






OpenAI, 2021. [Paper]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, et al.
OpenAI
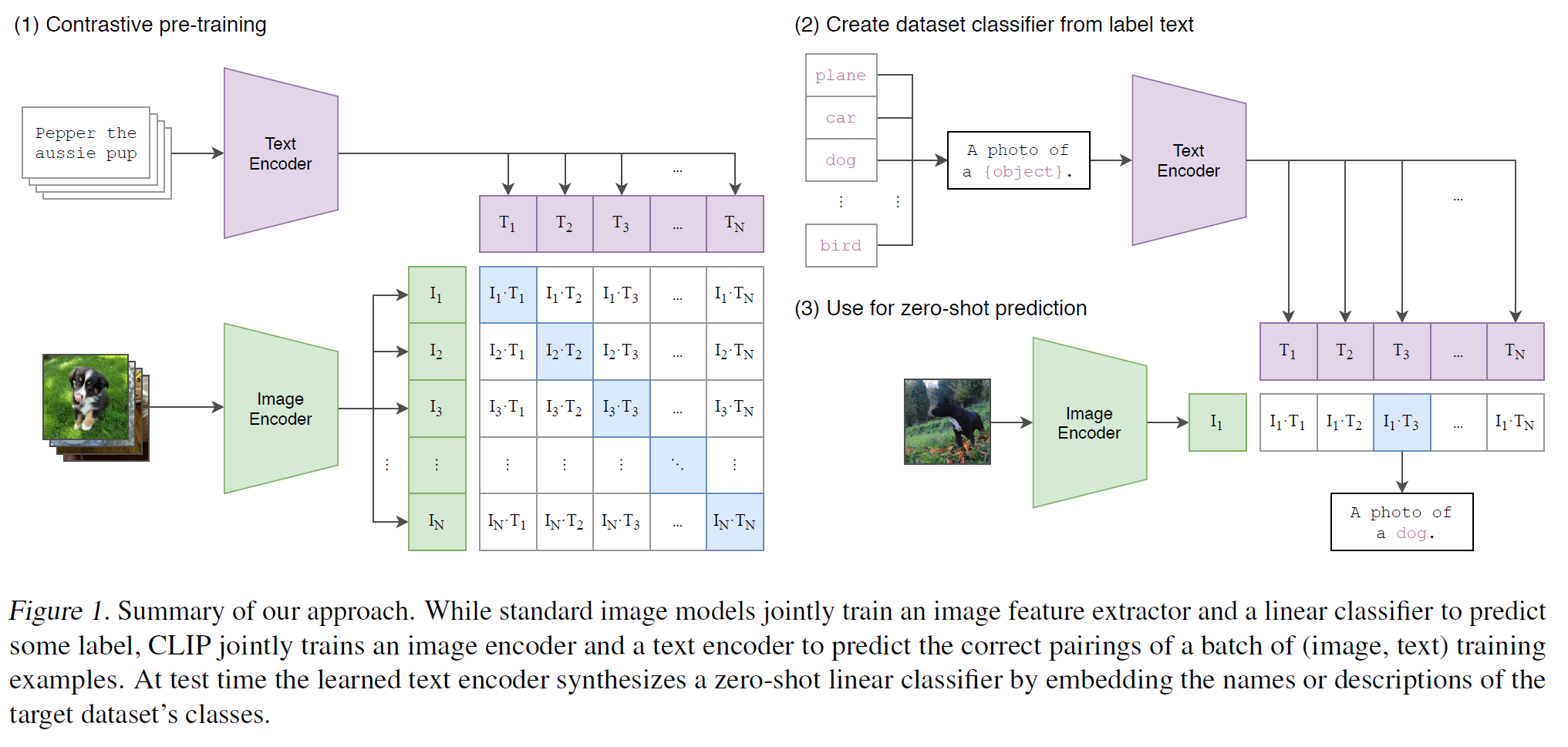
0. Abstract
기존 Computer Vision 모델은 미리 정의된 object categories를 분류하는 방식으로 학습되었으며, 이는 일반화와 확장성 측면에서 한계를 가진다. CLIP은 웹에서 수집한 대규모 (image, text) 데이터셋을 활용하여 학습되었으며, 자연어 supervision을 사용하여 다양한 downstream task에 zero-shot으로 적용할 수 있다. 실험 결과, OCR, action recognition 등 30개 이상의 기존 task에서 우수한 성능을 보였다.
1. Introduction
자연어처리(NLP)에서는 대규모 텍스트 데이터셋을 활용하여 사전학습(pre-training) 후, 이를 다양한 downstream task에 미세조정(fine-tuning)하는 방식이 일반적이다. 그러나, 기존 CNN 기반의 Computer Vision 모델은 zero-shot learning에서 낮은 성능을 보였으며, weakly-supervised learning도 제한적인 성과를 보였다.
CLIP은 4억 개의 이미지-텍스트 쌍을 이용하여 학습되었으며, 자연어 supervision을 통해 보다 효과적으로 representation learning을 수행한다. 이를 통해 다양한 vision task에서 뛰어난 zero-shot 성능을 달성하였다.
2. Approach
2.1. Natural Language Supervision
CLIP은 자연어를 supervision으로 활용하여 학습하며, 기존 image dataset과 달리 번거로운 labeling 작업 없이 대규모 학습이 가능하다. 이를 통해 zero-shot transfer가 가능하며, 다양한 vision task에서 활용할 수 있다.
2.2. Creating a Sufficiently Large Dataset
- 기존 MS-COCO, Visual Genome 등은 품질이 뛰어나지만 데이터 양이 부족하다.
- YFCC100M은 대규모 데이터셋이지만 품질이 일정하지 않다.
- CLIP은 웹에서 수집한 4억 개의 (image, text) 쌍을 포함한 WIT(WebImageText) 데이터셋을 활용하였다.
2.3. Selecting an Efficient Pre-Training Method
- 한 batch는 $N$개의 (image, text) 쌍을 포함하며, $N$개의 positive pair와 $N^2-N$개의 negative pair를 생성한다.
- image와 text를 동일한 embedding space로 변환하고, cosine similarity를 활용하여 positive pair의 유사도를 최대화하고 negative pair의 유사도를 최소화한다.
- Softmax cross-entropy loss를 사용하여 학습한다.

2.4. Choosing and Scaling a Model
- Image Encoder: ResNet-D 및 ViT 사용 (Attention Pooling 적용)
- Text Encoder: Transformer 기반, max_length=76
2.5. Training
- ResNet 기반: ResNet-50, ResNet-101, RN50x4, RN50x16, RN50x64
- ViT 기반: ViT-B/32, ViT-B/16, ViT-L/14
- 32 epochs 학습
3. Experiments
3.1. Zero-Shot Transfer
CLIP은 주어진 이미지와 dataset class 간의 similarity score를 기반으로 zero-shot classification을 수행한다.
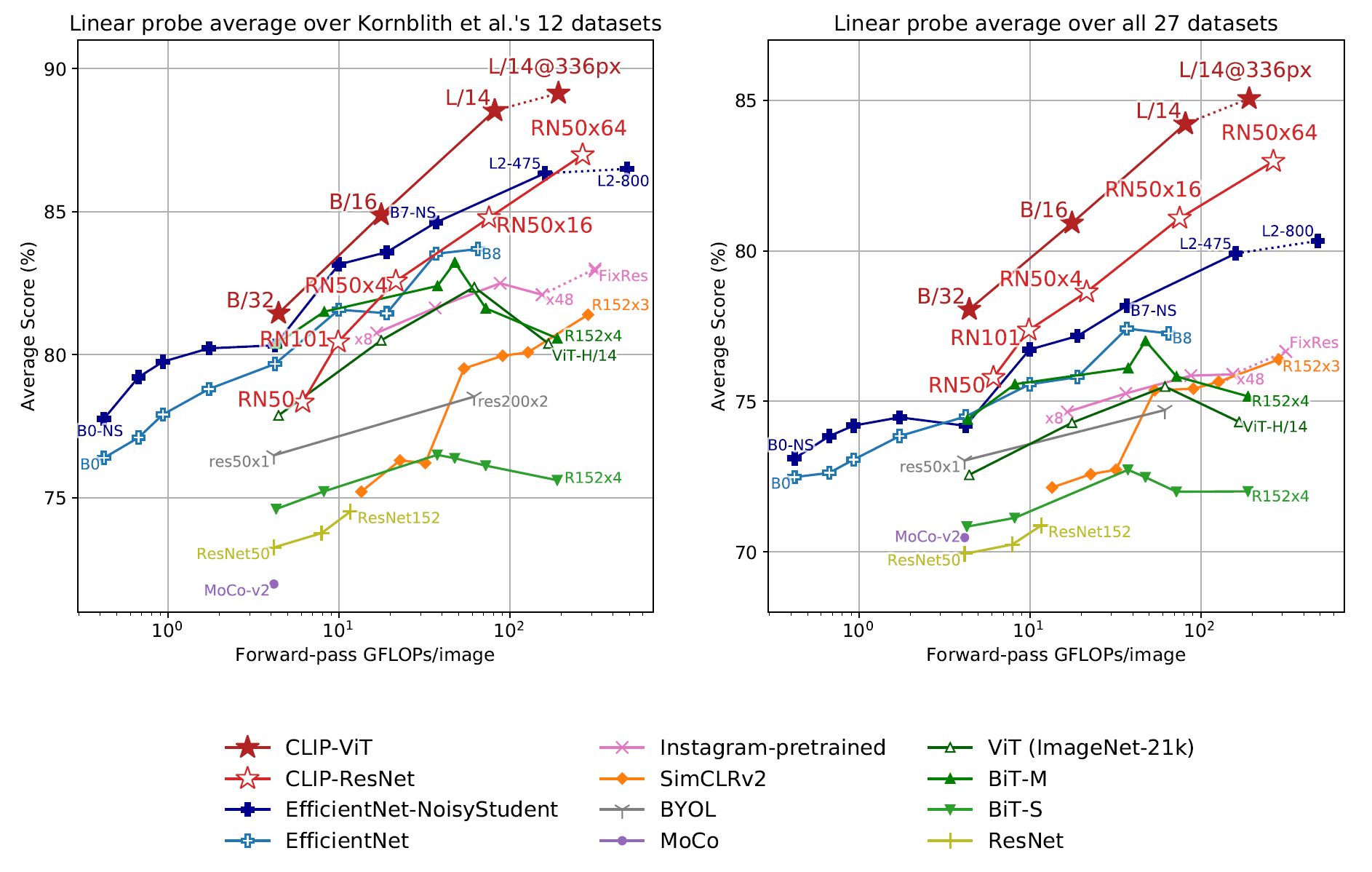
3.2. Representation Learning
CLIP은 image representation을 효과적으로 학습하며, 기존 SOTA 모델과 비교하여 높은 성능을 보인다.
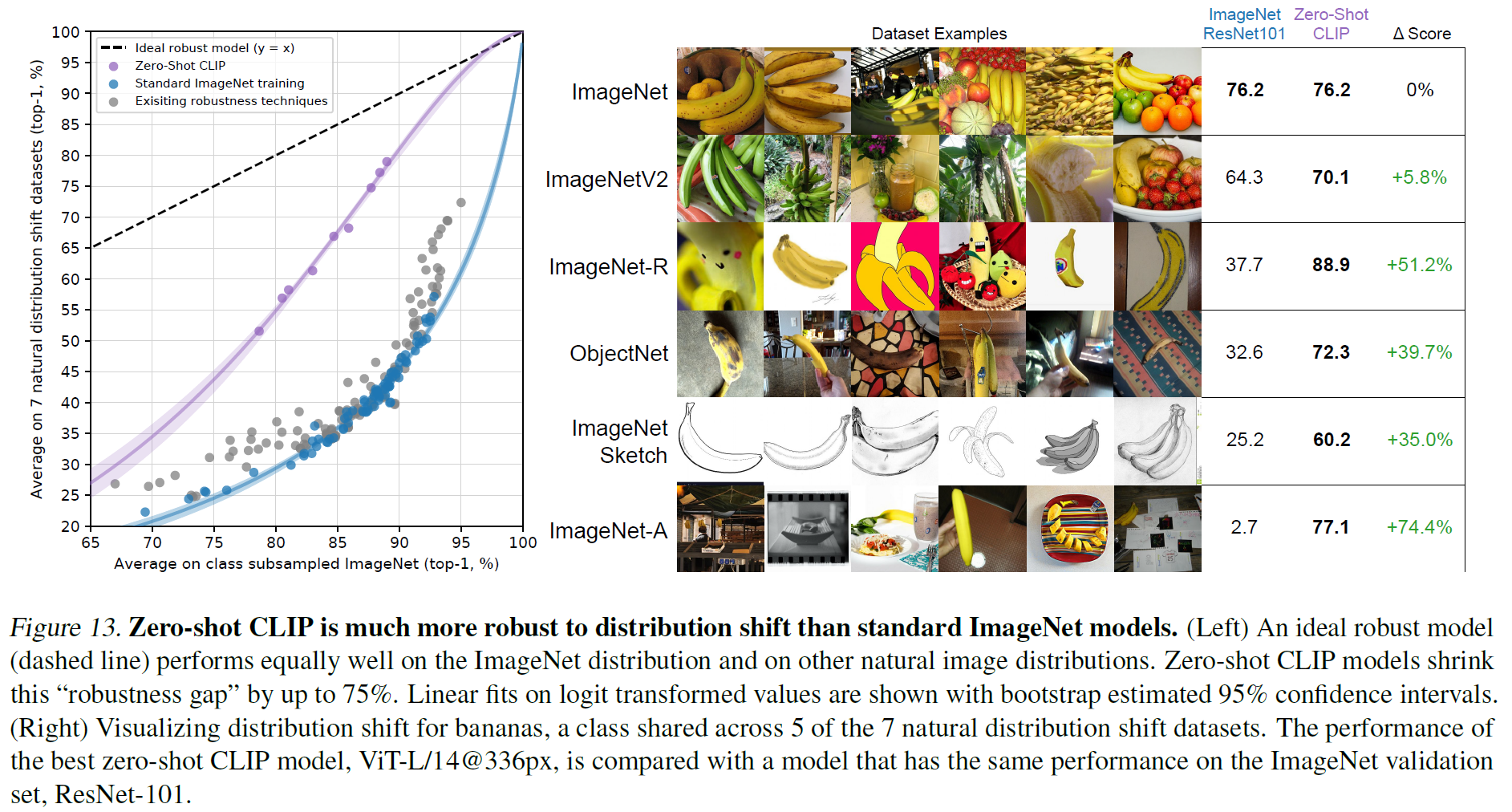
3.3. Robustness to Natural Distribution Shift
CLIP은 다양한 distribution shift 상황에서도 높은 robustness를 유지한다.
4. Limitations
- Zero-shot CLIP은 ResNet-50과 비교하여 높은 성능을 보이지만, SOTA 모델과 비교하면 계산량이 1000배 증가해야 한다.
- 특정 task-specific 모델보다 성능이 낮을 수 있다.
- 모델이 학습 데이터에서 사회적 편향을 그대로 학습할 가능성이 있다.
5. Broader Impacts
5.1. Bias
CLIP은 학습 데이터의 사회적 편향을 반영할 수 있으며, 특정 인구 그룹에 대해 불균형적으로 잘못된 예측을 할 가능성이 있다.
5.2. Surveillance
CLIP은 OCR, 동작 인식, 얼굴 감정 인식 등의 감시(surveillance) 작업에 활용될 가능성이 있으며, 이는 윤리적 문제를 초래할 수 있다.
6. Conclusion
CLIP은 웹에서 수집한 대규모 (image, text) 데이터셋을 활용하여 자연어 supervision 기반의 visual representation 학습을 수행하였다. 이를 통해 다양한 vision task에서 zero-shot transfer가 가능하며, 기존 supervised learning 모델과 비교하여 강력한 generalization 성능을 보였다. 그러나 사회적 편향과 윤리적 문제를 해결하기 위한 추가 연구가 필요하다.
![[Paper review] Self-correcting LLM-controlled Diffusion Models](/assets/images/blog/post-5.jpg)