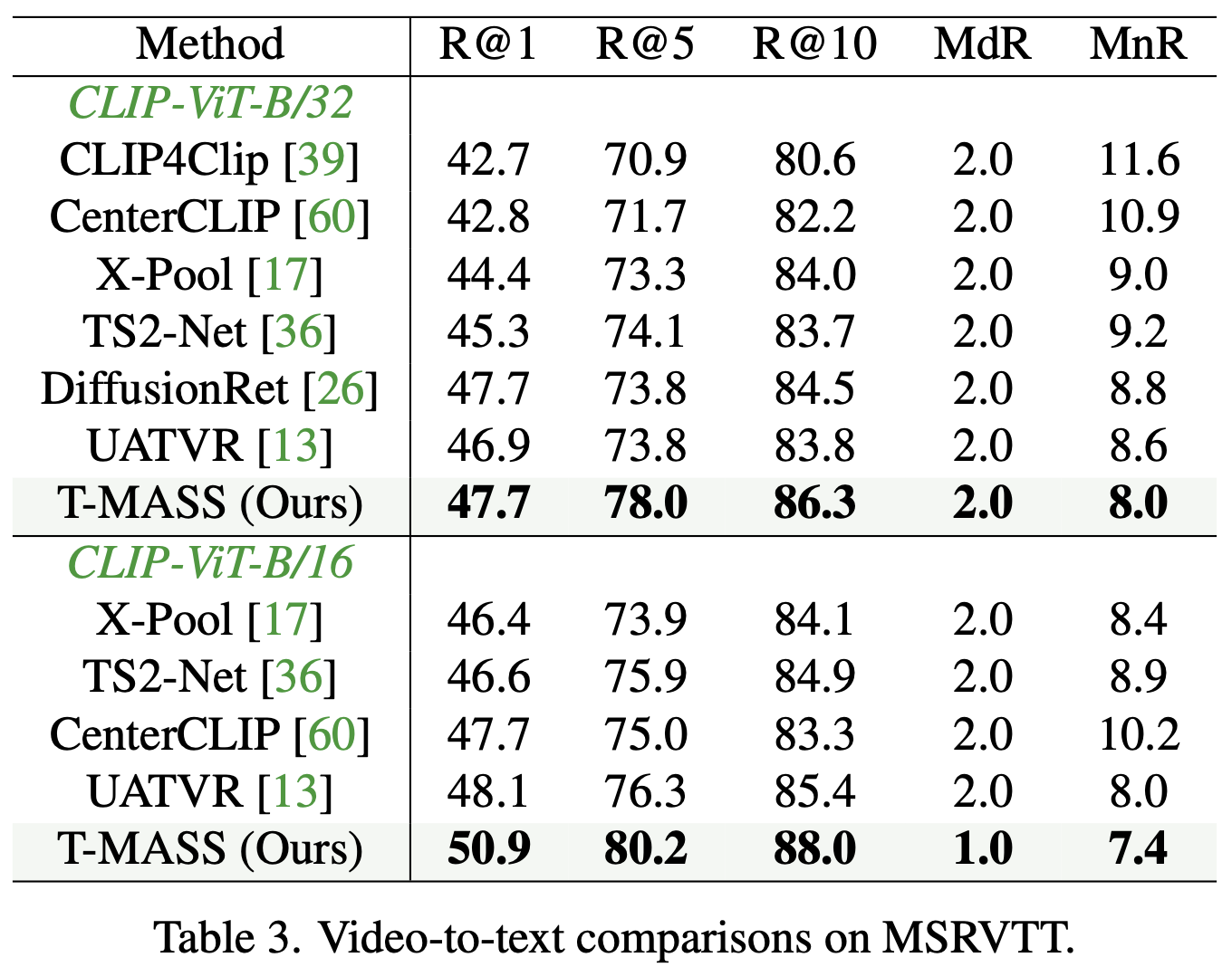
- 비디오-텍스트 검색(video-to-text retrieval)에서도 T-MASS가 최고 성능을 기록
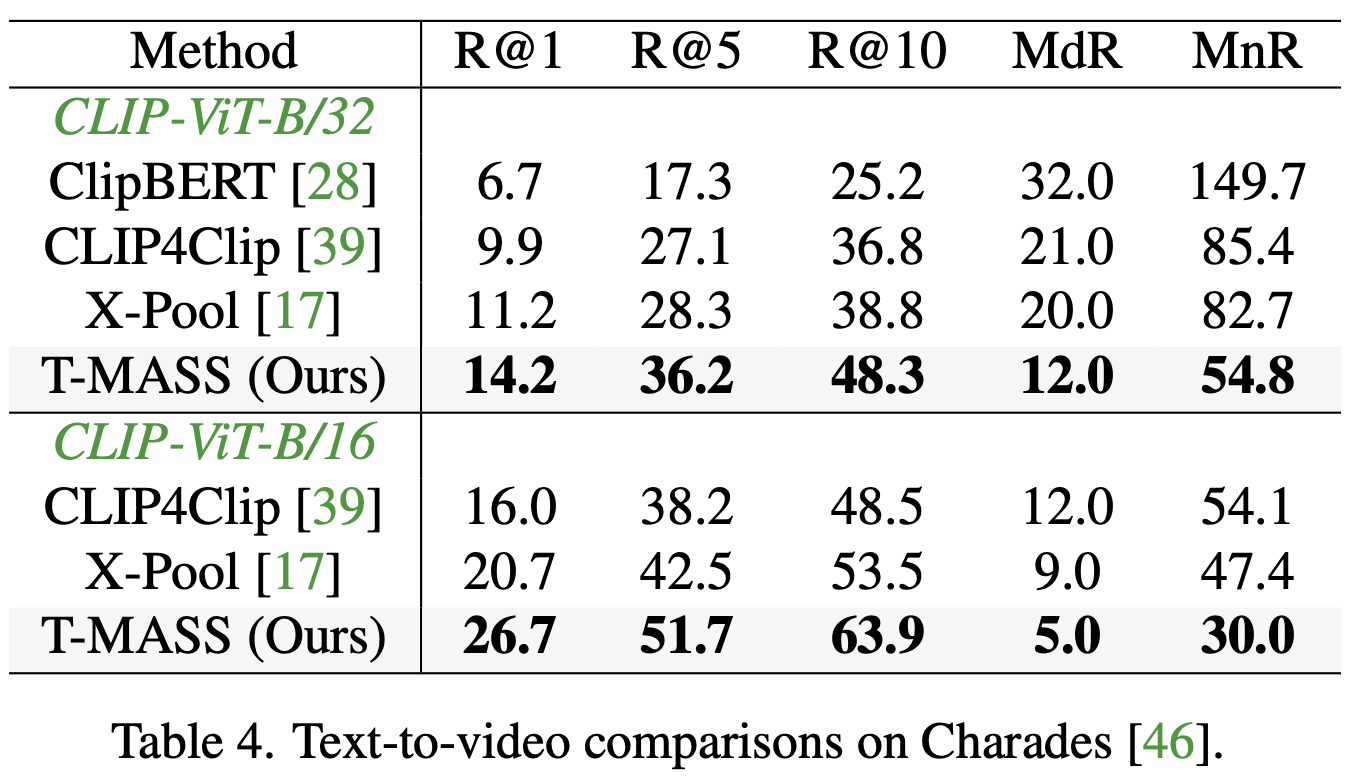
- Charades 데이터셋에서 T-MASS의 성능을 분석
- Charades는 행동 기반(action-centric) 비디오 데이터셋으로, 텍스트와의 정합성이 다른 데이터셋보다 상대적으로 난이도가 높음
- T-MASS는 **R@1, R@5, R@10, MdR, MnR 등의 모든 평가 지표에서 X-Pool을 능가
- 특히 R@1에서 X-Pool 대비 성능 향상이 두드러지며, 텍스트 질량(text mass)이 행동 중심 비디오 데이터셋에서도 효과적으로 작용함을 시사
3.3 Model Discussion
Similarity-Aware Radius

- 유사도 기반 반경 모듈을 세 가지 방식으로 구현
- (1) $\exp(\frac{1}{T’} \sum S_i)$: 코사인 유사도만을 기반으로 반경 조절 (학습 불가)
- (2) $\exp(\frac{\theta}{T’} \sum S_i)$: 학습 가능한 스칼라 $\theta$ 추가
- (3) $\exp(SW)$: 선형 레이어를 활용한 반경 조절 (학습 가능)
- 반경 모델링 기법 성능 비교
- MSRVTT에서 >1.5% R@1 성능 향상, DiDeMo에서 >3% 향상
- $\exp(SW)$ 방식이 대부분의 경우에서 가장 우수한 성능 보임
Ablation Study
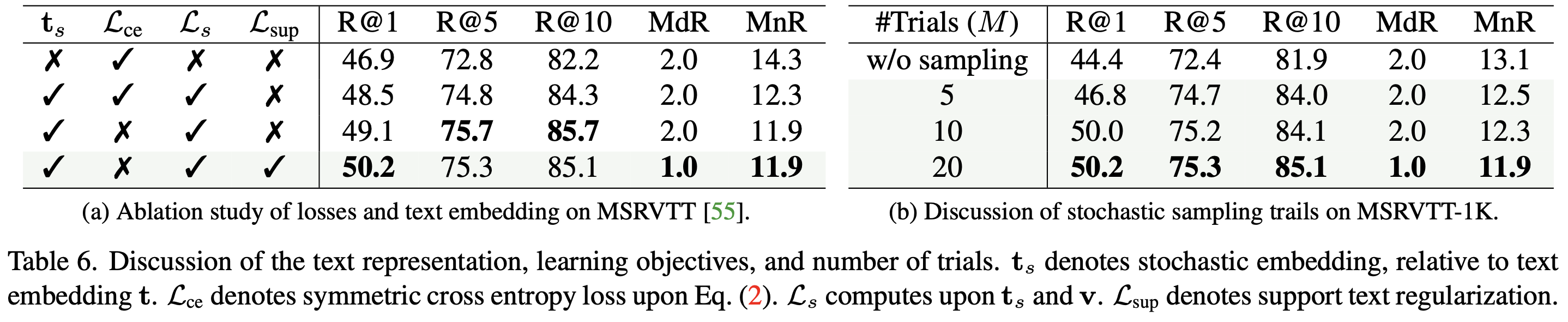
- Table 6a에서 ablation 실험 수행
- 기본 X-Pool 대비 확률적 텍스트 임베딩 $\mathbf{t}_s$ 사용 시 R@1 1.6% 증가
- 기존 $\mathcal{L}_{ce}$ 를 유지한 경우, 오히려 성능이 저하됨
- 단일 $\mathbf{t}$ 에 대한 규제가 편향된 학습을 초래하여 retrieval 성능 저하
- Support Text Embedding ($\mathbf{t}_{sup}$) 도입 후 최적 성능 달성
- 텍스트 질량의 스케일 및 이동 조절 가능
Inference Discussion
- Table 6b에서 Inference 샘플링 횟수 M의 영향 분석
- 샘플링 없이 원래 $\mathbf{t}$ 만 사용할 경우 최적 성능 달성 불가
- $M$을 5에서 20으로 증가시키면 성능 향상, 이후 안정적으로 유지됨
- 최적 설정: M = 20 (성능과 계산 비용 간 균형 유지)
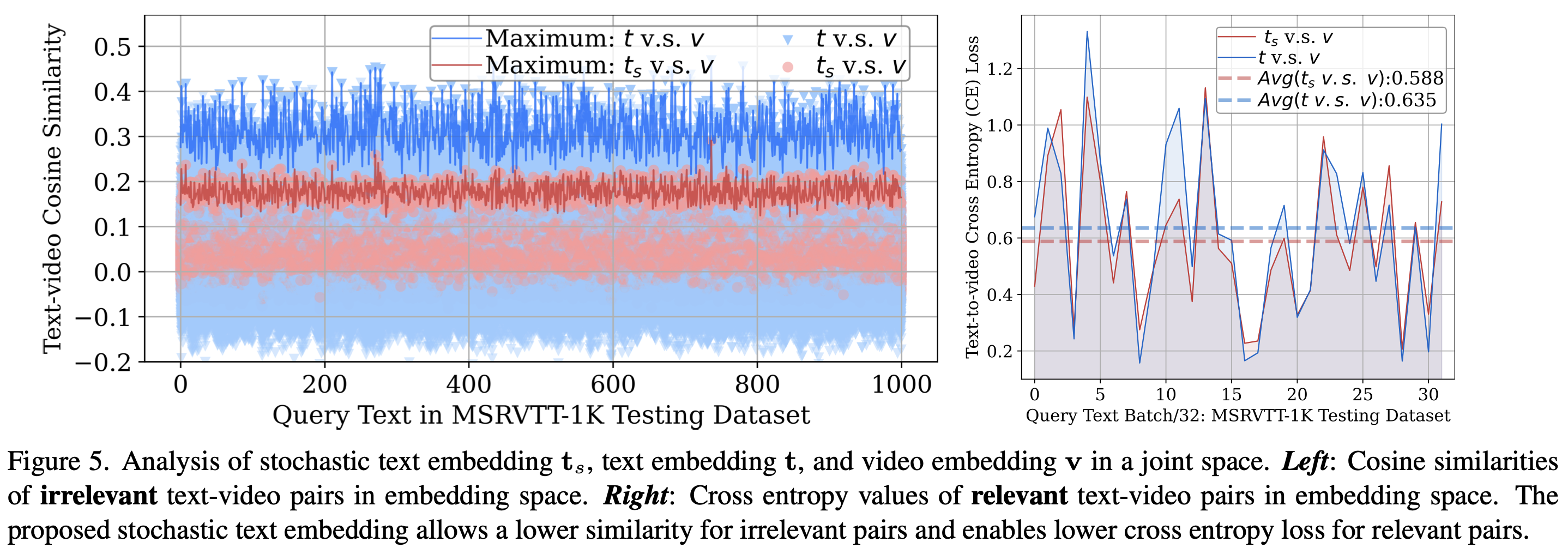
Further Analysis on T-MASS
- Figure 5 (left): 비관련 텍스트-비디오 쌍의 코사인 유사도 비교
- T-MASS의 확률적 텍스트 임베딩 $\mathbf{t}_s$ 사용 시, 비관련 샘플 간 유사도 값이 감소
- 검색 정확도가 높아짐을 의미
- Figure 5 (right): 정확한 검색 쌍에서 교차 엔트로피 손실 비교
- T-MASS 적용 시 손실 값 감소 → 정렬 성능 향상
Hyperparameter Discussion
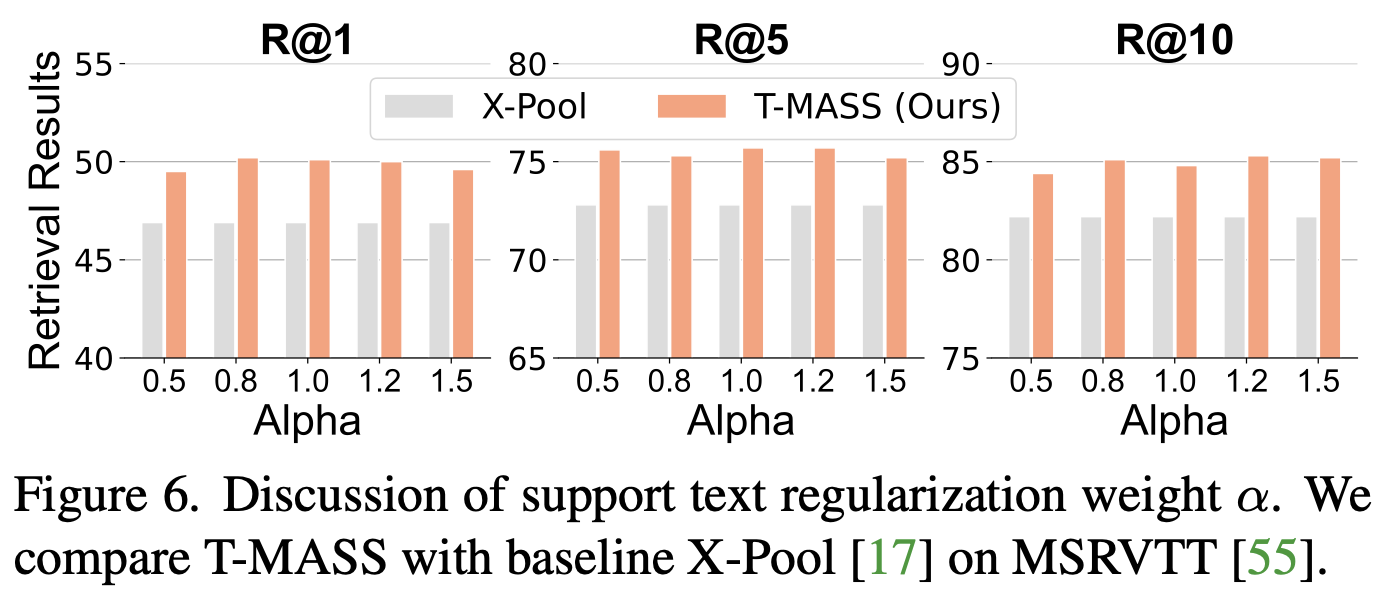
- Support Text Regularization $\alpha$ 에 따른 성능 분석
- 최적 $\alpha$ 값: 1.2
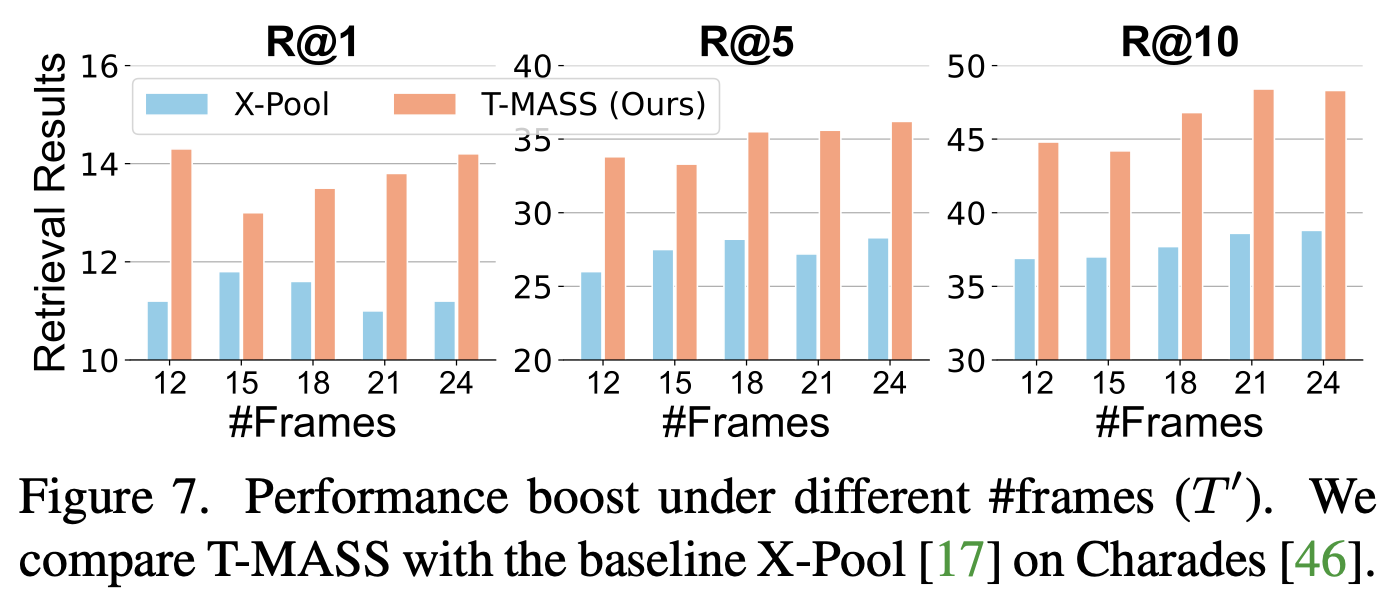
- 프레임 수 $T’$ 에 따른 성능 변화
- 다양한 프레임 수에서도 T-MASS가 X-Pool 대비 높은 성능 유지
4. Conclusion
- T-MASS는 텍스트 임베딩의 표현력을 높여 text-video retrieval 성능을 개선
- 기존 단일 임베딩 방식의 한계를 극복하고, 확률적 표현을 활용하여 보다 정교한 검색 수행 가능
- 다섯 개의 데이터셋에서 SOTA 성능을 달성하며, 특히 R@1 성능에서 최대 6% 향상
- 텍스트 표현의 확장 가능성을 강조하며, 향후 연구에 기여할 수 있는 새로운 패러다임을 제안
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)