






[Paper] [Github]
Oriane Sim´ eoni, Gilles Puy, Huy V. Vo, Simon Roburin, Spyros Gidaris1, Andrei Bursuc, Patrick P´erez, Renaud Marlet and Jean Ponce Valeo.ai | Inria | LIGM | Center for Data Science, New York University
BMVC 2021

Introduction
Object detector는 자율주행 차량과 같은 핵심 시스템에서 중요한 역할을 한다. 하지만 높은 성능을 달성하기 위해서는 대량의 annotated data를 필요로 한다. 이러한 비용을 줄이기 위한 다양한 접근법이 제안되었으며, 예를 들어 semi-supervision, weak supervision, active learning, 그리고 self-supervision 기반의 task fine-tuning 등이 있다.
이 연구에서는 annotation 없이 이미지를 통해 object의 localizing하는 방법을 다룬다. 초기 연구들은 saliency 또는 이미지 내 유사성(intra-image similarity)만을 활용했으나, 이는 정확도가 낮고 제안된 영역이 너무 많아 대규모 데이터셋에는 적합하지 않았다. 일부 접근법은 annotation 없이 extra modalities(e.g., audio, LiDAR) 등을 활용하기도 했다.
이에 대해, 논문에서 unsupervised 방식으로 single 이미지 수준에서 object를 localizing하는 간단한 방법을 제안한다. 이 방법은 이미지 간 유사성을 탐색하지 않기 때문에 선형적인 복잡도를 가지며, 대규모 데이터셋에서도 높은 확장성을 가진다.
Idea
DINO에서 학습된 high-quality features를 활용한다. 구체적으로:
- 이미지를 동일한 크기의 patch로 나눈다.
- DINO 모델을 통해 각 patch의 특징을 추출한다.
- 마지막 attention 레이어에서 key component를 사용하여여 patch 간 유사도를 계산한다.
- 유사한 patch 수가 가장 적은 patch(Seed)를 선택해 object의 일부를 localize한다. 이는 foreground objects의 patch가 background patch보다 상관성이 낮다는 empirical criterion 기반했다.
- 초기 Seed에 대해 유사성이 높은 patch를 추가하며, 이를 Seed 확장(Seed Expansion)이라고 힌다.
- 최종적으로 이 과정을 통해 binary object segmentation mask를 생성하고, 연결된 가장 큰 구성 요소에 대해 bounding box를 추론한다.
Contribution
이 연구는 다음과 같은 주요 성과를 달성했다.
- Self-supervised pre-trained Vision Transformer에서 추출한 feature와 patch 간의 상관관계를 활용하여, region proposals 및 기존의 single-object discovery 방법을 능가하는 성능을 보이는 간단한 single-object localization 방법을 제안했다.
- 제안된 방법론을 활용하여 클래스에 구애받지 않는 (class-agnostic) object detector를 학습시켰으며, 이를 통해 single 이미지에서 multi object를 정확히 detection을 할 수 있었다.
- Detected object를 시각적으로 일관된 클래스로 클러스터링하여 class-aware object detector를 학습시켰다.
- 일부 클러스터는 데이터셋의 라벨된 의미적 클래스와 높은 상관성을 보여, weakly-supervised 학습 수준의 object detection 결과를 달성했다.
이 연구는 비지도 학습의 잠재력을 보여주며, 대규모 데이터셋에 annotation을 달지 않고도 정확한 object detection를 가능하게 한다는 점에서 큰 의미를 갖는다.
Proposed approach
Transformers for Vision
Input
Vision Transformers는 고정 크기의 patch $P \times P$ 시퀀스를 입력으로 사용한다. 색상 이미지 $I$의 공간 크기가 $H \times W$일 때, patch의 개수는 다음과 같이 계산된다.
여기서 각 patch는 $3P^2$ 크기를 가지며, $H$와 $W$는 $P$의 배수라고 가정한다. 각 patch는 학습된 linear projection layer을 통해 $d$-dimension의 embedding space로 mapping된다. 또한, 학습된 벡터인 “class token” $\text{CLS}$가 patch embedding에 추가되어 Transformer의 입력은 $\mathbb{R}^{(N+1) \times d}$에 속하게 된다.
Self-Attention
Transformer는 multi 헤드 self-attention layer와 MLP들로 구성된다. Self-attention layer의 입력 $X \in \mathbb{R}^{(N+1) \times d}$에 대해 다른 linear transformation이 적용되어 query $(Q)$, key$(K)$, value$(V)$를 생성한다.$Q, K, V \in \mathbb{R}^{(N+1) \times d}$
Self-attention 레이어의 출력은 다음과 같이 계산된다.
\[Y = \text{softmax} \left( d^{-1/2} Q K^\top \right) V \in \mathbb{R}^{(N+1) \times d}\]여기서 softmax는 행(row) 단위로 적용됩니다. 단순화를 위해 single head attention 레이어의 경우를 설명했지만, 실제 attention 레이어는 일반적으로 multi-head를 포함한다. 이 연구에서는 Transformer의 마지막 self-attention layer에서 각 헤드의 key, query, value를 concatenate하여 feature representation을 생성한다.
Features for Object Localization
이 연구에서는 DINO로 self-supervised 방식으로 pretrained Transformers를 사용한다. DINO는 마지막 attention 레이어에서 CLS query의 self-attention을 통해 유의미한 object 분할을 얻을 수 있다. 이를 기반으로 ‘DINO-seg’라는 baseline을 구축하여 object detection을 수행한다.
그러나 저자들은 이 방법으로는 self-supervised Transformer features의 potential을 충분히 활용하지 못한다고 판단했다. 이에 따라, 이 연구에서는 patch 간 similarity를 계산하고 이를 활용하여 object를 더 효과적으로 localize하는 새로운 방법인 LOST를 제안한다. LOST는 Transformer의 마지막 레이어에서 추출한 patch key $k_p \in \mathbb{R}^d, \, p = 1, \ldots, N$를 사용하여 single 이미지의 patch 간 유사도를 계산함으로써 작동한다.
Finding objects with LOST
Input LOST는 neural network를 통해 single image에서 추출된 $d$-dimension의 image features $F \in \mathbb{R}^{N \times d}$을 input으로 사용한다. 여기서 $N$은 이미지의 spatial dimension(number of patches), $f_p \in \mathbb{R}^d$는 spatial position $p \in {1, \ldots, N}$에서의 patch feature vector를 의미한다다. 저자들은 이미지에 최소한 하나의 object가 있다고 가정하며, LOST는 입력 특징을 기반으로 이 object들 중 하나를 localizing하려고 한다. 이를 위해, object에 속할 가능성이 높은 patch들을 선택한다. 이 patch들을 Seed라고 부른다.
Initial seed selection LOST의 seed selection은 다음 가정에 기반한다:
- object 내부의 patch들은 서로 높은 상관성을 가지며, 배경 patch와는 낮은 상관성을 가진다.
- Single object는 배경보다 더 적은 영역을 차지한다.
따라서, 이미지에서 상관성이 낮은 patch는 object에 속할 가능성이 더 높다. self-supervised Transformer의 특징을 활용하여 patch 간 상관성을 계산한다. 특히 Transformer의 key 특징을 사용하면, object 내부 patch들이 서로 양의 상관성을 가지지만 배경 patch들과는 음의 상관성을 가지는 경향이 있다는 것을 실험적으로 확인했다.
patch 간 상관성을 계산하기 위해, 이미지당 patch 유사성 그래프 $G$를 생성한다. 이는 binary symmetric adjacency matrix $A \in {0, 1}^{N \times N}$로 표현된다. $A$의 각 원소는 다음과 같이 정의된다:
\[a_{pq} = \begin{cases} 1 & \text{if } f_p^\top f_q \geq 0, \\ 0 & \text{otherwise}. \end{cases}\]즉, patch $p$와 $q$가 양의 상관성을된가질 경우, 두 노드는 연결된다. 초기 seed $p^*$는 가장 낮은 연결도를 가지는 patch로 선택된다:
\[p^* = \underset{p \in \{1, \ldots, N\}}{\arg\min} d_p, \quad d_p = \sum_{q=1}^{N} a_{pq}.\]Figure 2는 네 가지 이미지에서 선택된 seed $p^*$의 예를 보여줍니다. Seed 주변의 상관성이 높은 patch들은 역시 object에 속할 가능성이 높다.

Seed expansion Initial seed가 선택되면, 두 번째 단계에서는 와 상관성이 높은 patch들을 추가로 선택한다. 이는 실험적으로 확인된 object 내부의 픽셀들이 양의 상관성을 가지며 낮은 연결도를 갖는다는 관찰에 기반한다. Seed $p^*$와 양의 상관성을 가지며 연결도가 낮은 patch들을 추가로 선택하여 다음 seed 집합 $S$를 형성한다:
\[S = \{q \mid q \in D_k \text{ and } f_q^\top f_{p^*} \geq 0\}, \quad |D_k| = k.\]여기서 $D_k$는 연결도가 가장 낮은 $k$개의 patch를 나타낸다. 기본적으로 $k$는 100으로 설정된다.
Box extraction 마지막 단계는 seed 집합 $S$와 모든 이미지 특징 간의 비교를 통해 mask $m \in {0, 1}^N$을 생성하는 것이다. Mask의 $q$번째 값은 다음 조건을 만족한다:
\[m_q = \begin{cases} 1 & \text{if } \frac{1}{|S|} \sum_{s \in S} f_q^\top f_s \geq 0, \\ 0 & \text{otherwise}. \end{cases}\]이 mask에서 초기 seed를 포함하는 가장 큰 연결 요소를 선택하고, 이를 감싸는 bounding box를 추출하여 object를 detection한다.

Towards unsupervised object detection
LOST의 정확한 single object localization을 활용하여 human supervision 없이 object detection 모델을 학습할 수 있다. Annotation이 없는 이미지 세트에서 각 이미지에 대해 하나의 bounding box를 생성하고 이를 기반으로 object detector를 학습한다. 이 과정은 두 가지 시나리오로 나뉜다.
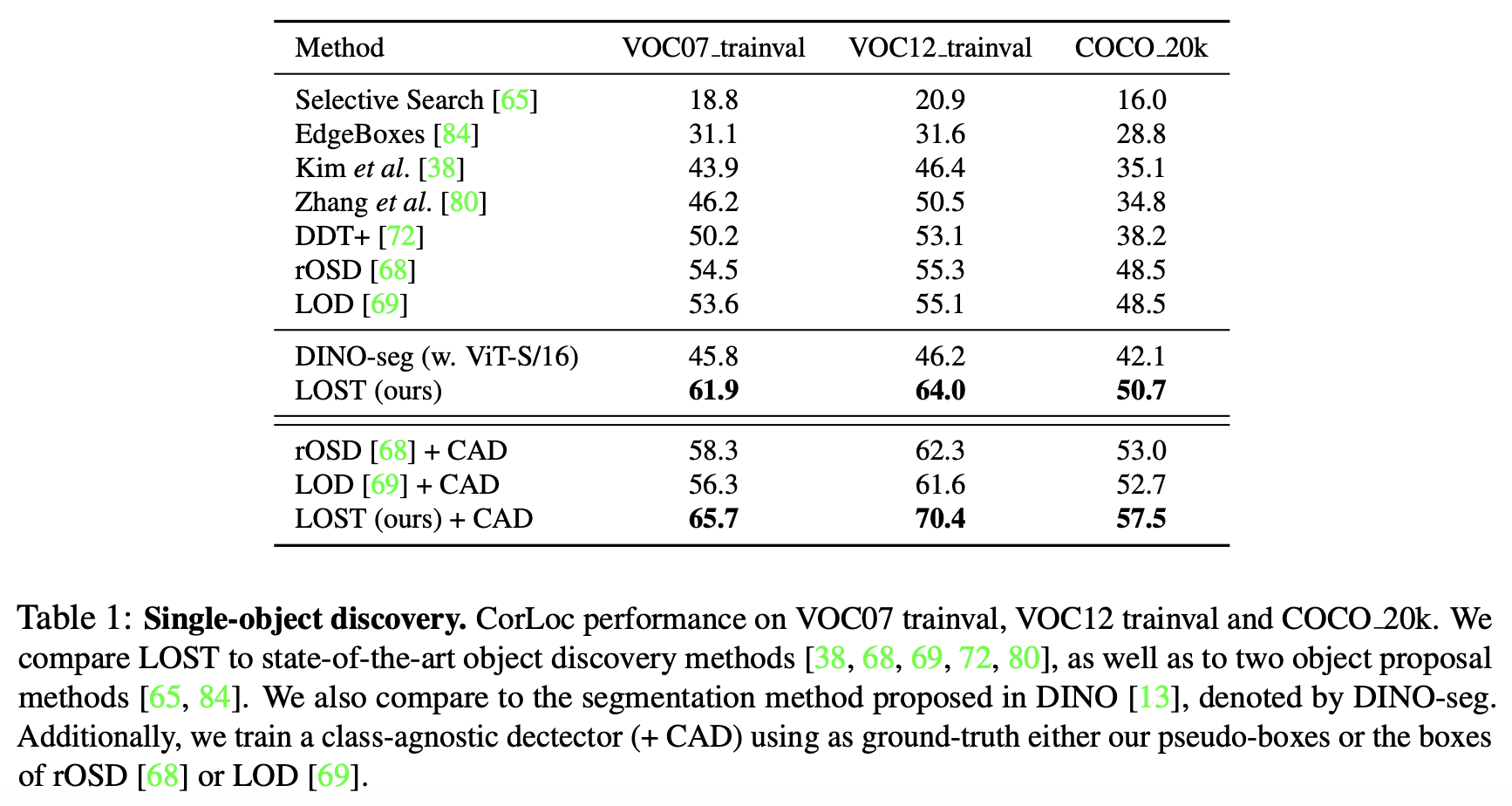
Class-agnostic detection (CAD) Class-agnostic detection model은 object의 의미적 카테고리에 관계없이 주요 object를 localize한다. LOST의 bounding box를 “pseudo-box”로 간주하고, 모든 박스를 동일한 “foreground” 카테고리로 labeling하여 학습한다. 학습된 detector는 single 이미지에서 multi object를 detection할 수 있으며, LOST보다 더 높은 localization 정확도를 보인다.
Class-aware detection (OD) 클래스 인식 detection 모델은 object를 localize하고 의미적 카테고리도 인식한다. 이를 위해 LOST의 pseudo box와 더불어 각 박스의 클래스 레이블이 필요합니다. Fully-unsupervised 방식을 유지하기 위해, K-mean clustering을 활용해 시각적으로 일관된 object 카테고리를 발견한다.
- LOST로 detection한 object를 잘라내어 $224 \times 224$ 크기로 조정한다.
- DINO의 Transformer를 통해 CLS token을 추출한다.
- 이 CLS 토큰들을 K-평균 클러스터링하여 pseudo label을 생성한다.
- 평가 시에는 Hungarian algorithm을 사용하여 psuedo label과 실제 class label을 매칭한다.
Experiments
Experimental Setup
Backbone Networks
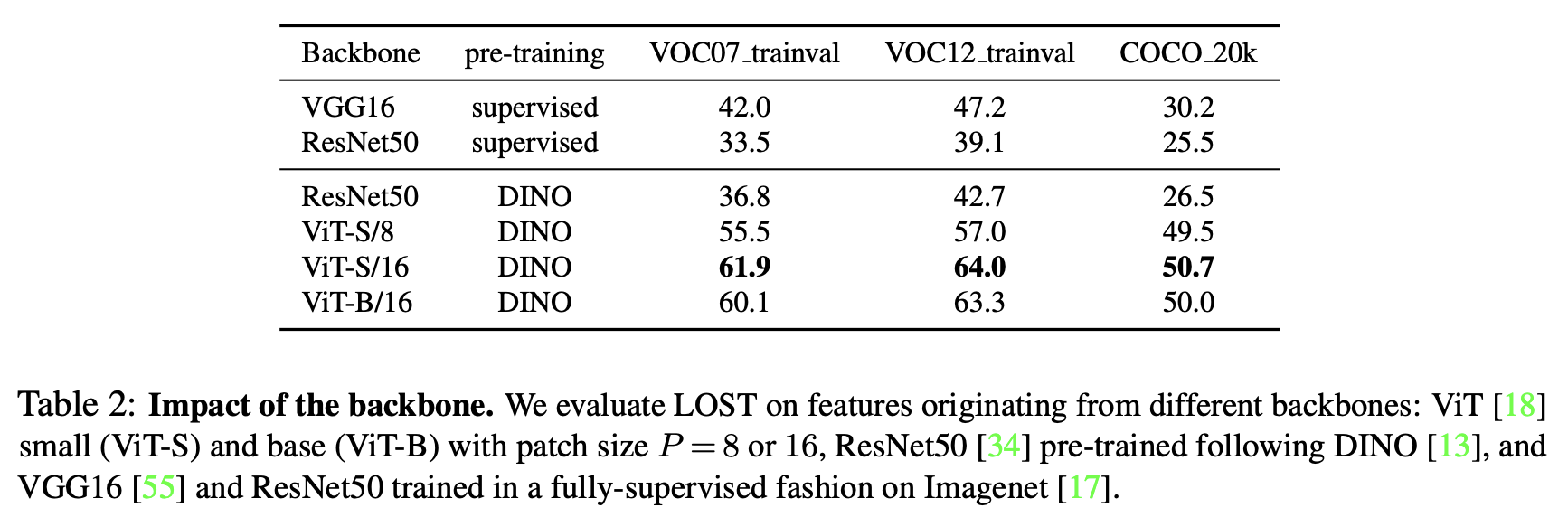
모든 실험에서 기본적으로 ViT-S 모델을 사용하며, 이는 DEiT-S architecture를 따른다. ViT-S는 DINO을 사용해 학습되었으며, patch 크기 $P = 16$로 설정하고 Transformer의 마지막 레이어에서 CLS token에 해당하지 않는 key $K$를 feature $F$로 사용해 최적의 결과를 얻는다.
비교를 위해, ViT-B (base version of ViT), ViT-S $(P = 8)$, ResNet-50 (dilated), VGG16같은 네트워크에서도 실험 결과를 제공했다. 이들 네트워크는 DINO를 사용한 self-supervised 방식 또는 ImageNet을 이용해 supervised 방식으로 학습되었다.
Datasets
이 연구에서 object detector의 localization의 세가지 변형 시나리오 대해 evaluate하기 위해 다음 데이터셋을 사용했다.
- VOC07 trainval+test
- VOC12 trainval
- COCO 20k
COCO 20k는 COCO2014 trainval 데이터셋의 19,817개 랜덤 이미지를 포함하며 벤치마크로 사용되었습니다.
Evaluation Tasks
(1) Single-object Discovery
이미지당 하나의 주요 object localization performance를 evaluate한다. 평가를 위해 CorLoc metric을 사용하며, trainval set에서 결과를 측정합니다. 이는 해당 task가 완전히 unsupervised이기 때문이다.
(2) Class-agnostic Object Detection
객체를 이분하지 않고 foreground/background를 binary로 분류하는 object detection을 evaluate한다. VOC07 trainval, VOC12 trainval, COCO 20k에서 bounding box를 생성하고 class-agnostic detector를 학습하여 ground-truth box와 비교한다.
(3) Class-aware Object Detection
객체의 의미적 클래스까지 인식하는 객체 탐지 문제를 다뤘다. VOC07 trainval/VOC12 trainval에서 box를 생성하고, detector를 학습한 뒤, VOC07 test 세트에서 평가했다. 이는 weakly-supervised object detection과의 비교를 용이하게 한다.
Results
Single-object Discovery
Class-agnostic Detection (CAD)
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)